面试题
1. java中wait和sleep有什么区别?
答:最大区别是等待时wait会释放锁,而sleep会一直持有锁;wait通常用于线程时交,互,sleep通常被用于暂停执行;
sleep()是线程线程类(Thread)的方法,调用会暂停此线程指定的时间,但监控依然保持,不会释放对象锁,到时间自动恢复;wait()是Object的方法,调用会放弃对象锁,进入等待队列,待调用notify()/notifyAll()唤醒指定的线程或者所有线程,才会进入锁池,不再次获得对象锁才会进入运行状态;
2. spring主要使用了哪些?IOC实现原理是什么?AOP实现原理是什么?
答:spring主要功能有IOC,AOP,MVC等,IOC实现原理:先反射生成实例,然后调用时主动注入。AOP原理:主要使用java动态代理。
3. 说说数据库性能优化有哪些方法?
- 使用explain进行优化,查看sql是否充分使用索引
- 避免使用in,用exist替代
- 查询时要尽可能将操作移至等号右边
- 尽量避免全表查询
- 使用查询缓存优化查询
-
示例如下: 1:SELECT username FROM user WHERE signup_date >= CURDATE() (尽量sql语句不要总是变化) 2:SELECT username FROM user WHERE signup_date >= '2014-06-24‘
-
- 为搜索字段建立索引(索引不一定就是给主键或者是唯一的字段,如果在表中,有某个字段经常用来做搜索,需要将其建立索引)
4. HTTP请求方法get和post有什么区别?
1:Post传输数据时,不需要在URL中显示出来,而Get方法要在URL中显示。(安全性)
2:Post传输的数据量大,可以达到2M,而Get方法由于受到URL长度限制,只能 传递大约1024字节.(数据量)
3:Post就是为了将数据传送到服务器段,Get就是为了从服务器段取得数据.而Get 之所以也能传送数据,只是用来设计告诉服务器,你到底需要什么样的数据.Post 的信息作为http请求的内容,而Get是在Http头部传输的。
5. 有了解分布式事务如何实现?
答、在分布式系统中一次操作由多个系统协同完成,这种一次事务操作涉及多个系统通过网络协同完成的过程称为分布
式事务。(cap理论)
解决方案:1、两阶段提交协议(2PC) 2、事务补偿 TCC 3、消息队列实现最终一致性(首先得保证幂等性)幂等性是指同一个操作无论请求多少次,其结果都相同。
详细内容看分布式事务解决篇
6、了解java反射机制?反射生成类,能访问私有变量?
答、在将源代码进行编译成字节码时候通过类加载器 将类的各个组成部分封装为其他对象,所以运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法 这就是反射机制(比如把成员变量抽取出来封装成数组 Field [],构造函数抽取出来封装成数组 Construction [],将成员方法封装成 Method [])
对于反射机制来说,在反射面前没有公有私有,都可以通过暴力反射解决。
7、分布式锁的三种实现方式?
答、1、数据库乐观锁(加版本号) 2、基于redis实现分布式锁(使用redission框架) 3、基于zookeeper实现分布式锁
8、讲讲分库分表策略
答、分库分表方案:
-
水平分库:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。(库的数据太多)
-
水平分表:以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。(表的数据太多)
-
垂直分库:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。(每个微服务对应一个数据库)
-
垂直分表:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
9、 事务的隔离级别有哪些?MySQL的默认隔离级别是什么?
-
读未提交(Read Uncommitted)
-
读已提交(Read Committed)
-
可重复读(Repeatable Read)事务A又被事务B干扰到了!在事务A范围内,两个相同的查询,读取同一条记录,却返回了不同的数据,这就是不可重复读
-
串行化(Serializable)
Mysql默认的事务隔离级别是可重复读(Repeatable Read),即事物之间具有隔离性,不能互相干扰。
10、什么是幻读,脏读,不可重复读呢?
- 脏读:读到别人未提交的数据
- 幻读:前后多次读取,前后数据总量不一致
- 不可重复读:前后多次读取,数据内容不一致
11、SQL优化的一般步骤是什么,怎么看执行计划(explain),如何理解其中各个字段的含义。
-
show status 命令了解各种 sql 的执行频率
-
通过慢查询日志定位那些执行效率较低的 sql 语句
-
explain 分析低效 sql 的执行计划(这点非常重要,日常开发中用它分析Sql,会大大降低Sql导致的线上事故)
12、 一条SQL语句在MySQL中如何执行的?
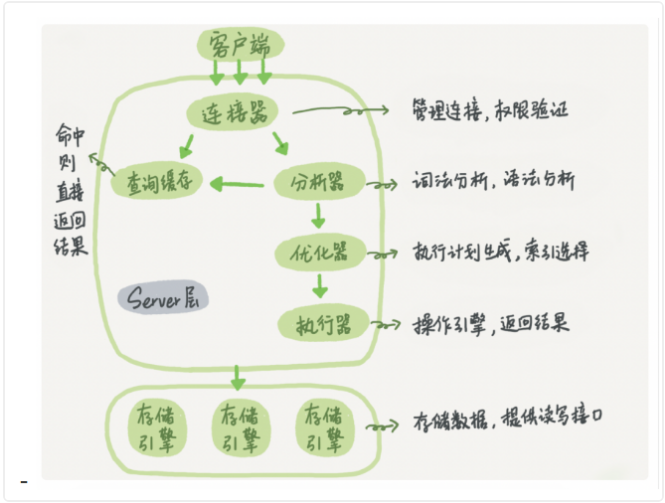
查询语句:
-
先检查该语句是否有权限
-
如果没有权限,直接返回错误信息
-
如果有权限,在 MySQL8.0 版本以前,会先查询缓存。
-
如果没有缓存,分析器进行词法分析,提取 sql 语句select等的关键元素。然后判断sql 语句是否有语法错误,比如关键词是否正确等等。
-
优化器进行确定执行方案
-
进行权限校验,如果没有权限就直接返回错误信息,如果有权限就会调用数据库引擎接口,返回执行结果。
13、mysql 的内连接、左连接、右连接有什么区别?
-
Inner join 内连接,在两张表进行连接查询时,只保留两张表中完全匹配的结果集
-
left join 在两张表进行连接查询时,会返回左表所有的行,即使在右表中没有匹配的记录。
-
right join 在两张表进行连接查询时,会返回右表所有的行,即使在左表中没有匹配的记录。
14、说一下数据库的三大范式
-
第一范式(确保每列保持原子性) (每一列都不能再分割)
-
第二范式(确保表中的每列都和主键相关)
-
第三范式(确保每列都和主键列直接相关,而不是间接相关) (不能有冗余数据)
15、讲一下持续集成的流程
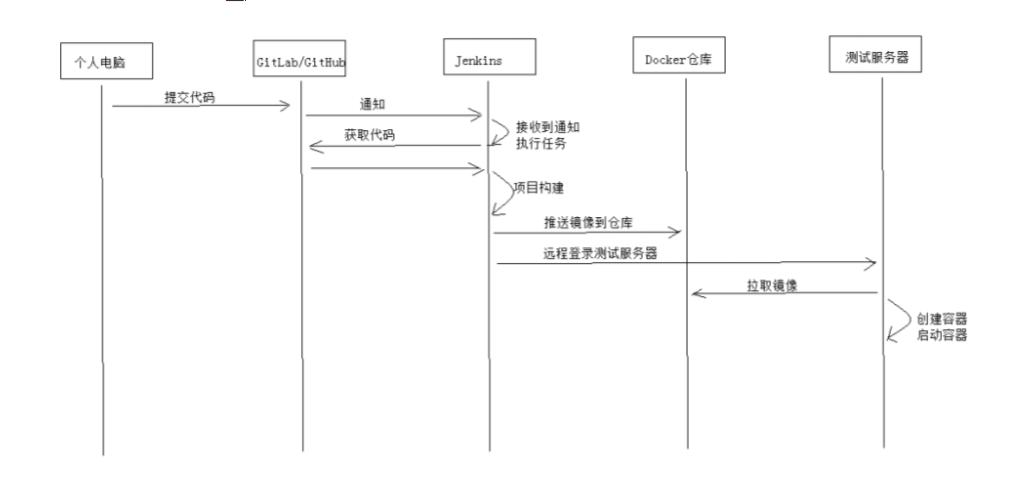
主要流程描述:提交代码通知Jenkins去拉去代码并构建项目,然后打包成镜像推送给远程docker仓库,Jenkins然后远程登入测试服务器去拉取镜像创建容器并启动容器。
16、讲一下IOC和AOP
答、1、Ioc:我们本来是面向对象编程的,所以对象的创建是由程序自己控制的,控制反转后就将对象的创建转移给了第三方(即Spring容器) 一句话,对象由Spring创建、管理、装配
2、Aop:
几乎声明了所有开发中常用的依赖的版本号
3、springboot一启动会默认加载127个场景,每个场景都对应一个自动配置类,这些自动配置类只有在引入了这个starter场景依赖时才会生效,因为它有个条件注解@condition进行判断;生效之后这个自动配置类会将自己类中的组件装配到容器当中,只要容器有了这些组件就相当于有了这些功能;然后这些组件都有默认值,在自动配置类中指定的那个xxxproperties中,然后xxxproperties绑定配置文件appication.properties,用户只需要修改配置文件就能对组件进行修改。
- 定制化配置
- 用户直接用自己@Bean替换底层的组件
- 用户去看这个组件是获取的配置文件什么值就去修改。
xxxxxAutoConfiguration ---> 组件 ---> xxxxProperties里面拿值 ----> application.properties
原理分析套路:

18、== 和 equals 的区别是什么?
==是引用类型;equals是基本类型
对于基本类型和引用类型 == 的作用效果是不同的,如下所示:
- 基本类型:比较的是值是否相同;
- 引用类型:比较的是引用是否相同;
代码示例:
String x = "string";
String y = "string";
String z = new String("string");
System.out.println(x==y); // true
System.out.println(x==z); // false
System.out.println(x.equals(y)); // true
System.out.println(x.equals(z)); // true
代码解读:因为 x 和 y 指向的是同一个引用,所以 == 也是 true,而 new String()方法则重写开辟了内存空间,所以 == 结果为 false,而 equals 比较的一直是值,所以结果都为 true。
19、 接口和抽象类有什么区别?
- 实现:抽象类的子类使用 extends 来继承;接口必须使用 implements 来实现接口。
- 构造函数:抽象类可以有构造函数;接口不能有。
- 实现数量:类可以实现很多个接口;但是只能继承一个抽象类。
- 访问修饰符:接口中的方法默认使用 public 修饰;抽象类中的方法可以是任意访问修饰符。
20、ArrayList 和 LinkedList 的区别是什么?
ArrayList 是动态数组的数据结构实现,而 LinkedList 是双向链表的数据结构实现。
综合来说,在需要频繁读取集合中的元素时,更推荐使用 ArrayList,而在插入和删除操作较多时,更推荐使用 LinkedList。
21、说一下 session 的工作原理
session 的工作原理是客户端登录完成之后,服务器会创建对应的 session,session 创建完之后,会把 session 的 id 发送给客户端,客户端再存储到浏览器中。这样客户端每次访问服务器时,都会带着 sessionid,服务器拿到 sessionid 之后,在内存找到与之对应的 session 这样就可以正常工作了。
22、怎么保证redis缓存和数据库数据的一致性?
- 合理设置缓存的过期时间。
- 新增、更改、删除数据库操作时同步更新 Redis,可以使用事物机制来保证数据的一致性。
23、并行和并发有什么区别?
并行:多核cpu同时执行多个任务
并发:是单核cpu交替执行多个任务(速度交替很快所以看起来像是同时进行)
24、 forward 和 redirect 的区别?
forward 是转发 和 redirect 是重定向:
- 地址栏 url 显示:foward url 不会发生改变,redirect url 会发生改变;
- 数据共享:forward 可以共享 request 里的数据,redirect 不能共享;
- 效率:forward 比 redirect 效率高。
25、简述分代垃圾回收器是怎么工作的?(了解,后续深入理解)
分代回收器有两个分区:老生代和新生代,新生代默认的空间占比总空间的 1/3,老生代的默认占比是 2/3。
新生代使用的是复制算法,新生代里有 3 个分区:Eden、To Survivor、From Survivor,它们的默认占比是 8:1:1,它的执行流程如下:
- 把 Eden + From Survivor 存活的对象放入 To Survivor 区;
- 清空 Eden 和 From Survivor 分区;
- From Survivor 和 To Survivor 分区交换,From Survivor 变 To Survivor,To Survivor 变 From Survivor。
每次在 From Survivor 到 To Survivor 移动时都存活的对象,年龄就 +1,当年龄到达 15(默认配置是 15)时,升级为老生代。大对象也会直接进入老生代。
老生代当空间占用到达某个值之后就会触发全局垃圾收回,一般使用标记整理的执行算法。以上这些循环往复就构成了整个分代垃圾回收的整体执行流程。
26、什么是vue生命周期?
总共分为8个阶段创建前/后,载入前/后,更新前/后,销毁前/后。
· 创建前/后: 在beforeCreate阶段,vue实例的挂载元素el和数据对象data都为undefined,还未初始化。在created阶段,vue实例的数据对象data有了,el还没有。
· 载入前/后:在beforeMount阶段,vue实例的$el和data都初始化了,但还是挂载之前为虚拟的dom节点,data.message还未替换。在mounted阶段,vue实例挂载完成,data.message成功渲染。
· 更新前/后:当data变化时,会触发beforeUpdate和updated方法。
· 销毁前/后

 浙公网安备 33010602011771号
浙公网安备 33010602011771号