


LSTM时间序列预测模型
LSTM时间序列预测模型
-
长短期记忆(long short-term memory,LSTM)。本节将基于pytorch建立一个LSTM模型,以用于航班乘客数据的预测,这里将直接按照代码块进行解释。
https://stackabuse.com/time-series-prediction-using-lstm-with-pytorch-in-python/
-
数据的预处理
#时间序列预测模型LSTM import torch import torch.nn as nn import seaborn as sns #读取seaborn的数据文件,需要ladder import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.preprocessing import MinMaxScaler flight_data = sns.load_dataset("flights") #print(flight_data.head()) all_data = flight_data['passengers'].values.astype(float) #一共144行数据,这里设置每12个数据为一个间隔(1年为12月) #任务是根据前132个月来预测最近12个月内旅行的乘客人数。请记住,我们有144个月的记录,这意味着前132个月的数据将用于训练我们的LSTM模型,而模型性能将使用最近12个月的值进行评估。 #最后待验证的数据集(月份数目)大小,数值可以修改,记得修改最后plot对应的x范围即可 test_data_size = 12 train_data = all_data[:-test_data_size] #训练数据 test_data = all_data[-test_data_size:] #测试数据 #归一化处理减小误差 scaler = MinMaxScaler(feature_range=(-1,1)) train_data_normalized = scaler.fit_transform(train_data.reshape(-1,1)) train_data_normalized = torch.FloatTensor(train_data_normalized).view(-1) #重点 创建读取的数据列表。 #每组数据有2个元组。前一个元组有12个月份的数据,后一个元组只有一个元素,表示第13个月份的数据,用于和基于前12个数据预测的数据求loss def create_inout_sequences(input_data, tw): inout_seq = [] L = len(input_data) for i in range(L-tw): #L-tw = 144-32 = 132个数据 train_seq = input_data[i:i+tw] #12个数据一组,进行训练 train_label = input_data[i+tw:i+tw+1] #第12+1个数据作为label计算loss inout_seq.append((train_seq, train_label)) return inout_seq #这是每次训练的数据(月份数目),设置为12个月,可以进行调整 train_window = 12 #tw,设置训练输入的序列长度为12 train_inout_seq = create_inout_sequences(train_data_normalized, train_window)数据集结果如下
train_inout_seq[:5] [(tensor([-0.9648, -0.9385, -0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341, -1.0000, -0.9385]), tensor([-0.9516])), (tensor([-0.9385, -0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341, -1.0000, -0.9385, -0.9516]),tensor([-0.9033])), (tensor([-0.8769, -0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341, -1.0000, -0.9385, -0.9516, -0.9033]), tensor([-0.8374])), (tensor([-0.8901, -0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341, -1.0000, -0.9385, -0.9516, -0.9033, -0.8374]), tensor([-0.8637])), (tensor([-0.9253, -0.8637, -0.8066, -0.8066, -0.8593, -0.9341, -1.0000, -0.9385, -0.9516, -0.9033, -0.8374, -0.8637]), tensor([-0.9077]))] #数据每次移动一个位置,每移动一次,上一个列表的第二个数据成为下一个列表的第一个数据,标签label也依次向后挪动。 #打印train_inout_seq列表的长度,将看到它包含120个项目。这是因为尽管训练集包含132个元素,但是序列长度为12,这意味着第一个序列由前12个项目组成,第13个项目是第一个序列的标签。同样,第二个序列从第二个项目开始,到第13个项目结束,而第14个项目是第二个序列的标签,依此类推。 #包含120个项目,因为如果继续从第120个数据读取到132个数据,那么需要第133个数据来求loss,已经超出范围,无法满足了,所以最多120行。 -
LSTM网络搭建
input_size:对应于输入中的要素数量。尽管我们的序列长度为12,但每个月我们只有1个值,即乘客总数,因此输入大小为1。
hidden_layer_size:指定隐藏层的数量以及每层中神经元的数量。
output_size:输出中的项目数,由于我们要预测未来1个月的乘客人数,因此输出大小为1。
在构造函数中,我们创建变量hidden_layer_size,lstm,linear和hidden_cell。LSTM算法接受三个输入:先前的隐藏状态,先前的单元状态和当前输入。该hidden_cell变量包含先前的隐藏状态和单元状态。lstm和linear层变量用于创建LSTM和线性层。
在forward方法内部,将input_seq作为参数传递给lstm图层。lstm层的输出是当前时间步的隐藏状态和单元状态以及输出。lstm图层的输出将传递到该linear图层。预计的乘客人数存储在predictions列表的最后一项中,并返回到调用函数。
class LSTM(nn.Module): def __init__(self, input_size=1, hidden_layer_size=100, output_size=1): super().__init__() self.hidden_layer_size = hidden_layer_size self.lstm = nn.LSTM(input_size, hidden_layer_size) #lstm层 self.linear = nn.Linear(hidden_layer_size, output_size) #全连接层 self.hidden_cell = (torch.zeros(1,1,self.hidden_layer_size), #hidden_cell层 torch.zeros(1,1,self.hidden_layer_size)) def forward(self, input_seq): #lstm处理序列数据,并传递到hidden_cell,输出lstm_out #输入数据格式:input(seq_len, batch, input_size) #seq_len:每个序列的长度 #batch_size:设置为1 #input_size:输入矩阵特征数 lstm_out, self.hidden_cell = self.lstm(input_seq.view(len(input_seq) ,1, -1), self.hidden_cell) #全连接层输出predictions predictions = self.linear(lstm_out.view(len(input_seq), -1)) return predictions[-1] -
训练
model = LSTM() loss_function = nn.MSELoss() #损失函数 optimizer = torch.optim.Adam(model.parameters(), lr=0.001) #优化器 epochs = 10 for i in range(epochs): for seq, labels in train_inout_seq: optimizer.zero_grad() #补充作用? model.hidden_cell = (torch.zeros(1,1,model.hidden_layer_size),torch.zeros(1,1,model.hidden_layer_size)) y_pred = model(seq) single_loss = loss_function(y_pred, labels) single_loss.backward() optimizer.step() if i%25 == 1: print(f'epoch:{i:3}loss: {single_loss.item():10.8f}') print(f'epoch: {i:3} loss: {single_loss.item():10.10f}') -
预测(利用前12个点预测新点,然后将预测值作为新的输入,滚动预测下一个点)
fut_pred = 12 #预测fut_pred个数据 test_inputs = train_data_normalized[-train_window:].tolist() #取出最后12个月数据为列表 待预测的数据是第133个起 model.eval() #eval模式,不更新梯度 #预测133~(133+11)个数据 12 for i in range(fut_pred): seq = torch.FloatTensor(test_inputs[-train_window:]) #取出最后12个数据 with torch.no_grad(): model.hidden_cell = (torch.zeros(1,1,model.hidden_layer_size),torch.zeros(1,1,model.hidden_layer_size)) test_inputs.append(model(seq).item()) #每次输出一个预测值,加到列表 print(test_inputs[train_window:]) #train_window起才是预测的数据(训练集中最后一组训练数据) #逆归一化回原值范围,test_inputs中排除前12个数据(训练数据) actual_predictions = scaler.inverse_transform(np.array(test_inputs[train_window:] ).reshape(-1, 1)) -
绘图
x = np.arange(132, 132+fut_pred, 1) plt.title('Month vs Passenger') plt.ylabel('Total Passengers') plt.grid(True) plt.autoscale(axis='x', tight=True) plt.plot(np.arange(132,144,1), test_data) #test_data只有12个数据真实值 plt.plot(x, actual_predictions) plt.show()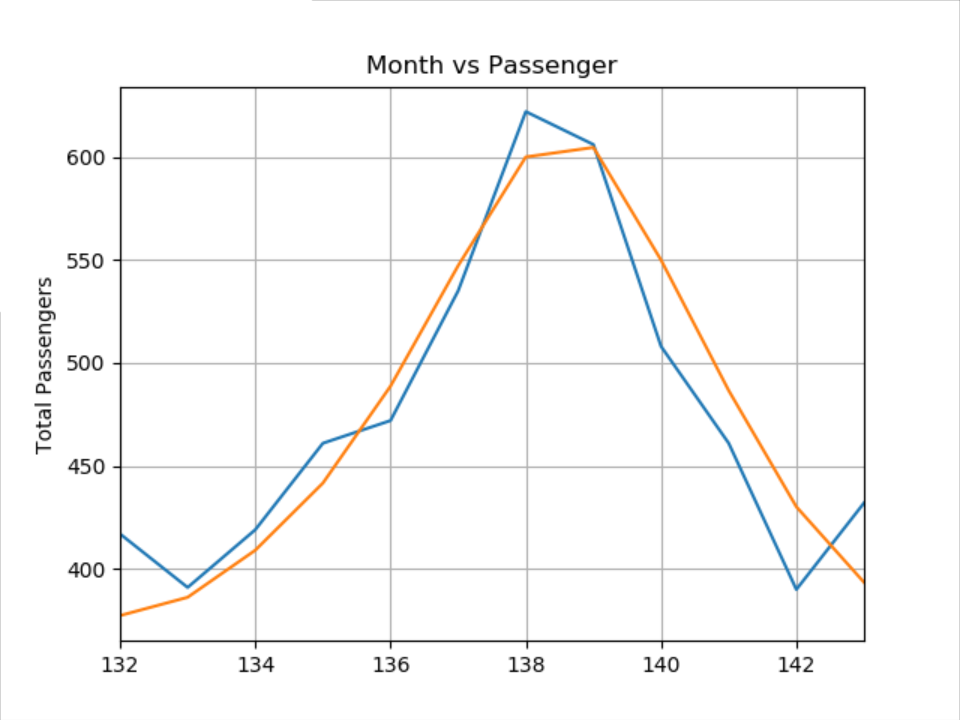
TIPS
介绍几个参数
-
test_data_size : 原始数据集中最后待验证的数据个数,可修改
-
train_window : 训练数据集中,每批次训练的数据个数,可修改
-
fut_pred : 待预测的数据个数
-
LSTM输入数据格式:input(seq_len, batch_size, input_size) #seq_len/timestep:每个序列的长度 #batch_size:设置为1 #input_size:输入矩阵特征数
这里我们可以随意的修改,比如可以修改成用最后14个数据验证,每次用15个月份的数据作训练,预测100个月份的数据等等。当然一般来说,不同的问题下,最佳设置的参数不同,比如本问题中就是按1年12个月来设置是最佳的结果。

