链表的简单理解
链表
通过与数组相对比来理解链表,数组是一组连续的地址可以通过顺移来遍历,相对的链表是一组不连续的地址块,每个地址块都存储了下一个地址块的地址,可以通过这个存储的地址来进行迭代,就像很多个连起来的数组,这样解决了数组的扩容问题,用链表扩容的时候再也不需要,重新找一大块位置了,只需要找到一个地址块(Node)的大小就够了,这也就带来了一个缺点,因为这些Node不是连续的,想要直接读取其中一个Node就要从头节点(Head)开始一个一个迭代,这就不如数组可以直接通过对地址进行增加操作直接访问,而且增加了存储下一个节点地址数据的位置,使得存储同样的数据,链表占用内存更大。
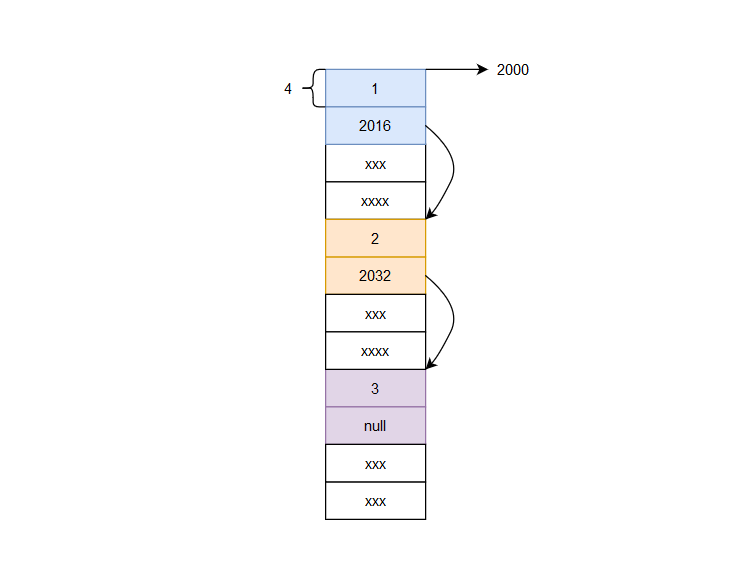
我们从链表头指针一个一个向下,就可以遍历整个链表,但是有一个缺点,只能前进,不能后退,这缺点有点太大了吧, 用指向下一个Node的指针来访问下一个Node,那么我们要访问前一个Node,怎么办,自然是需要一个指向前一个Node的指针了,这就是双(向)链表
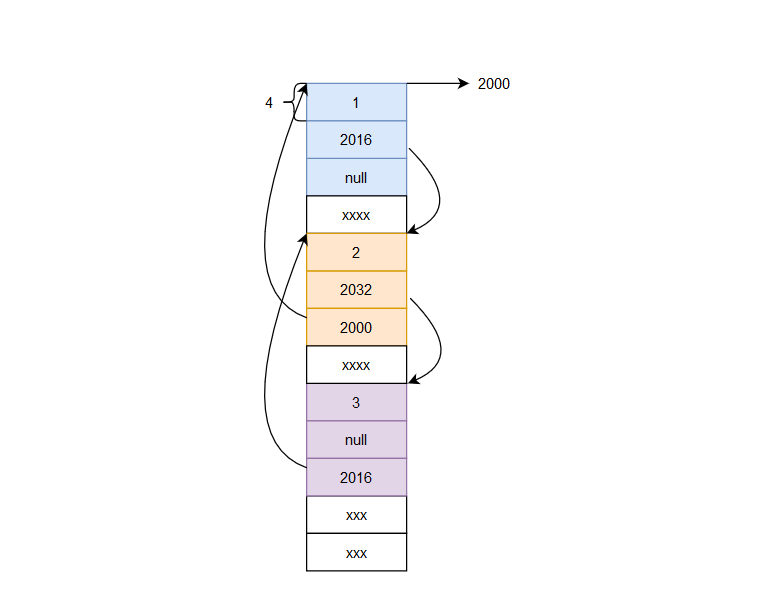
既然都可以双向访问了,那我们让它首尾相接也不算过分吧,这就是循环链表
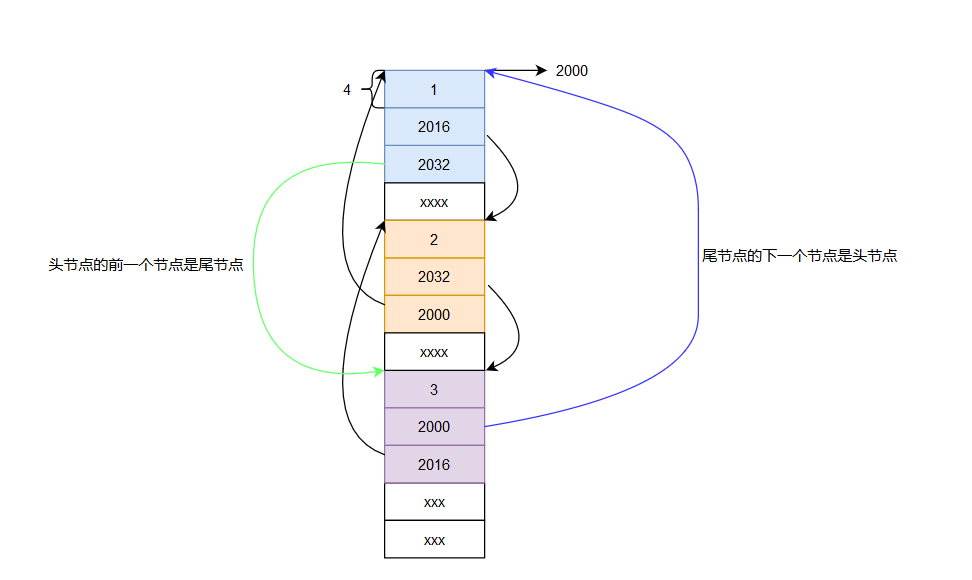
这里的链表都是没有表头的,有些时候我们可以把第一个节点设置为表头,数据部分可以用来存储链表的长度等有意义的数据。
Java实现
下面我们来看看LinkedList是怎么来实现的,首先是节点的定义
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
item用来存储数据,next用来存储下一个节点的Node对象地址,prev用来存储上一个节点的Node对象地址,操作我也们只看两个一个是add一个是remove,因为这是基本操作,其余的复杂操作都是基于这两个操作的,查与改也就是简单的遍历,很容易理解。首先来看add
transient Node<E> first;
transient Node<E> last;
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
类内部定义了两个变量,first和last,分别用来记录头节点和尾节点的

一开始使用一个临时节点 l 来记录尾节点的地址,然后把尾节点设置为新加入的节点,之后出现了两种选择,第一种是这个链表是空的,之前没有节点,那么这个链表的last就是null,也就是l是null,这样的话头尾节点都是这个新加入的节点,第二种是如果这个链表不是空的,那么就是l不是null,这个新的节点要加到之前的节点的后面,也就是把这个节点的地址记录到尾节点的next上,也就是l.next。add还有一个同名的重载函数,在指定的位置插入元素,根据之前的数组随笔不难猜测,肯定是先要判断index范围,然后再进行插入,这个插入操作是和删除相反的,所以我们就不看插入了,直接来看删除
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
根据传入的对象是不是null分别用循环来查找数据值与o相等的节点然后调用unlink
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) { // 该节点的前一个节点是null 那他就是头节点
first = next; // 直接把first的值设置为下一个节点的地址就删除了头节点
} else { // 不是头节点的话
prev.next = next; // 该节点的前一个节点 的下一个节点 就应该是 这个节点的下一个节点
x.prev = null; // 把存储该节点前一个节点的变量赋值为null 方便gc
}
if (next == null) { // 该节点的下一个节点为null 那么他就是尾节点
last = prev; // last所指向的节点就是该节点的前一个节点
} else { // 不是尾节点的话
next.prev = prev; // 该节点的下一个节点 的前一个节点 就应该是 这个节点的前一个节点
x.next = null; // 把存储该节点下一个节点的变量赋值为null 方便gc
}
x.item = null; // 方便gc
size--;
modCount++;
return element;
}
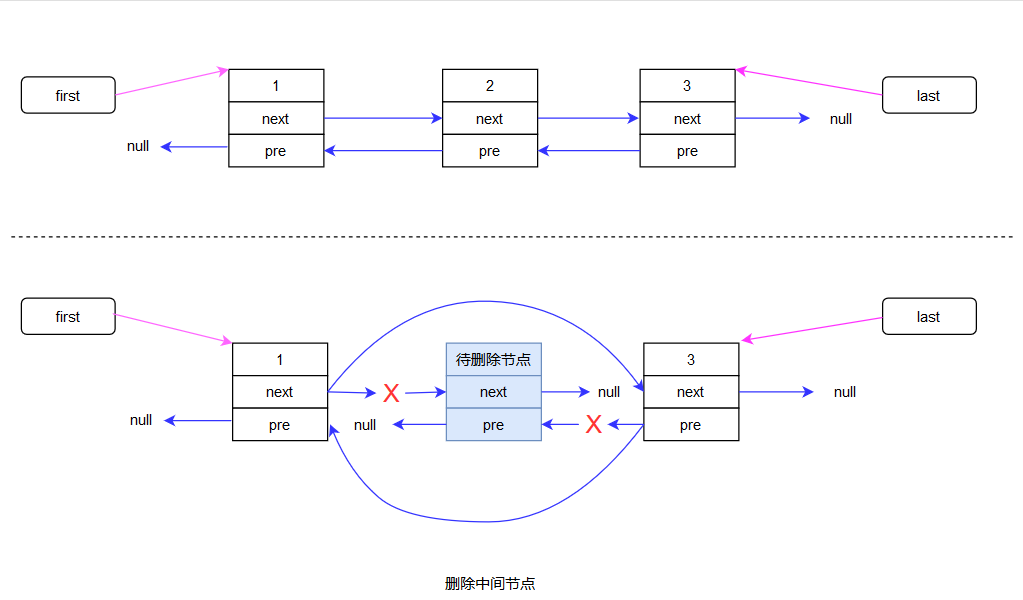
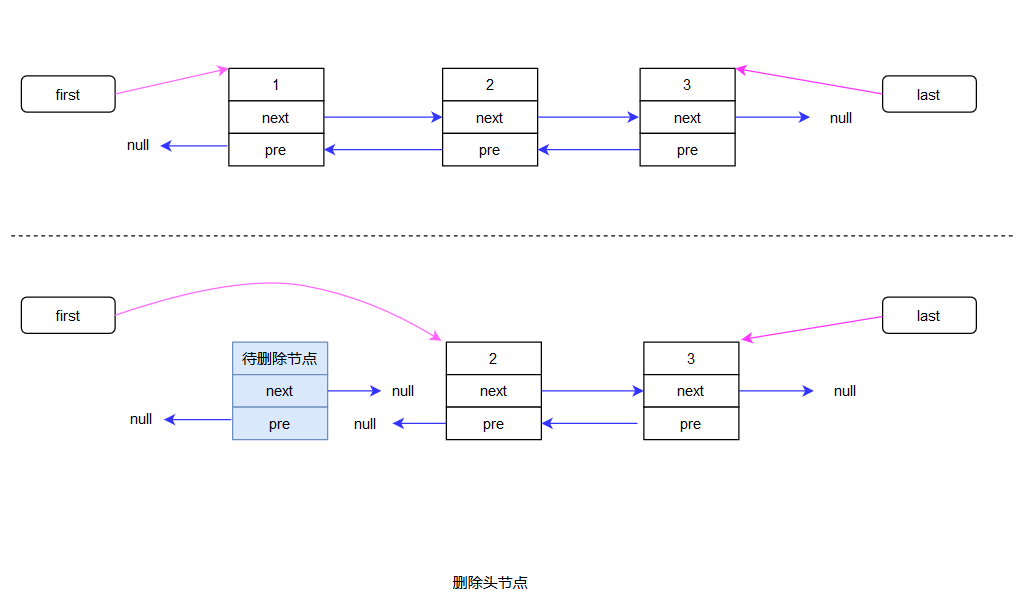
删除尾节点和删除头节点异曲同工我就不画图了,还有单个节点的删除就是fisrt和last都置为null
总结
链表通过在节点里保存前后节点的地址,把一系列的节点连接起来,方便扩容,较为灵活,但是所占空间也变大,具体使用链表还是数组需要根据实际需求来判断。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号