数据库操作
结构化查询语句分类
创建数据表
属于DDL的一种,语法 :
create table [if not exists] `表名`( '字段名1' 列类型 [属性][索引][注释], '字段名2' 列类型 [属性][索引][注释], #... '字段名n' 列类型 [属性][索引][注释] )[表类型][表字符集][注释];
说明 : 反引号用于区别MySQL保留字与普通字符而引入的 (键盘esc下面的键).
数据值和列类型
列类型 : 规定数据库中该列存放的数据类型
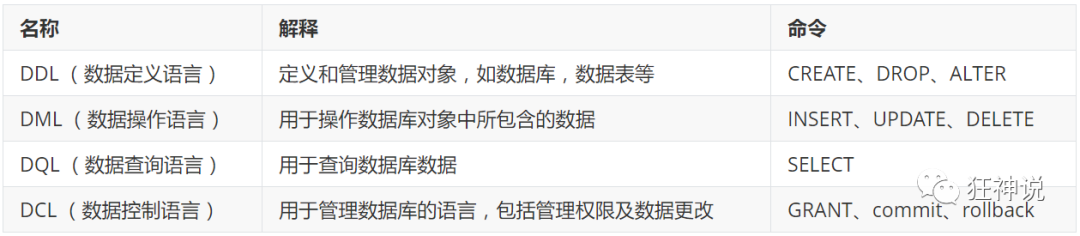
数值类型
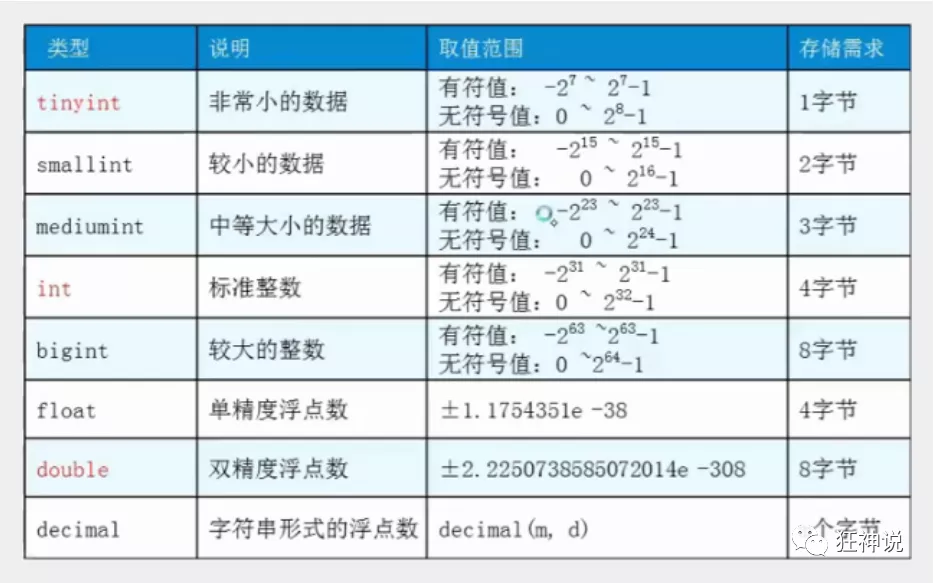
字符串类型
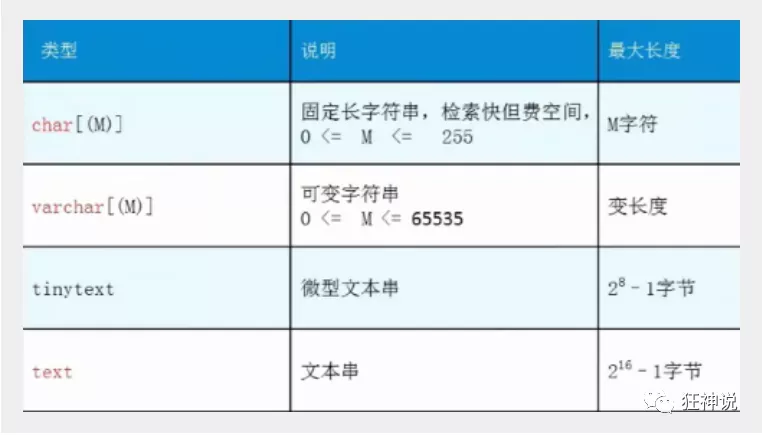
日期和时间型数值类型
NULL值
-
理解为 "没有值" 或 "未知值"
-
不要用NULL进行算术运算 , 结果仍为NULL
数据库引擎
常见的 MyISAM 与 InnoDB 类型:
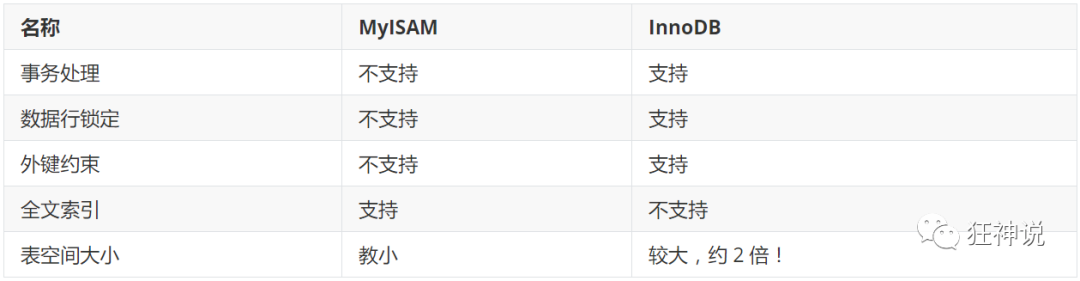
经验 ( 适用场合 ) :
-
适用 MyISAM : 节约空间及相应速度
-
适用 InnoDB : 安全性 , 事务处理及多用户操作数据表
其他
1. 可用反引号(`)为标识符(库名、表名、字段名、索引、别名)包裹,以避免与关键字重名!中文也可以作为标识符! 2. 每个库目录存在一个保存当前数据库的选项文件db.opt。 3. 注释: 单行注释 # 注释内容 多行注释 /* 注释内容 */ 单行注释 -- 注释内容 (标准SQL注释风格,要求双破折号后加一空格符(空格、TAB、换行等)) 4. 模式通配符: _ 任意单个字符 % 任意多个字符,甚至包括零字符 单引号需要进行转义 \' 5. CMD命令行内的语句结束符可以为 ";", "\G", "\g",仅影响显示结果。其他地方还是用分号结束。delimiter 可修改当前对话的语句结束符。 6. SQL对大小写不敏感 (关键字) 7. 清除已有语句:\c
索引
索引的作用
-
提高查询速度
-
确保数据的唯一性
-
可以加速表和表之间的连接 , 实现表与表之间的参照完整性
-
使用分组和排序子句进行数据检索时 , 可以显著减少分组和排序的时间
-
全文检索字段进行搜索优化.
索引命名规范(索引类别_表名_字段名)
主键索引名为pk_字段名;唯一索引名为uk_字段名;普通索引名则为idx_字段名。 说明:pk_ 即primary key;uk_ 即 unique key;idx_ 即index的简称。
索引分类
-
主键索引 (Primary Key)
-
主键 : 某一个属性组能唯一标识一条记录
特点 :
-
最常见的索引类型
-
确保数据记录的唯一性
-
确定特定数据记录在数据库中的位
-
-
-
唯一索引 (Unique)
-
作用 : 避免同一个表中某数据列中的值重复
与主键索引的区别
-
主键索引只能有一个
-
唯一索引可能有多个
CREATE TABLE `Grade`( `GradeID` INT(11) AUTO_INCREMENT PRIMARYKEY, `GradeName` VARCHAR(32) NOT NULL UNIQUE -- 或 UNIQUE KEY `GradeID` (`GradeID`) )
-
-
-
常规索引 (Index)
-
全文索引 (FullText)
索引准则
-
索引不是越多越好
-
不要对经常变动的数据加索引
-
小数据量的表建议不要加索引
-
索引一般应加在查找条件的字段
索引的数据结构
-- 我们可以在创建上述索引的时候,为其指定索引类型,分两类 hash类型的索引:查询单条快,范围查询慢 btree类型的索引:b+树,层数越多,数据量指数级增长(我们就用它,因为innodb默认支持它) -- 不同的存储引擎支持的索引类型也不一样 InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引; MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
三大范式
第一范式 (1st NF)
第一范式的目标是确保每列的原子性,如果每列都是不可再分的最小数据单元,则满足第一范式
第二范式(2nd NF)
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
第二范式要求每个表只描述一件事情
第三范式(3rd NF)
如果一个关系满足第二范式,并且除了主键以外的其他列都不传递依赖于主键列,则满足第三范式.
第三范式需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号