
遥感图像多类别语义分割(基于Pytorch-Unet)
遥感图像多类别语义分割(基于Pytorch-Unet)
前言
去年前就对这方面感兴趣了,但是当时只实现了二分类的语义分割,对多类别的语义分割没有研究。这一块,目前还是挺热门的,从FCN到Unet到deeplabv3+,模型也是不断更迭。
思路
- 首先复现了
FCN(VOC2012)的语义分割代码,大概了解了布局。 - 然后对二分类的代码进行了修改(基于
Pytorch-Unet)
核心代码与步骤讲解
-
dataloader读取
import torch.utils.data as data import PIL.Image as Image import os import numpy as np import torch def make_dataset(root1, root2): ''' @func: 读取数据,存入列表 @root1: src路径 @root2: label路径 ''' imgs = [] #遍历文件夹,添加图片和标签图片路径到列表 for i in range(650, 811): img = os.path.join(root1, "%s.png" % i) mask = os.path.join(root2, "%s.png" % i) imgs.append((img, mask)) return imgs class LiverDataset(data.Dataset): ''' @root1 @root2 @transform: 对src做归一化和标准差处理, 数据最后转换成tensor @target_transform: 不做处理, label为0/1/2/3(long型)..., 数据最后转换成tensor ''' def __init__(self, root1, root2, transform=None, target_transform=None): imgs = make_dataset(root1, root2) self.imgs = imgs self.transform = transform self.target_transform = target_transform def __getitem__(self, index): x_path, y_path = self.imgs[index] img_x = Image.open(x_path) img_y = Image.open(y_path) if self.transform is not None: img_x = self.transform(img_x) if self.target_transform is not None: img_y = self.target_transform(img_y) else: img_y = np.array(img_y) # PIL -> ndarry img_y = torch.from_numpy(img_y).long() return img_x, img_y def __len__(self): return len(self.imgs)这一步里至关重要的就是
transform部分。当src是rgb图片,label是0、1、2...单通道灰度图类型(一个值代表一个类别)时。src做归一化和标准差处理,可以提升运算效率和准确性。label则不做处理,转换成long就好。- Unet模型搭建
import torch.nn as nn import torch from torch import autograd class DoubleConv(nn.Module): def __init__(self, in_ch, out_ch): super(DoubleConv, self).__init__() self.conv = nn.Sequential( nn.Conv2d(in_ch, out_ch, 3, padding=1), nn.BatchNorm2d(out_ch), nn.ReLU(inplace=True), nn.Conv2d(out_ch, out_ch, 3, padding=1), nn.BatchNorm2d(out_ch), nn.ReLU(inplace=True) ) def forward(self, input): return self.conv(input) class Unet(nn.Module): def __init__(self, in_ch, out_ch): super(Unet, self).__init__() self.conv1 = DoubleConv(in_ch, 64) self.pool1 = nn.MaxPool2d(2) self.conv2 = DoubleConv(64, 128) self.pool2 = nn.MaxPool2d(2) self.conv3 = DoubleConv(128, 256) self.pool3 = nn.MaxPool2d(2) self.conv4 = DoubleConv(256, 512) self.pool4 = nn.MaxPool2d(2) self.conv5 = DoubleConv(512, 1024) self.up6 = nn.ConvTranspose2d(1024, 512, 2, stride=2) self.conv6 = DoubleConv(1024, 512) self.up7 = nn.ConvTranspose2d(512, 256, 2, stride=2) self.conv7 = DoubleConv(512, 256) self.up8 = nn.ConvTranspose2d(256, 128, 2, stride=2) self.conv8 = DoubleConv(256, 128) self.up9 = nn.ConvTranspose2d(128, 64, 2, stride=2) self.conv9 = DoubleConv(128, 64) self.conv10 = nn.Conv2d(64, out_ch, 1) def forward(self, x): c1 = self.conv1(x) p1 = self.pool1(c1) c2 = self.conv2(p1) p2 = self.pool2(c2) c3 = self.conv3(p2) p3 = self.pool3(c3) c4 = self.conv4(p3) p4 = self.pool4(c4) c5 = self.conv5(p4) up_6 = self.up6(c5) merge6 = torch.cat([up_6, c4], dim=1) c6 = self.conv6(merge6) up_7 = self.up7(c6) merge7 = torch.cat([up_7, c3], dim=1) c7 = self.conv7(merge7) up_8 = self.up8(c7) merge8 = torch.cat([up_8, c2], dim=1) c8 = self.conv8(merge8) up_9 = self.up9(c8) merge9 = torch.cat([up_9, c1], dim=1) c9 = self.conv9(merge9) c10 = self.conv10(c9) return c10-
务必注意,多标签分类输出不做概率化处理(
softmax)。原因是后面会用nn.CrossEntropyLoss()计算loss,该函数会自动将net()的输出做softmax以及log和nllloss()运算。 -
然而,当二分类的时候,如果计算损失用的是
nn.BCELoss(),由于该函数并未做概率化处理,所以需要单独运算sigmoid,通常会在Unet模型的末尾输出。 -
train & test
这段比较重要,拆成几段来讲。
最重要的是
nn.CrossEntropyLoss(outputs, label)的输入参数outputs: net()输出的结果,在多分类中是没有概率化的值。label: dataloader读取的标签,此处是单通道灰度数组(0/1/2/3...)。这里
CrossEntropyLoss函数对outputs做softmax + log + nllloss()处理;
对label做one-hot encoded(转换成多维度的0/1矩阵数组,再参与运算)。
# 1. train def train_model(model, criterion, optimizer, dataload, num_epochs=5): for epoch in range(num_epochs): print('Epoch {}/{}'.format(epoch, num_epochs-1)) print('-' * 10) dt_size = len(dataload.dataset) epoch_loss = 0 step = 0 for x, y in dataload: step += 1 inputs = x.to(device) labels = y.to(device) optimizer.zero_grad() outputs = model(inputs) # 可视化输出, 用于debug # probs1 = F.softmax(outputs, dim=1) # 1 7 256 256 # probs = torch.argmax(probs1, dim=1) # 1 1 256 256 # print(0 in probs) # print(1 in probs) # print(2 in probs) # print(3 in probs) # print(4 in probs) # print(5 in probs) # print(probs.max()) # print(probs.min()) # print(probs) # print("\n") # print(labels.max()) # print(labels.min()) # labels 1X256X256 # outputs 1X7X256X256 loss = criterion(outputs, labels) # crossentropyloss时outputs会自动softmax,不需要手动计算 / 之前bceloss计算sigmoid是因为bceloss不包含sigmoid函数,需要自行添加 loss.backward() optimizer.step() epoch_loss += loss.item() print("%d/%d,train_loss:%0.3f" % (step, (dt_size - 1) // dataload.batch_size + 1, loss.item())) print("epoch %d loss:%0.3f" % (epoch, epoch_loss)) torch.save(model.state_dict(), 'weights_%d.pth' % epoch) return model def train(): model = Unet(3, 7).to(device) batch_size = args.batch_size criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters()) liver_dataset = LiverDataset("data/多分类/src", "data/多分类/label", transform=x_transforms, target_transform=y_transforms) dataloaders = DataLoader(liver_dataset, batch_size=batch_size, shuffle=True, num_workers=1) train_model(model, criterion, optimizer, dataloaders)# 2. transform使用pytorch内置函数 x_transforms = transforms.Compose([ transforms.ToTensor(), # -> [0,1] transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) ]) y_transforms = None # label不做处理# 3.test,输出结果可视化 def test(): model = Unet(3, 7) model.load_state_dict(torch.load(args.ckp, map_location='cpu')) liver_dataset = LiverDataset("data/多分类/src", "data/多分类/label", transform=x_transforms, target_transform=y_transforms) dataloaders = DataLoader(liver_dataset, batch_size=1) model.eval() import matplotlib.pyplot as plt plt.ion() k = 0 with torch.no_grad(): for x, _ in dataloaders: y = model(x) # 将网络输出的数值转换成概率化数组,再取较大值对应的Index,最后去除第一维维度 y = F.softmax(y, dim=1) # 1 7 256 256 y = torch.argmax(y, dim=1) # 1 1 256 256 y = torch.squeeze(y).numpy() # 256 256 plt.imshow(y) # debug print(y.max()) print(y.min()) print("\n") skimage.io.imsave('E:/Tablefile/u_net_liver-master_multipleLabels/savetest/{}.jpg'.format(k), y) plt.pause(0.1) k = k+1 plt.show()
需要注意的地方
-
损失函数的选取。
二分类用BCELoss;多分类用CrossEntropyLoss。
BCELoss没有做概率化运算(sigmoid)
CrossEntropyLoss做了
softmax + log + nllloss -
transform
src图片做归一化和均值/标准差处理
label不做处理(单通道数组,0/1/2/3...数值代表类别)
-
预测结果不好有可能是loss计算错误的问题,也可能是数据集标注的不够好
-
注意计算loss之前的squeeze()函数,用于去掉冗余的维度,使得数组是loss函数需要的shape。(注:BCELoss与CrossEntropy对label的shape要求不同)
-
二分类在预测时,net()输出先做sigmoid()概率化处理,然后大于0.5为1,小于0.5为0。
结果展示
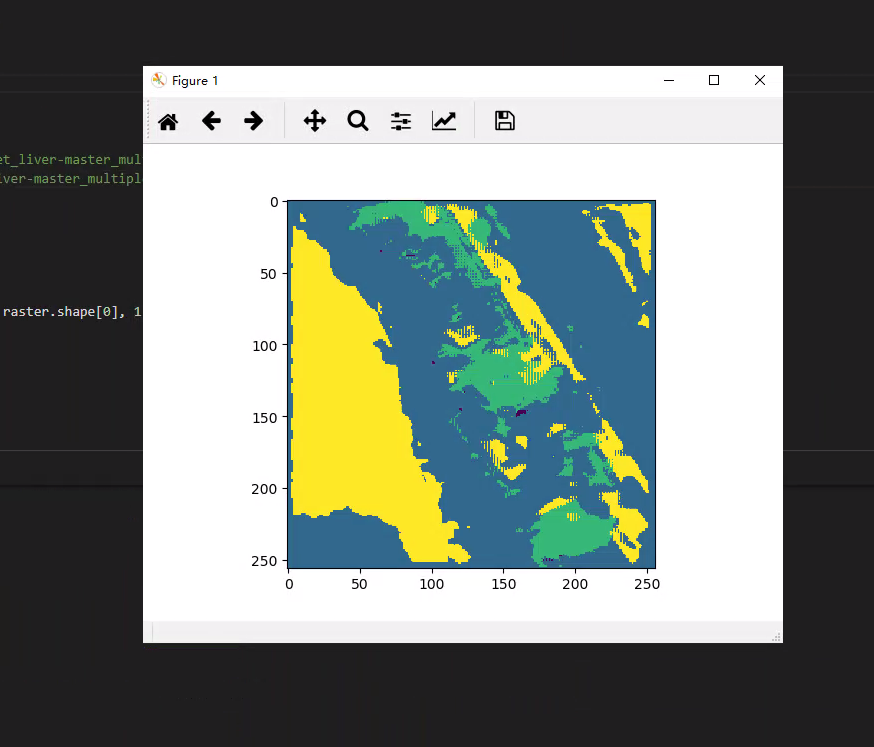
后记
-
还需多复现几个语义分割模型(deeplabv3+/segnet/fcn.../unet+)
-
理解模型架构卷积、池化、正则化的具体含义
-
掌握调参的技巧(优化器、学习率等)
-
掌握迁移学习的方法,节省运算时长

 浙公网安备 33010602011771号
浙公网安备 33010602011771号