

前程无忧职位信息爬取
前程无忧(51job)职位信息爬取
前言
毕业季,求职是首要任务。于是找到了前程无忧,爬取一些职位信息以供选择。
步骤
1. 网址URL解码
我们看到的URL是信息(职位、城市、日期...)编码之后的结果,浏览器帮我们进行了编码和读取URL。为了实现更为完全的自动化,这里对前程无忧的网址URL进行了分析和编码。
如下,020000,000000,0000,00是城市编码,代表上海。parse.urlencode({'job_type': '计算机'})对职位也进行了编码。此外还可以输入日期、半径等筛选信息。
编码规则参考自:https://blog.csdn.net/m0_38052500/article/details/88683041
from urllib import parse
rs = parse.urlencode({'job_type': '计算机'})
for i in range(1, 10):
# 020000,000000,0000,00是城市编码,代表上海
url = 'https://search.51job.com/list/020000,000000,0000,00,9,99,{},2,{}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='.format(rs.split('=')[-1], str(i))
2. 信息爬取
2.1 爬取外层页面信息
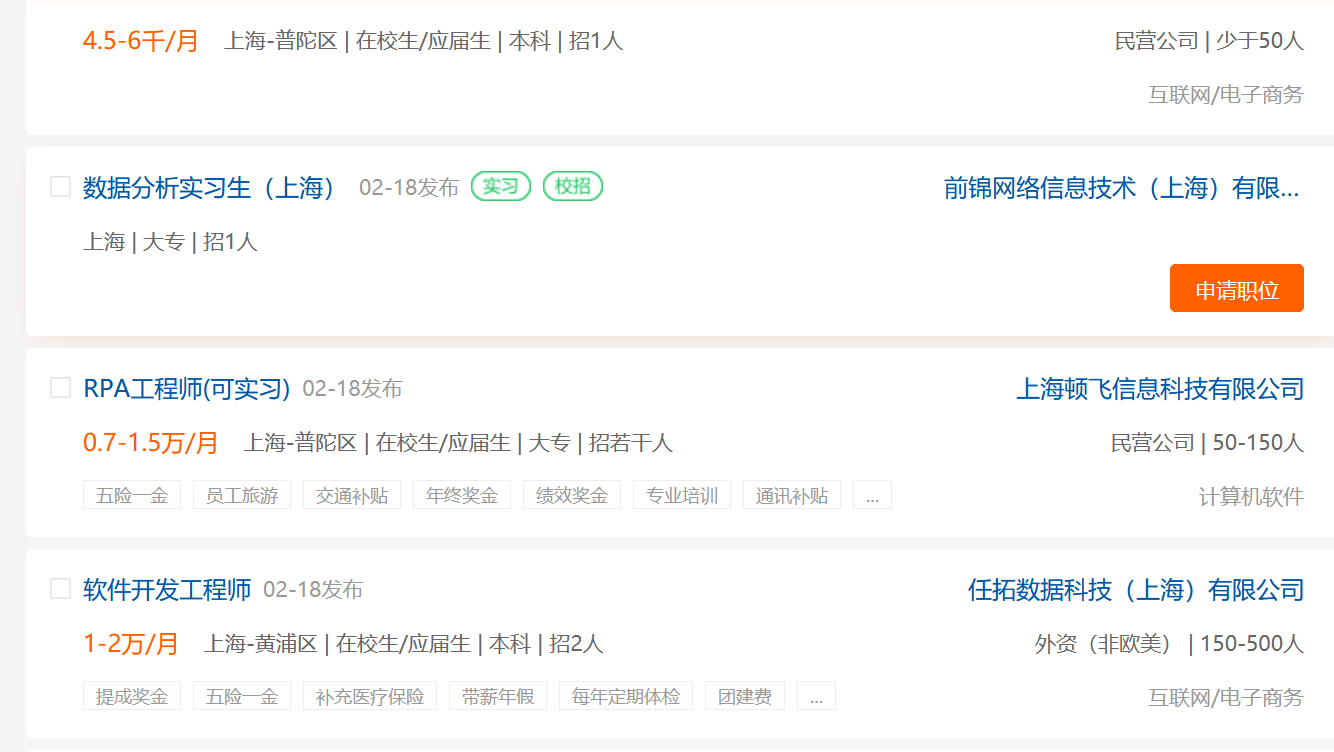
首先对页面中所有查询到的职位信息进行爬取。分析后发现所有信息都通过一个script进行传输。于是我们用正则表达式定位到这里,获取到json数据,转存为dict。
/* html文本 */
<script type="text/javascript">
window.__SEARCH_RESULT__ = {"top_ads":[],"auction_ads":[],...}
<script>
'''
@desc: 爬取并解析json
'''
response = requests.get(url=url, headers=headers)
text = response.text
inforNeeded = re.findall("window.__SEARCH_RESULT__ = (.*)</script", text)
info = eval(list(inforNeeded)[0])
result = info['engine_search_result'] # 定位到json字符串
然后对基本信息进行逐一读取。这里有瑕疵:有的文本里的标签span/p/u...没有消除掉,暂时不解决。
for i in range(len(result)):
currentResult = result[i]
companyName = currentResult['company_name']
certificate = currentResult['attribute_text']
certificate = " ".join(certificate)
jobHref = str(currentResult['job_href'])
jobHref = jobHref.replace('\\', '')
...
2.2 爬取职位详细信息
通过爬取基础信息,我们读取到了每一个职位详细信息的URL链接,即job_href。接着对每个职位逐一发起请求,爬取该职位的详细要求。最后用dict存储每次的数据,写入到xls里。
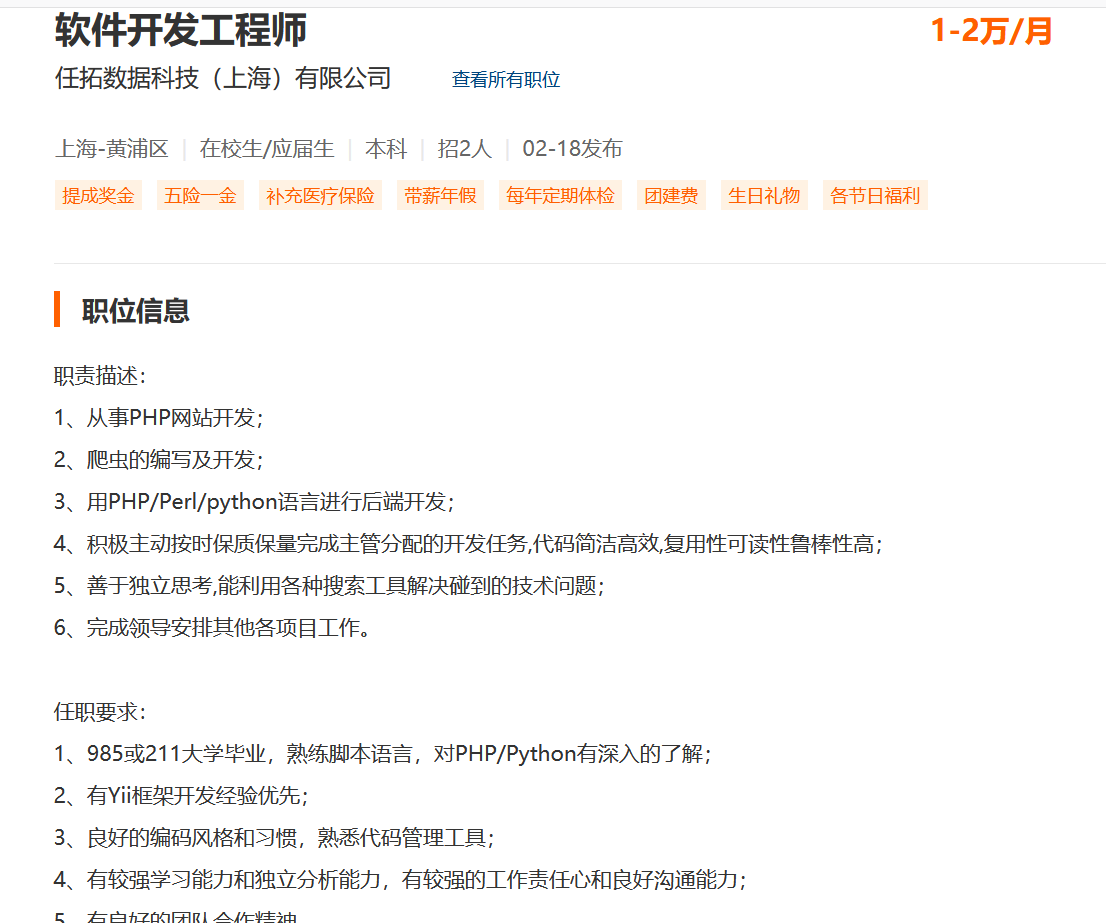
response = requests.get(url=jobHref, headers=headers)
response.encoding = 'gbk' # 网站文本解码
content = response.text
soup = BeautifulSoup(content, 'lxml')
requirement = soup.find_all('div', class_='bmsg job_msg inbox')
requirementInfo = re.findall('<p>(.*?)</p>', str(requirement)) # re匹配到所有段落(职位要求)
requirementInfo = " ".join(requirementInfo)
res_item = {
'公司名称': companyName,
'要求': certificate,
'公司链接': companyHref,
'工作链接': jobHref,
'公司规模': companySize,
'公司类型': companyType,
'薪水': companySalary,
'福利': companyWelf,
'工作地点区号': workArea,
'工作地点': workText ,
'更新日期': updateDate,
'公司类型文本': companyindText,
'工作年限': workYear,
'职位': jobName,
'职位要求': requirementInfo,
'联系方式': phoneInfo,
'公司详细信息': companyInfo,
'专业要求': pro3
}
3. main
最后逐一运行各个函数,完成爬取。
if __name__ == '__main__':
'''
@desc: change ip
'''
# proxy_lists = getiplists(50) #爬取ip地址,存到list
# proxies = [{
# 'http': item,
# 'https': item,
# } for item in proxy_lists]
# proxie = random.choice(proxies)
searchJob = '爬虫'
wb = Workbook()
ws = wb.create_sheet("sheet1", 0)
ws.append(['公司名称', '职位', '薪水', '专业要求','福利','工作地点','职位要求','公司规模',
'公司类型文本','公司类型','公司链接','工作链接','联系方式','要求','公司详细信息',
'更新日期','工作年限'])
# 查询工作名称编码
rs = parse.urlencode({'job_type': searchJob})
res_list = []
for i in range(1, 4):
# 020000,000000,0000,00是城市编码,代表上海
url = 'https://search.51job.com/list/020000,000000,0000,00,9,99,{},2,{}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='.format(rs.split('=')[-1], str(i))
res_item = getJobInfo(url)
res_list.append(res_item)
print("第%s页爬取完毕"%(i))
wb.save("E:/Tablefile/51job.xlsx")
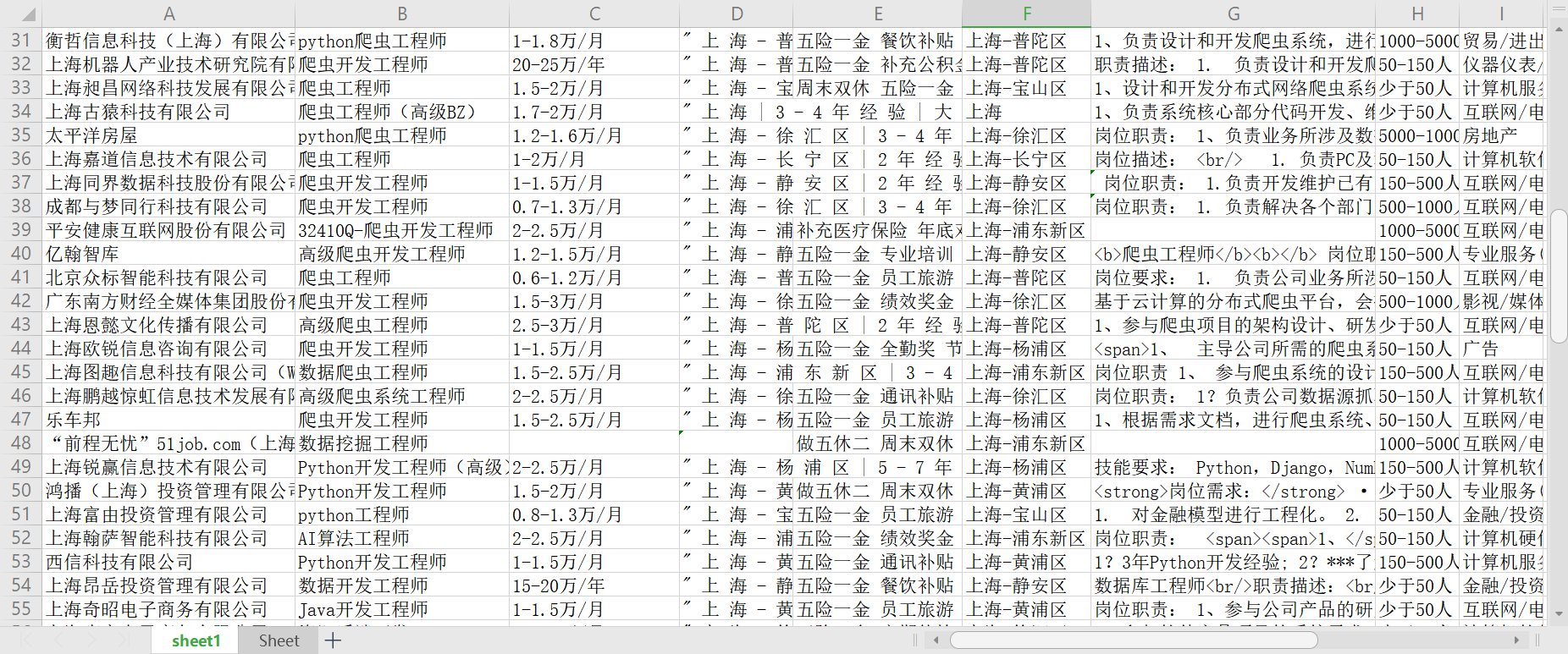
结语
-
相比数据清洗而言,爬取还是很容易实现的。数据清洗更考验pandas/re/...等库的熟练运用,不可忽视。
-
IP池可以视情况考虑加不加。
-
看起来网页的爬虫基本掌握了,下一步可以尝试用fiddler去抓包,爬取一些app上的数据了。
