python爬虫之伪装请求头
python本身也是通过向浏览器发送请求获取数据的,存在请求头,如果不进行伪装,会被对方服务器识别从而爬取失败

def askURL(url): data = bytes(urllib.parse.urlencode({ "setAction": "classroomQuery", "PageAction": "Query", "day_time_text": "0011000000000", "school_area_code": "1", "building": "13", "week_no": "256" , "day_no": "2", "day_time1": "ON", "B1": "查询"}), encoding="utf-8") headers = { # 模拟浏览器头部信息,向浏览器发送消息 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:99.0) Gecko/20100101 Firefox/99.0" } #用户代理,表示告诉服务器,我么是什么类型的机器,本质上是告诉浏览器,我们可以接受什么类型的内容 request=urllib.request.Request(url,headers=headers,data=data,method="POST") html="" try: resonse = urllib.request.urlopen(request) html=resonse.read().decode("utf-8") #print(html) except urllib.error.URLError as e: if hasattr(e,"code"): print(e.code) if hasattr(e,"reason"): print(e.reason) return html
伪装请求头headers
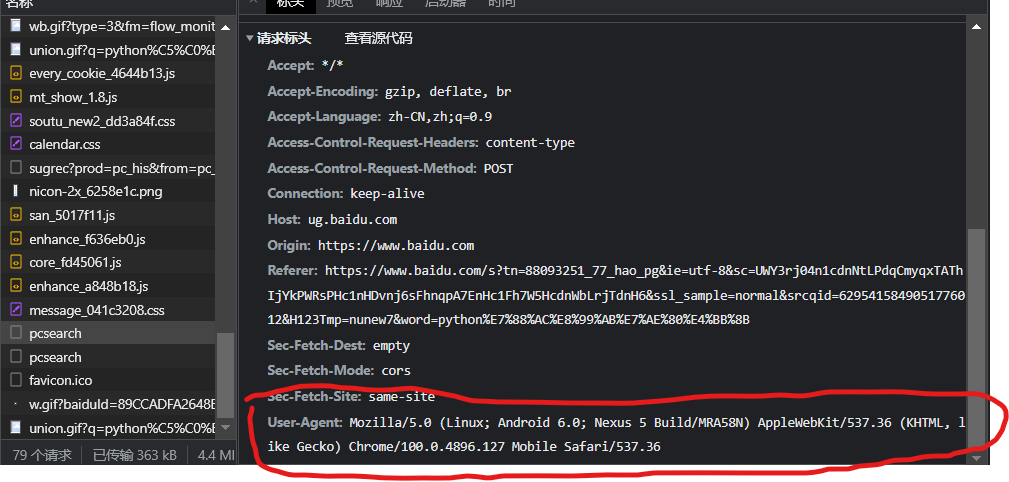
打开任意网站打开控制台网络,复制请求头即可



