
基于DeepLab v3的遥感图像语义分割教程
基于DeepLab v3的遥感图像语义分割教程
前言
前两个月做过一次基于Unet的遥感图像语义分割教程,效果较差。这次选用一个稍微新一点的模型,再跑一次相同的数据集,加上迁移学习的技巧,看看效果怎么样。
教程准备
-
开源的图像语义分割DeepLabv3代码(二分类)
-
DeepLabv3+基本原理(借鉴)
核心代码
-
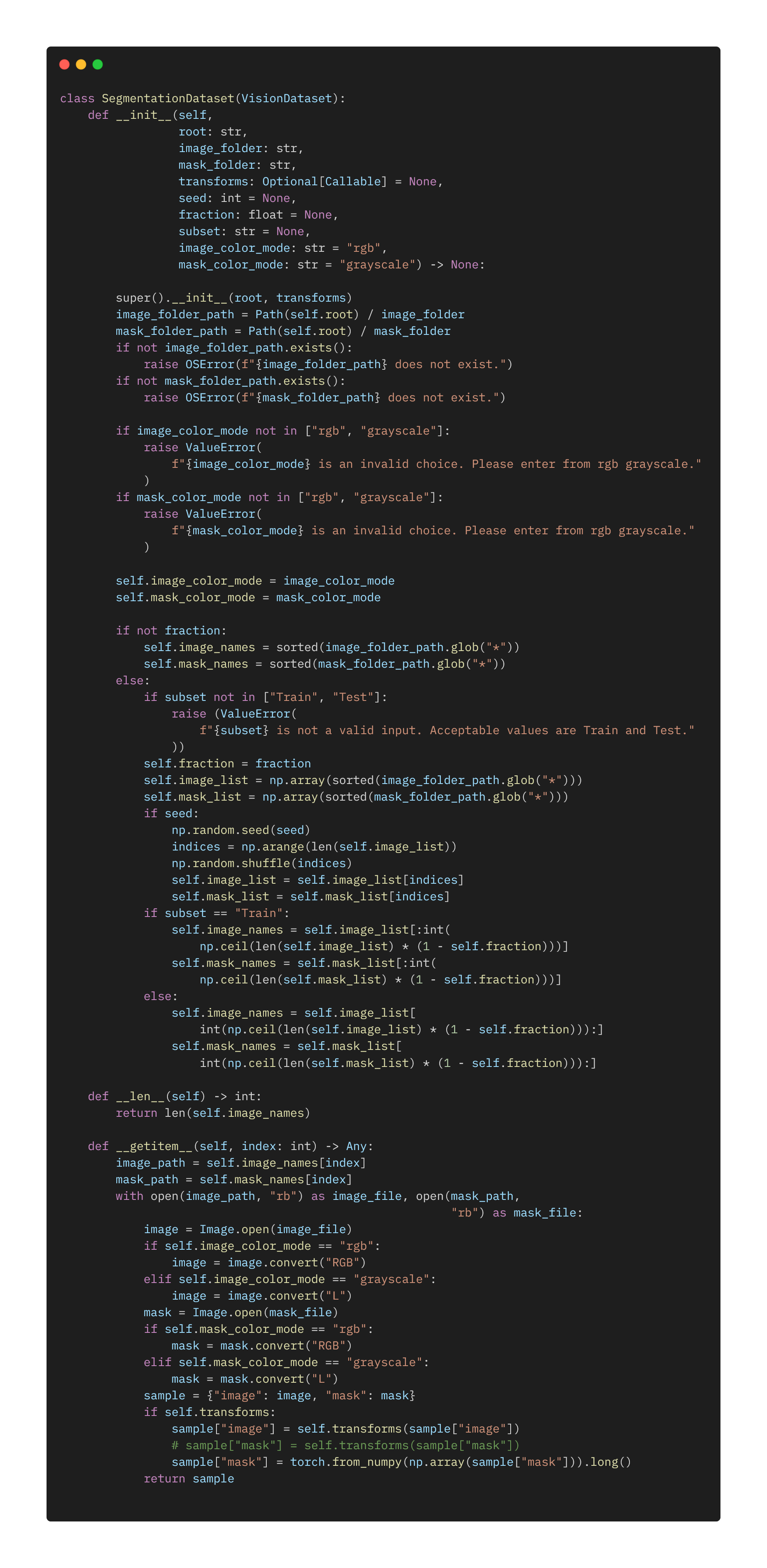
dataloader
数据读取部分,最值得注意的就是images和labels的数据格式,文件读取的方法倒是次要的,千篇一律。这里我们读取的图像依旧是上次的数据集,images是(3 X 256 X 256)的RGB图像,labels是0、1、2、3...7的单通道灰度图(256 X 256),记得读取的时候用GRAY_SCALE模式。
数据的预处理部分,将images数据集做归一化处理(也可再加上标准差处理),转化成0~1的tensor;将labels转化成long型,这里设置long是因为后面的损失函数CrossEntropyLoss需要标签是Long的格式,如果用MSELoss的损失函数,那么用float格式,数据大小范围不做调整,转换成tensor即可。
-
model(transfer learning)
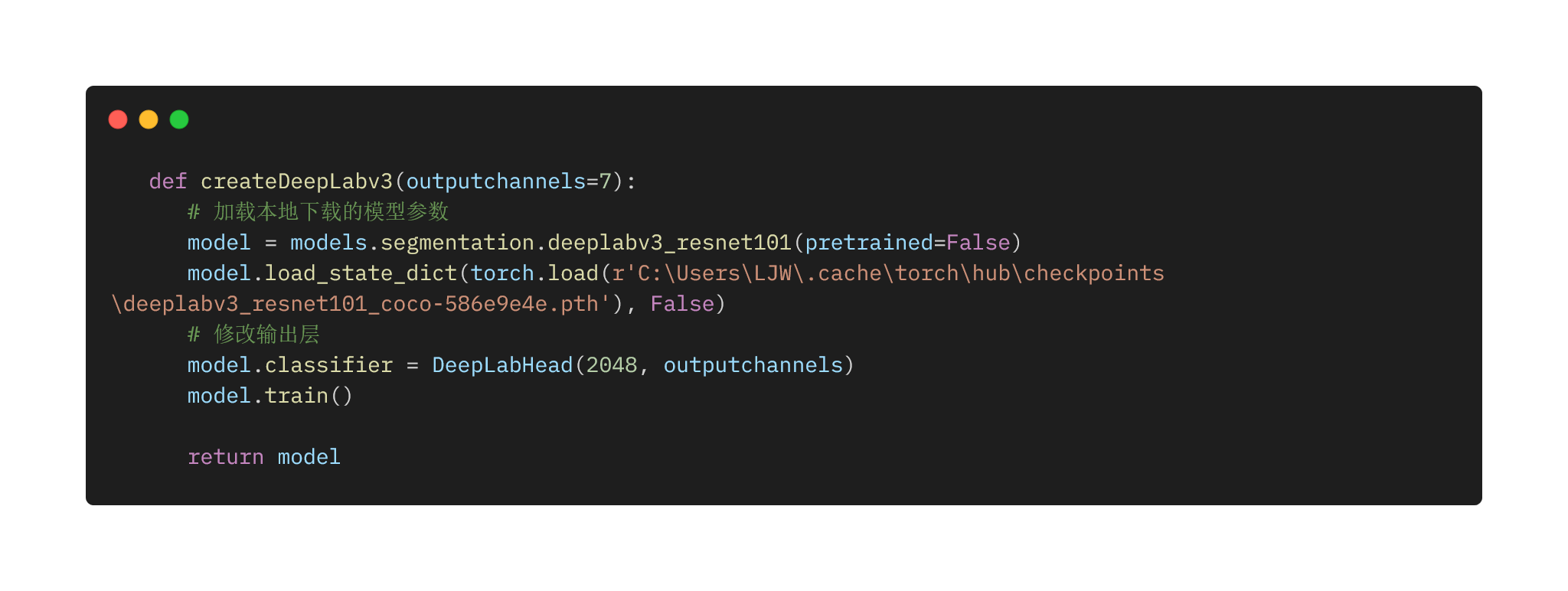
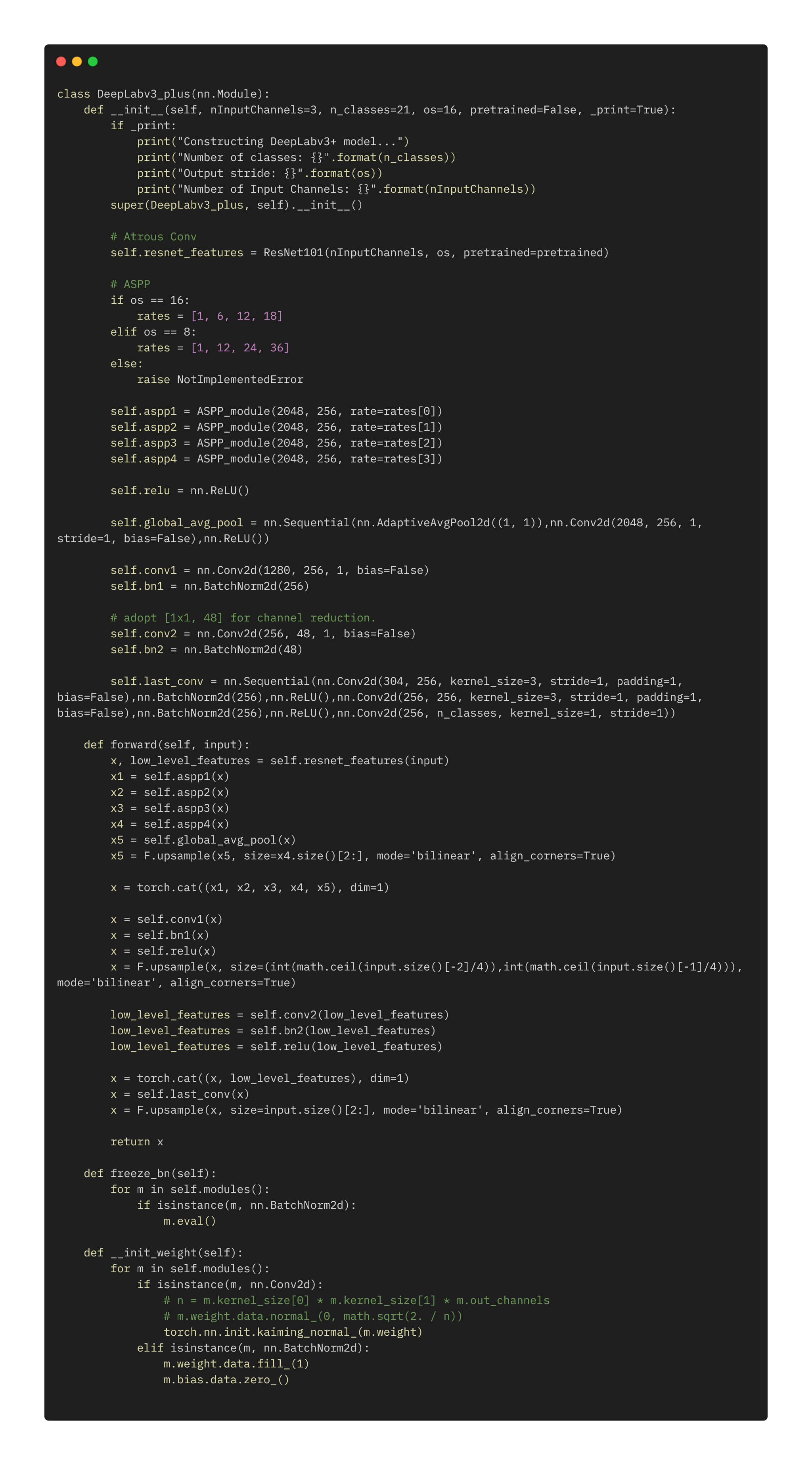
model用的是DeepLab v3模型,backbone是Resnet101模型。在此基础上进行迁移学习,可以得到更好的效果。下面给出了DeepLab v3+模型的源码,与v3大同小异,网络结构本人不做解释。加载完Resnet101模型的参数后,替换最后一层为新的outputchannels。
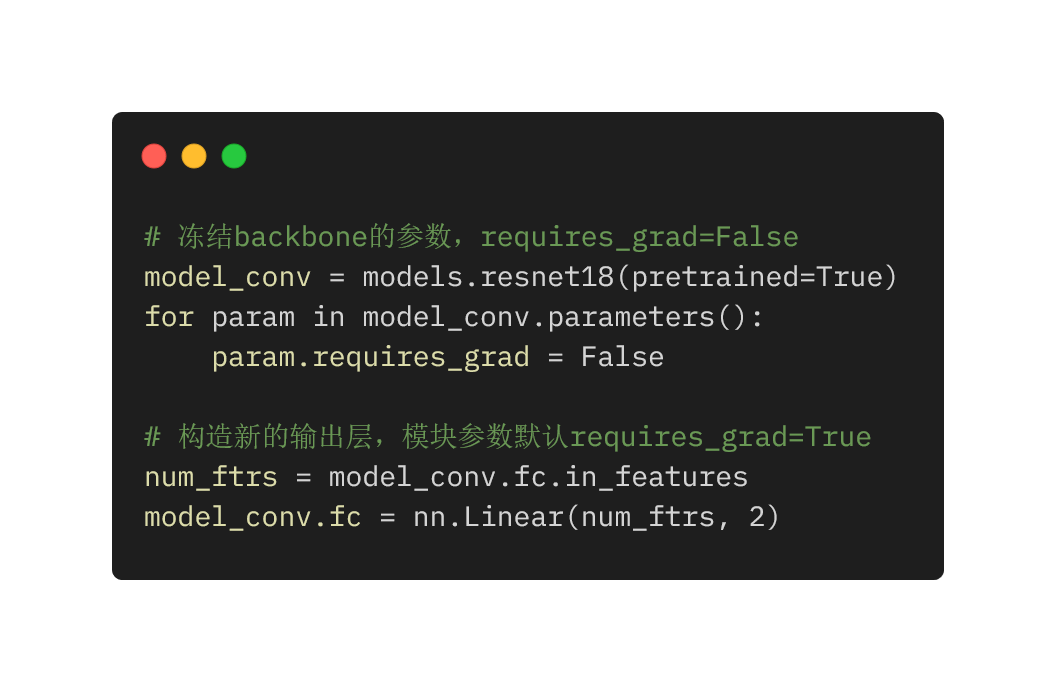
常用迁移学习代码:
-
Training
这里的重点主要是看模型输出的数据维度。可以看到outputs['out']是没有经过概率化的数组,数组的维度是(batchsize X category X height X width),而label的维度是(batchsize X height X width)。在损失函数为nn.CrossEntropyLoss()的情况下,label的维度中不需要category的1维,如果有的话进行sequeeze;损失函数为nn.MSELoss的情况下,label的维度是(batchsize X 1 X height X width)。每次epoch结束,保存该过程中最好的模型参数。
![]()
这里有点疑问:nn.CrossEntropyLoss对样本做了概率化处理再计算损失;那么nn.MSELoss呢?这个是不是二分类、多分类都可以用,是不是也对样本做了概率化处理呢?
-
choose cost func/optimizer
除了前述的损失函数之外,这里还需要定义优化器。此外还有两个计算指标,f1_score和accuracy_score,其中accuracy_score用来计算多类别预测中成功的百分比,roc_auc_score是二分类中使用的指标,这些方法源于sklearn.metrics。

结果
10个epoch下的结果...用的训练集,还是不咋地。

指标变化图

预测类型分布
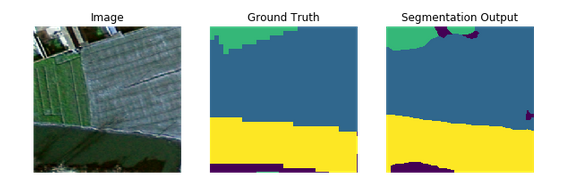
结果对比
后记
-
nn.MSELoss需要了解了解,弄清楚这些损失函数做的计算处理和要求输入的数组维度。
-
这里用了f1_score和auccracy_score两个指标。只看了后者的,前者没关心。
-
click库输入参数的方法看起来比
argparse.ArgumentParser()还简单。 -
一般来说,还需要调整epochs/batchsize/lr/gamma来调参。
-
6G显存不够啊,想换新显卡了。
-
有空介绍一下时间序列分析(RNN、LSTM)相关的模型,ConvLSTM这类图像时序模型看起来挺有意思的,看看能不能找到源码吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号