
字典_复杂表格数据存储_列表和字典综合嵌套
表格数据使用字典和列表存储,并实现访问

字典核心底层原理(***重要***)
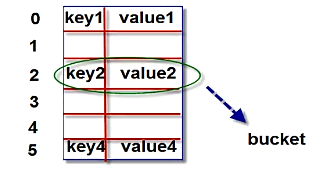
字典对象的核心是散列表。散列表是一个稀疏数组(总是有空白元素的数组),数组的每个单元叫做bucket,每个bucket由两部分:一个是对键对象的引用,一个是对值对象的引用。
由于,所有bucket结构和大小一致,我们可以通过偏移量来读取bucket。
r1 = {'name':'高小一','age':18,'salary':3000,'city':'北京'}
r2 = {'name':'高小二','age':19,'salary':2000,'city':'上海'}
r3 = {'name':'高小三','age':20,'salary':1000,'city':'深圳'}
tb = [r1,r2,r3]
# 获得第二行的人的新资
print(tb[1].get('salary'))
# 打印表中所有的新资
for i in range(len(tb)): # i ——》0,1,2
print(tb[i].get('salary'))
#打印表的所有数据
for i in range(len(tb)):
print(tb[i].get('name'),tb[i].get('age'),tb[i].get('salary'),tb[i].get('city'))
将一个键值对放进字典的底层过程
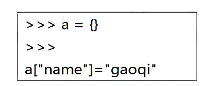
假设字典a对象创建完后,数组的长度为8;
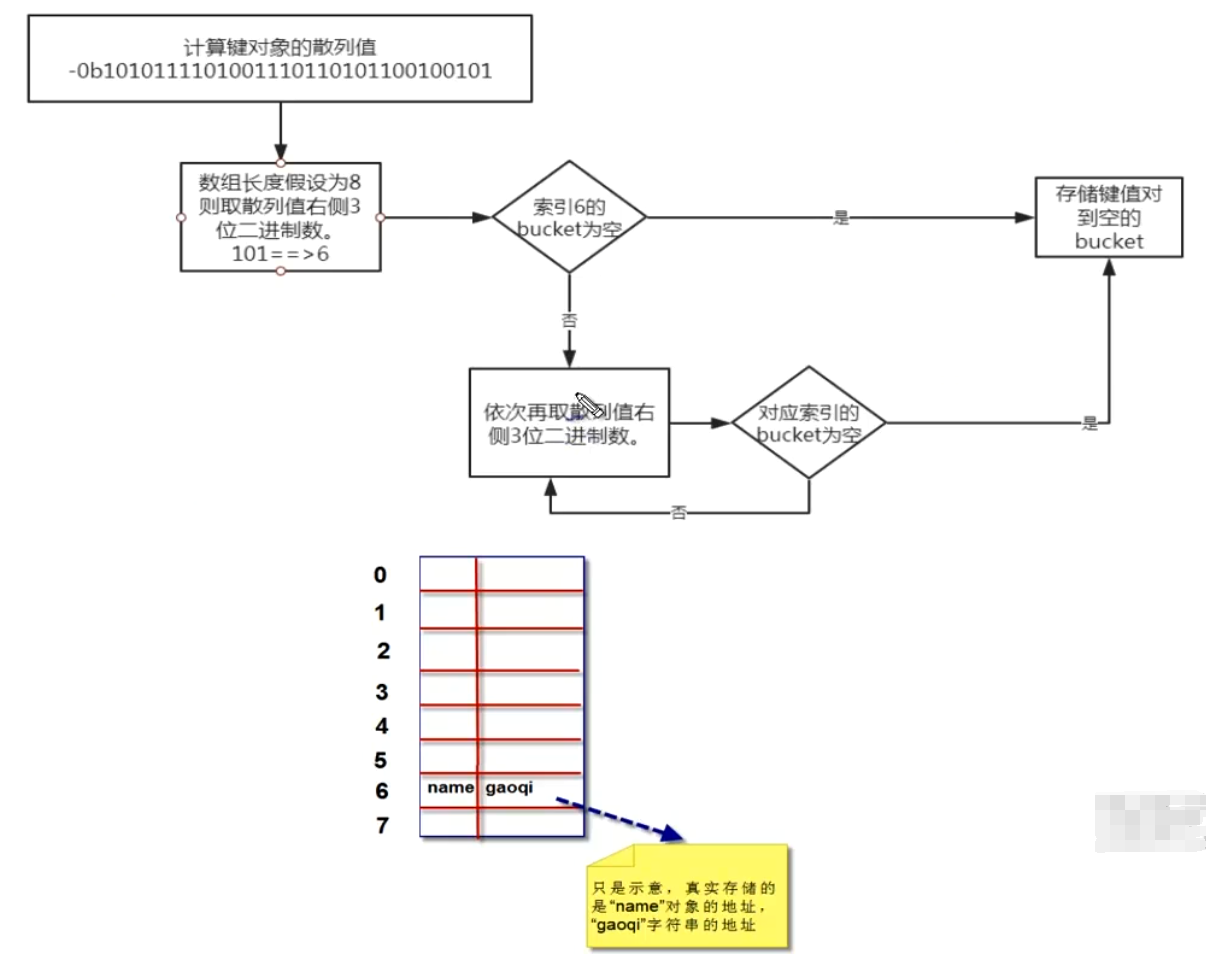
我们要把 ‘name’ = ‘king’ 这个键值对放到字典a对象中,首先第一步需要计算 键 ‘name’ 的散列值。python中可以通过hash()计算。

由于数组长度为8,我们可以拿计算出的散列值的最右边3位数字作为偏移量,即'101',十进制是数字5.我们查看偏移量5,对应的bucket是否为空。如果为空,则将键值对放进去,如果不为空,则依次取右边3位作为偏移量,即‘100’,十进制是数字4,在查看偏移量为4的bucket是否为空。直到找到为空的bucket将键值对放进去。流程图如下:
扩容:
python会根据散列表的拥挤程度扩容。‘扩容’指的是:创造更大的数组,将原有内容拷贝到新数组中。接近2/3,数组就会扩容

 浙公网安备 33010602011771号
浙公网安备 33010602011771号