


数据爬取实战——POI爬取及数据可视化
数据爬取实战——POI爬取及数据可视化
爬虫技术和GIS结合在一起可以碰撞出意想不到的火花,通过百度地图api/forlium/requests/wordcloud库可以爬取到感兴趣的POI数据,并直观地将其显示出来。本章通过requests库调用百度地图api爬取数据,并利用forlium库可视化数据,最后用wordcloud库统计出现频率最高的汉字,制作词云。
(1)调用百度地图api/requests库爬取POI数据
requests库是爬虫技术中常用的开源库,常用来对浏览器发起请求进行访问。百度地图api开发文档见http://lbs.baidu.com/index.php?title=webapi/guide/webservice-placeapi。在创建ak秘钥后,我们就可以调用百度api的接口爬取数据,我们可以通过网页接口来执行get请求,爬取数据,这里给出地点检索的相关接口。
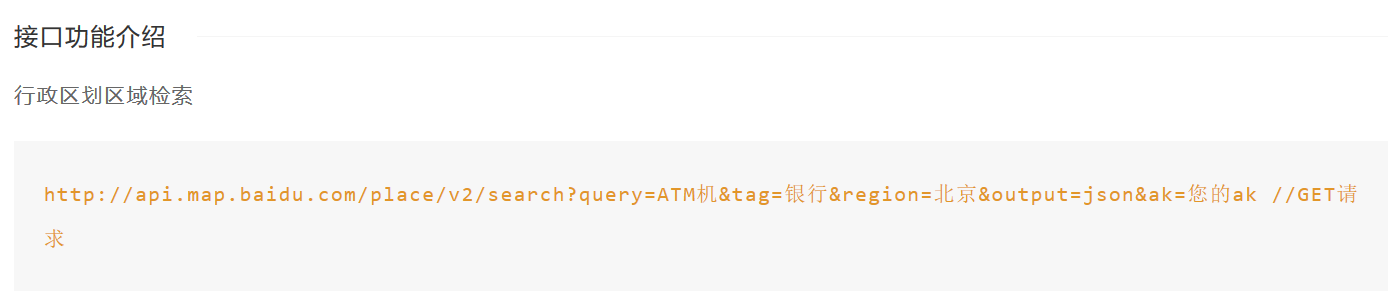



具体代码方面,笔者采用了https://github.com/lbygg227/POI_GET的部分代码,感谢此人贡献的开源代码。代码主要使用了两种检索方法:1. 按行政区划检索POI,受到百度地图api的限制,最多开源读取20页数据,共计400条,所以这种方法比较适用于数量较小的POI爬取,不推荐在大的工程项目中使用。2. 按矩形框搜索,通过给出矩形框的左下角和右上角经纬度坐标,结合api进行爬取。
Method1
def method_region():
print("请输入所需要爬取数据的行政区划名称,如南京市,南京市鼓楼区等")
city=str(input())
print ('开始')
urls=[] #声明一个数组列表
for i in range(0,20):
page_num=str(i)
url='http://api.map.baidu.com/place/v2/search?query='+name+'®ion='+city+'&page_size=20&page_num='+str(page_num)+'&output=json&ak='+ak
urls.append(url)
print ('url列表读取完成')
for url in urls:
getdata(url)
print('爬取中,请耐心等待')
f.close()
print ('完成,文件位于D盘目录下,请查看')
Method2
def method_bounds(): #读取POI更多,更细
print("请输入所选取地图矩形区域范围的左下角经度")
lat_l=float(input())
print("请输入所选取地图矩形区域范围的左下角纬度")
lng_l=float(input())
print("请输入所选取地图矩形区域范围的右上角经度")
lat_r=float(input())
print("请输入所选取地图矩形区域范围的右上角纬度")
lng_r=float(input())
a=(lat_l>=lat_r or lng_l>=lng_r)
while a:
print('经纬度输入错误,请重新输入')
print("请输入所选取地图矩形区域范围的左下角经度")
lat_l=float(input())
print("请输入所选取地图矩形区域范围的左下角纬度")
lng_l=float(input())
print("请输入所选取地图矩形区域范围的右上角经度")
lat_r=float(input())
print("请输入所选取地图矩形区域范围的右上角纬度")
lng_r=float(input())
a=(lat_l>lat_r or lng_l>lng_r)
lng_c=lng_r-lng_l
lat_c=lat_r-lat_l
#将研究区按经纬度步长大小划分若干块,存储每块左下、右上经纬度
lng_num=int(lng_c/0.1)+1 #经纬度跨步越小,采集数据越多
lat_num=int(lat_c/0.1)+1
arr=np.zeros((lat_num+1,lng_num+1,2)) #前两维是行数、列数,第三维是2元列表,经度、纬度
for lat in range(0,lat_num+1):
for lng in range(0,lng_num+1):
arr[lat][lng]=[lng_l+lng*0.1,lat_l+lat*0.1]
urls=[]
print('开始')
for lat in range(0,lat_num):
for lng in range(0,lng_num):
for b in range(0,20): #每块最多读取20页POI数据
page_num=str(b)
url='http://api.map.baidu.com/place/v2/search?query='+name+'&bounds='+str((arr[lat][lng][0]))+','+str((arr[lat][lng][1]))+','+str((arr[lat+1][lng+1][0]))+','+str((arr[lat+1][lng+1][1]))+'&page_size=20&page_num='+str(page_num)+'&output=json&ak='+ak
urls.append(url)
print ('url列表读取完成')
for url in urls:
getdata(url)
print('爬取中,请耐心等待')
f.close()
print ('完成,文件位于D盘目录下,请查看')
这里介绍一下Method2。它采用的思想主要是这样的,虽然我们对某一块区域爬取的数据数量受到了限制(400个/20页),但我们可以通过将一整块较大的矩形区域划分为若干小矩形块,然后分别遍历爬取从而解决这个问题。划分的步长越小(这里是0.1),爬取的越仔细,数据量也越大,亲测0.01时爬取的数据比前者多了2000+。在网格小到一定程度的时候,网格内的POI数量小于400,就不会受到20页等的限制了,这时爬取的数据较为详细。
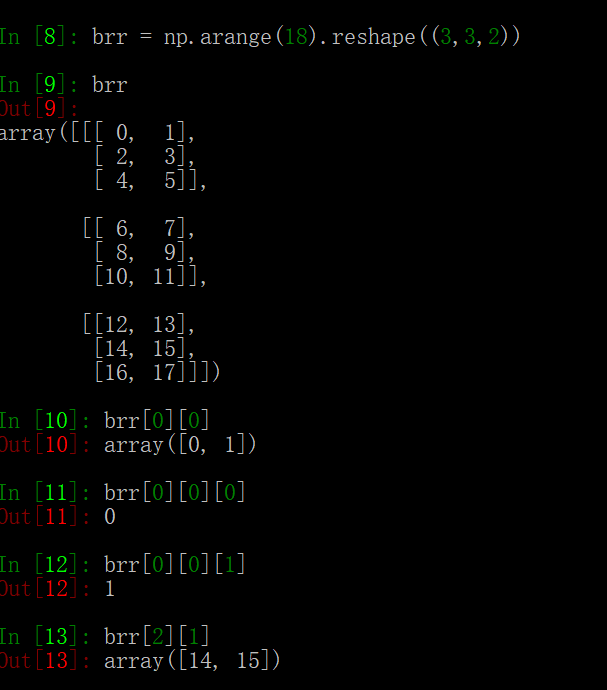
上图是三维数组的形式,函数中用于存储经纬度的列表是三维数组,前两维是行数和列数,第三维存储了经纬度数据,具体存放形式如上图。
def getdata(url):
try:
socket.setdefaulttimeout(timeout) #设置间隔时间,防止爬取时被阻断
html=requests.get(url)
data=html.json()
if data['results']!=None:
for item in data['results']:
jname=item['name']#获取名称
jlat=item['location']['lat']#获取经纬度
jlon=item['location']['lng']
jarea=item['area']#获取行政区
jadd=item['address']#获取具体地址
j_str=jname+','+str(jlat)+','+str(jlon)+','+jarea+','+jadd+','+'\n'
f.write(j_str)
#time.sleep(1)
except:
getdata(url)
这段代码不用多说吧,requests发起get请求,解析数据为json格式,然后获取到名称、经纬度、行政区、地址等信息。

(2)制作heatmap
获取这些数据后,为了进行数据的可视化,我们学习了forlium模块。
folium是js上著名的地理信息可视化库leaflet.js为Python提供的接口,通过它,我们可以通过在Python端编写代码操纵数据,来调用leaflet的相关功能,基于内建的osm或自行获取的osm资源和地图原件进行地理信息内容的可视化,以及制作优美的可交互地图。其语法格式类似ggplot2,是通过不断添加图层元素来定义一个Map对象,最后以几种方式将Map对象展现出来。
import numpy as np
import pandas as pd
import folium
import webbrowser #浏览器
from folium.plugins import HeatMap
poi_file = 'D:\POI-res.txt'
p_lon =[]
p_lat =[]
poi_name =[]
f = open(poi_file, 'r', encoding='utf-8') #注意encoding='utf-8'
for line in f.readlines(): #逐行读取
line = line.split(',')
p_lon.append(line[2])
p_lat.append(line[1])
poi_name.append(line[0])
f.close()
data = [ [p_lat[i], p_lon[i]] for i in range(2000) ] #将数据制作成[lats,lons,weights]的形式,这里只显示2000个POI数据
map_osm = folium.Map(location=[1,2],zoom_start=5) #绘制Map,开始缩放程度是5倍
HeatMap(data).add_to(map_osm) # 绘制热力图,并将热力图添加到map里
file_path = r"D:/text.html"
map_osm.save(file_path) # 保存为html文件
webbrowser.open(file_path) # 默认浏览器打开
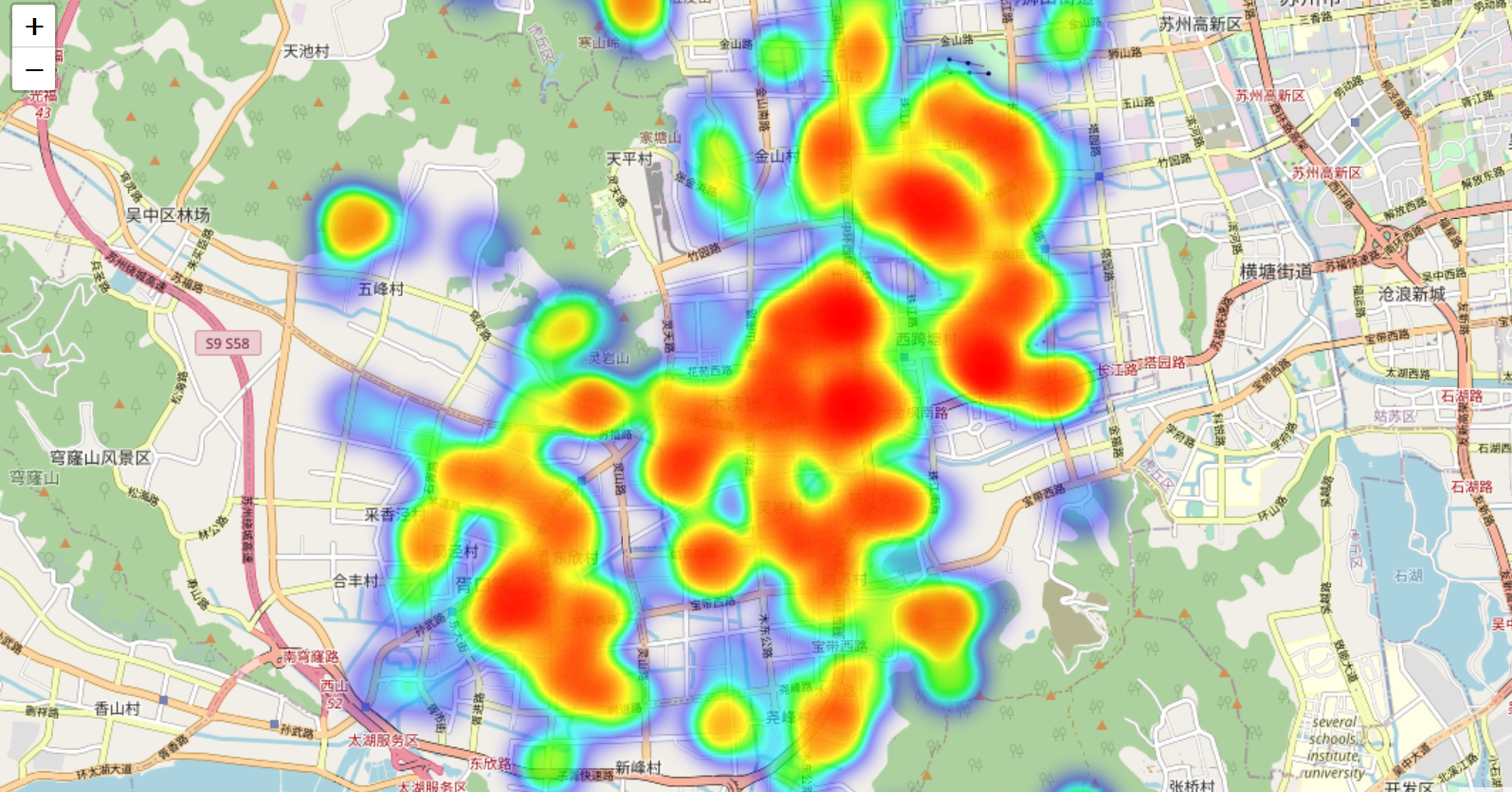
如图,效果还算不错的嘛。
(3)wordcloud制作
早就听过wordcloud的大名了,选取文本中的高频词汇,然后按频率分布制作词云。这里由于字符串属于中文字符,需要下载字体文件,进行解译(旁门左道字体)。
import wordcloud
#注:文件名不能为wordcloud.py,会导不了库
poi_name = []
f = open( 'D:\POI-res.txt','r',encoding='utf-8')
for line in f.readlines():
line = line.split(',')
poi_name.append(line[0])
text = str(poi_name) #列表转str字符串
wc = wordcloud.WordCloud(
background_color='white',
font_path="D:\Tablefile\POI_GET\POI_GET-master\PangMenZhengDaoBiaoTiTi-1.ttf" #添加字体,否则中文字体会乱码
)
wc.generate(text)
wc.to_file(r"D:\Tablefile\POI_GET\POI_GET-master\1.png")

沙县小吃果然傲视群雄啊,哈哈。
这里还介绍一下jieba库,这个库可以针对文本进行词义判断,从而进行划分,常常和wordcloud配合使用。
import jieba
seg_list = jieba.cut("他来到上海交通大学", cut_all=False)
print("【精确模式】:" + "/ ".join(seg_list))
除了上述这些以外,我们还可以用百度地图api爬取感兴趣POI附近的POI数据。主要是获取感兴趣POI后,获取其位置,如按radius=500搜索该POI附近的其他POI。详细代码见博客https://www.cnblogs.com/IvyWong/p/11812412.html。
另外说一句,本期博客是markdown编写的,格式确实相当不错呢!

