
Python爬虫笔记--Scrapy
上次介绍了requests\bs4\re库,今天介绍一个爬虫框架Scrapy。
一、流程介绍
Scrapy是一个爬虫框架,他爬取的形式不像requests那么简单,而是通过cmd创建一个工程项目,生成文件夹,然后对文件夹的内容进行修改,最后在命令行里面下达爬虫命令。
流程具体如下:
- 建立工程,cd到路径,cmd里scrapy startproject name
scrapy startproject python123demo #新建一个“python123demo”工程名的爬虫工程
- 新建爬虫,cd到name文件夹,cmd输入scrapy genspider demo python123.io(创建名为demo的蜘蛛,域名为python123.io)
- 修改spider,demo.py,打开刚创建的py文件,修改url,编辑parse(self, response),用于处理响应,解析内容,可以加上re正则表达式和css选择器,用于提取数据,形成字典。
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo'
allowed_domains = ['python123.io']
start_urls = ['http://python123.io/']
#url的提取可以用yield调用,节省存储空间
def parse(self, response):
pass - pipelines.py编写,用于写入数据到文件夹。
- 运行爬虫,cmd中scrapy crawl demo
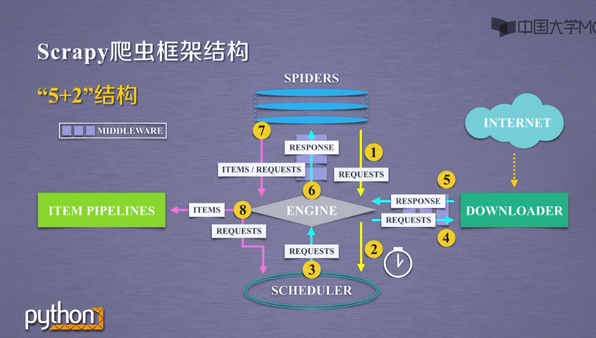
二、介绍一下Scrapy爬虫的框架结构(5+2)
Engine(不需要用户修改) 控制所有模块之间的数据流 根据条件触发事件
Downloader(不需要用户修改) 根据请求下载网页 Scheduler(不需要用户修改) 对所有爬取请求进行调度管理
Downloader Middleware 目的:实施Engine、Scheduler、和Downloader之间进行用户可配置的控制 功能:修改、丢弃、新增请求或响应 用户可以编写配置代码
Spider 解析Downloader返回的响应(Response) 产生爬取项(scrapy item) 产生额外的爬取请求(Request) 需要用户编写配置代码
Item Pipelines 流水线处理Spider产生的爬取项 由一组操作顺序组成,类似流水线,每个操作是一个Item Pipelines类型 可能操作包括:清理、检验和查重爬取项中的HTML数据、将数据存储到数据库
Spider Middleware 目的:对请求和爬取项的再处理 功能:修改、丢弃、新增请求或爬取项 用户可以编写配置代码
三、Scrapy常用命令

四、爬虫的数据类型
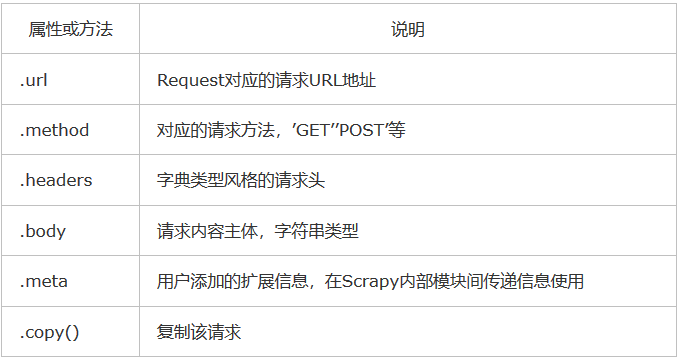
1)Request类
class scrapy.http.Request()
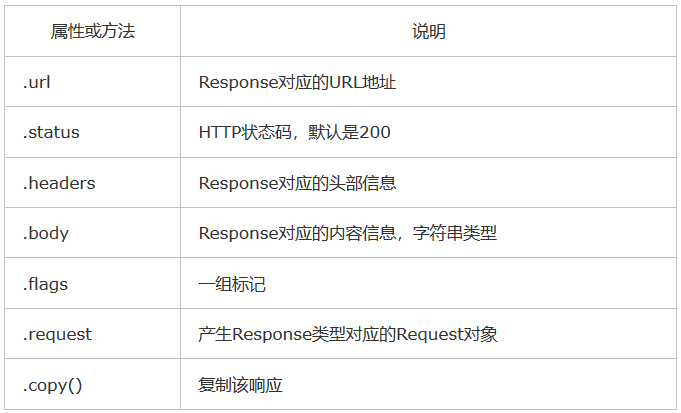
2)Response类
class scrapy.http.Response()
3)Item类(Item对象表示一个HTML页面中提取的信息内容)
class scrapy.item.Item()
五、Scrapy提取信息的方法
Scrapy爬虫支持多种HTML信息提取方法
Beautiful Soup
lxml
re
XPath Selector
CSS Selector
CSS Selector的基本使用
<HTML>.css(‘a::attr(href)’).extract()
六、总结
总得来说,Scrapy适合高并发量(如爬取多个网页)的情况,爬取速度较快。但是定制方面不如Request灵活。
Request库定制灵活,虽然爬取速度较慢,但是上手容易,比较适合轻度爬虫的人使用。
此外,还有urllib等爬虫库,如有需求,再做研究。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号