


58同城房价爬取与可视化
58同城房价爬取与可视化
前言
很久之前爬过一次58同城,最近整理文档的时候发现之前的代码已经过时了,于是整理一下,记录下来。毕竟爬虫这玩意一不用就容易忘。
与先前的差别
先前的网站中房屋的总价、均价等数字信息都是加密传输的,还需要用特殊的方法进行解码匹配,才能解析出真值;而现在的网站已经取消了这一点,所需要的文本信息可以直接从静态的html中解析出来。
技术路线
-
构建IP代理池
与之前一样,需要构建IP代理池用于爬取,目前所有的代理IP都是从http://www.xiladaili.com/gaoni中爬取而来。不同点在于
proxie = random.choice(proxies),现在随机读取代理IP发起请求,取代了先前逐一读取的方式。def getiplists(page_num): #爬取ip地址存到列表,爬取pages页 proxy_list = [] for page in range(20, page_num): url = "http://www.xiladaili.com/gaoni/"+str(page) r = requests.get(url, headers=headers) soup = BeautifulSoup(r.text, 'lxml') ips = soup.findAll('tr') for x in range(5, len(ips)): ip = ips[x] tds = ip.findAll("td") #找到td标签 ip_temp = 'http://' + str(tds[0].contents[0]) proxy_list.append(ip_temp) proxy_list = set(proxy_list) #去重 proxy_list = list(proxy_list) print('已爬取到'+ str(len(proxy_list)) + '个ip地址') return proxy_list if __name__ == '__main__': proxy_lists = getiplists(50) #爬取ip地址,存到list proxies = [{ 'http': item, 'https': item, } for item in proxy_lists] proxie = random.choice(proxies) -
bs4解析html
def get_info(page_url, page_num, proxies): response = requests.get(url=page_url, headers=headers, proxies=proxies) return response.text, response.status_code def parse_pages(pages): num = 0 soup = BeautifulSoup(pages, 'lxml') # 查找到包含所有租房的li标签 all_house = soup.find_all('div', class_="property-content") for house in all_house: # 楼盘标题 res1 = house.find('p', class_="property-content-info-comm-name") title = res1.contents # 地区 res2 = house.find('p', class_='property-content-info-comm-address') loca = res2.text # 距离地铁地址 res3 = house.find('div', class_='property-extra-wrap') address = res3.text # 总价和均价 res41 = house.find('div', class_='property-price') price = res41.text # 户型 res4 = house.find('p', class_='property-content-info-text property-content-info-attribute') huxing = res4.text num += 1 print('第' + str(num) + '条数据爬取完毕,暂停3秒!') time.sleep(2) # 地理编码 lon, lat = geocode2lonlat(str(loca)) ws.append([" ".join(title), loca, address, price.split(' ')[0] + price.split(' ')[1], price.split(' ')[2], huxing, lon, lat])通过
bs4读取html,调用find_all/find方法查询信息,较为简单。RegExp:顺便又熟悉了一下RegExp,正则表达式无论是在效率还是在精确度上都比bs4/etree等要强很多。
https://blog.csdn.net/weixin_40136018/article/details/81183504#comments_13006281
https://blog.csdn.net/weixin_40136018/article/details/81193361
re.match() # match是从字符串的起点开始做匹配 re.search() # 从字符串做任意匹配 re.find() # 只匹配第一个子串 re.findall() # 以列表的形式返回能匹配的子串,常用 re.finditer() # 返回可迭代对象 -
地理编码
补充了地理编码的功能,地点=>经纬度的解析。采用的是高德地图的API。
def geocode2lonlat(location): ''' @desc:地理编码 ''' key = '...' base = 'https://restapi.amap.com/v3/geocode/geo' parameters = {'address': location, 'key': key, 'city':'上海'} response = requests.get(base, parameters) answer = response.json() try: pos = answer['geocodes'][0]['location'] pos = pos.split(',') lon = pos[0] lat = pos[1] except: lon = '' lat = '' print('fail \n') return lon, lat -
重新执行循环中出错的那一次
使用try-except语句,except中考虑到IP失效时get请求失败的应对方法,即随机更换IP。在更换完IP后继续执行本次循环,而不是跳出到下一次。
for i in range(7, 15): while True: #如果continue开启下一次循环,重新执行循环中出错的那一次;运行成功则break跳出while proxie = random.choice(proxies) try: url = "https://sh.58.com/ershoufang/sub/l60/p" + str(i) + "/" pro_pages, statusCode = get_info(url, i, proxies=proxie) print(statusCode) if '访问过于频繁,本次访问做以下验证码校验' not in pro_pages: parse_pages(pro_pages) print('第' + str(i) + '页数据爬取完毕!') time.sleep(random.randint(3, 10)) print('所有数据爬取完毕!') else: print("请验证网页!") except: # 不行换下一个ip地址 print('请求失败,当前IP已失效,请更换IP节点') continue break参考自
# coding: utf-8 li = [1,2,3,4,5] for num in li: while True: try: # do something except some error: continue break -
folium实现热力图可视化
# -*- coding: utf-8 -*- import numpy as np import folium import pandas as pd import webbrowser from folium.plugins import HeatMap posi = pd.read_excel("E:/Tablefile/58.xlsx") num = 60 lat = np.array(posi["纬度"][0:num]) lon = np.array(posi["经度"][0:num]) price = np.array([float(val[:-3]) for val in posi["均价"]]) data = [[lat[i],lon[i],price[i]] for i in range(num)] map_osm = folium.Map(location=[35,110], zoom_start=5) map_osm.add_child(folium.LatLngPopup()) HeatMap(data).add_to(map_osm) map_osm.save(file_path) webbrowser.open(file_path)
结果展示
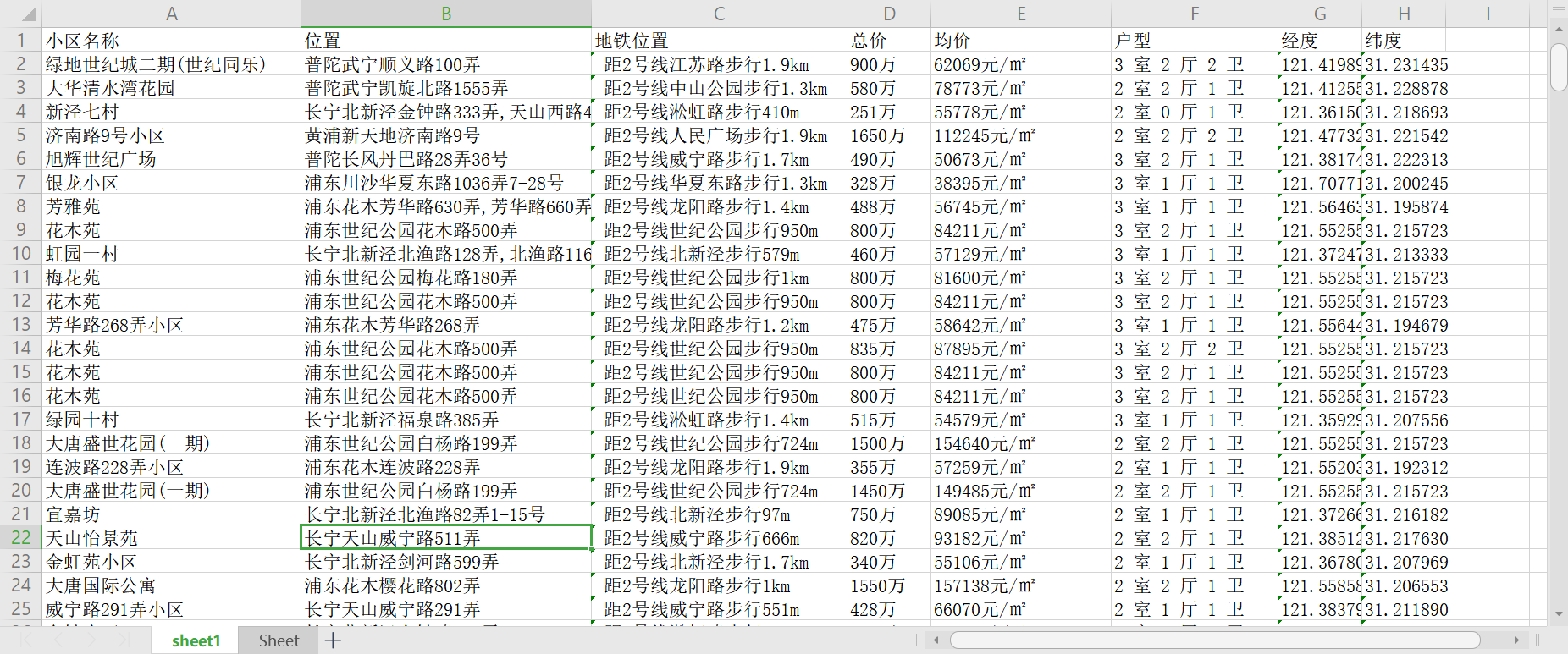
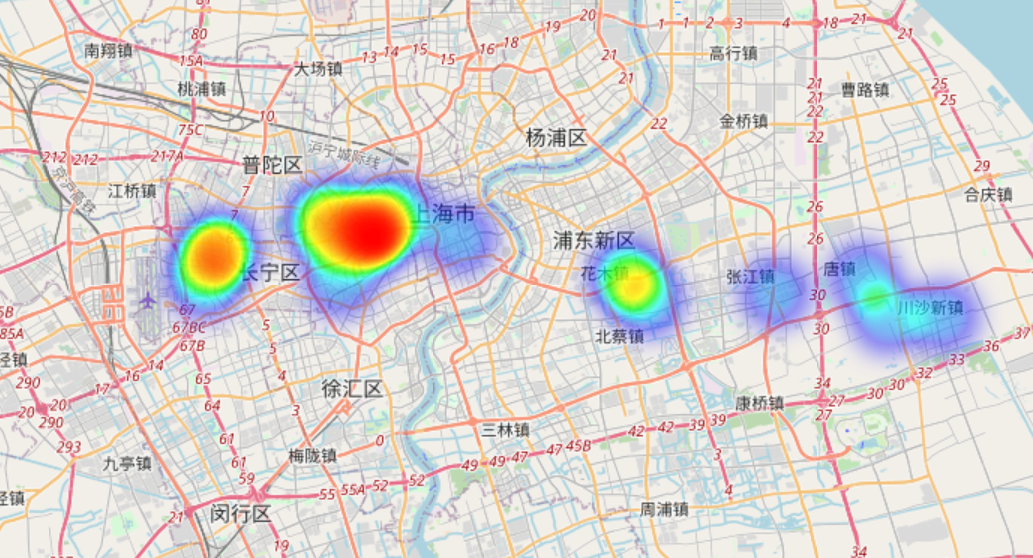
后记
- regExp正则表达式很重要,需要熟练运用。
- 免费代理的IP还是不怎么靠谱。
- 数据的写入可以用
pandas的to_csv/read_csv/read_xls方法,也可以用openpyxl实现。 - 重新执行循环中出错的那一次的思路挺有意思。

