slf4j和logback源码解读
slf4j源码阅读(2.0.0快照版本)
这是最新版的,1.x版本的在下面!!!
slf4j 最关键的2个接口,分别是Logger和ILoggerFactory。最关键的入口类,是LoggerFactory
所有的具体实现框架,一定会实现Logger接口和ILoggerFactory接口。前者实际记录日志,后者用来提供Logger 。 而LoggerFactory类,则是前面说过的入口类。
LoggerFactory类如何提供Logger:
public static Logger getLogger(String name) {
ILoggerFactory iLoggerFactory = getILoggerFactory();
return iLoggerFactory.getLogger(name);
}
这里通过调用getILoggerFactory()方法来获取一个ILoggerFactory的具体实例。在通过这个具体的日志工厂来获取对应的Logger
/**
* 返回使用中的ILoggerFactory实例
* ILoggerFactory实例 在编译时与此类绑定
*
* @return 使用中的ILoggerFactory实例
*/
public static ILoggerFactory getILoggerFactory() {
//获取环境中对应的Slf4j服务提供者(实现了SLF4JServiceProvider的实例)。
// 然后通过服务提供者获取一个日志工厂
return getProvider().getLoggerFactory();
}
这里可以看到getILoggerFactory()方法调用了getProvider()来获取一个slf4j服务提供者。再由服务提供者来提供具体的日志工厂实例
/**
* 返回使用中的 SLF4JServiceProvider
*
* @return 返回日志的提供者
* @since 1.8.0
*/
static SLF4JServiceProvider getProvider() {
//如果没有进行初始化,进行双重检查锁判断处理
if (INITIALIZATION_STATE == UNINITIALIZED) {
synchronized (LoggerFactory.class) {
if (INITIALIZATION_STATE == UNINITIALIZED) {
//初始化之前 先将初始化状态设置为正在初始化
INITIALIZATION_STATE = ONGOING_INITIALIZATION;
//执行初始化
performInitialization();
}
}
}
switch (INITIALIZATION_STATE) {
case SUCCESSFUL_INITIALIZATION:
//初始化成功直接返回对应的 PROVIDER(提供者)
return PROVIDER;
case NOP_FALLBACK_INITIALIZATION:
//返回一个应急的提供者
return NOP_FALLBACK_FACTORY;
case FAILED_INITIALIZATION:
//初始化失败则抛出异常
throw new IllegalStateException(UNSUCCESSFUL_INIT_MSG);
case ONGOING_INITIALIZATION:
// 支持重操作初始化 参考 http://jira.qos.ch/browse/SLF4J-97
return SUBST_PROVIDER;
default:
//其他状态就抛出异常
throw new IllegalStateException("Unreachable code");
}
}
这里进行了双重检查锁,并且INITIALIZATION_STATE使用了volatile来修饰,然后判断初始化的状态,如果初始化成功直接返回相应的服务提供者。具体初始化在performInitialization()方法中
private final static void performInitialization() {
//进行绑定
bind();
// 判断初始化状态为成功进行检验
if (INITIALIZATION_STATE == SUCCESSFUL_INITIALIZATION) {
versionSanityCheck();
}
}
这里先进行绑定。绑定什么?应该是绑定具体的日志实现(例如logback),然后进行一个版本检查,进入bind()方法看看如何进行绑定的
//给LoggerFactory绑定服务提供者
private final static void bind() {
try {
//查找所有的服务提供者
List<SLF4JServiceProvider> providersList = findServiceProviders();
//报告是否有多个 SLF4JServiceProvider 的实例 无法抉择
reportMultipleBindingAmbiguity(providersList);
//判断服务提供者是否一个都没有
if (providersList != null && !providersList.isEmpty()) {
PROVIDER = providersList.get(0);
// SLF4JServiceProvider.initialize() is intended to be called here and nowhere else.
//服务提供者只能在这里进行初始化
PROVIDER.initialize();
//设置初始化状态为成功
INITIALIZATION_STATE = SUCCESSFUL_INITIALIZATION;
//打印实际绑定的是那个服务提供者
reportActualBinding(providersList);
} else { //如果服务提供者一个都没有
//如果未扫描到对应的实现类,初始化状态变为无操作的应急NOPServiceProvider
INITIALIZATION_STATE = NOP_FALLBACK_INITIALIZATION;
//没有找到SLF4J提供程序
Util.report("No SLF4J providers were found.");
//默认为 no-operation (NOP) logger 实现
Util.report("Defaulting to no-operation (NOP) logger implementation");
Util.report("See " + NO_PROVIDERS_URL + " for further details.");
//打印忽略掉的静态Logger绑定
Set<URL> staticLoggerBinderPathSet = findPossibleStaticLoggerBinderPathSet();
reportIgnoredStaticLoggerBinders(staticLoggerBinderPathSet);
}
postBindCleanUp();
} catch (Exception e) {
failedBinding(e);
throw new IllegalStateException("Unexpected initialization failure", e);
}
}
这里先查找所有的服务提供者。如果有多个会报一个警告,如果一个都没有会用应急的NOPServiceProvider来作为服务提供者,这个服务提供者提供的Logger什么都没做。如果有则会默认取第一个作为服务提供者,然后进行初始化。
到这里LoggerFactory初始化和Logger的获取就告一段落了!但是刨根问底,slf4j是如何查找所有的服务提供者的?
slf4j是如何查找所有的服务提供者的?
我们进入到上面的findServiceProviders()方法:
//查找所有的服务提供者
private static List<SLF4JServiceProvider> findServiceProviders() {
/**
* ServiceLoader JDK提供的API
* ServiceLoader.load() 基于SPI机制
*/
ServiceLoader<SLF4JServiceProvider> serviceLoader = ServiceLoader.load(SLF4JServiceProvider.class);
List<SLF4JServiceProvider> providerList = new ArrayList<SLF4JServiceProvider>();
for (SLF4JServiceProvider provider : serviceLoader) {
providerList.add(provider);
}
return providerList;
}
这里的ServiceLoader是JDK提供的API,基于SPI的机制来查找SLF4JServiceProvider接口的所有实现类
什么是SPI
SPI全称Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的接口,它可以用来启用框架扩展和替换组件。 SPI的作用就是为这些被扩展的API寻找服务实现。
通过ServiceLoader.load(SLF4JServiceProvider.class)会在类路径下查找META-INF/services/目录下的文件(文件名为接口名)中的类
创建接口
public interface User { }
实现类
public class UserImpl implements User { @Override public String toString() { return "aaa"; } }+ 在resources目录下创建META-INF/services/com.lj.mpdemo.User文件 + ```txt com.lj.demo.UserImpl+ 测试 + ```java public static void main(String[] args) { ServiceLoader<User> users = ServiceLoader.load(User.class); for (User user : users) { System.out.println(user); } } // 结果 aaa
slf4j源码阅读(1.7.30)
由于我下错了源码,然后我发现和springboot目前支持的日志框架代码不一样所以发现自己看的代码目前最新的。也不亏,再来看看目前的版本。slf4j在1.x之前绑定日志是使用的静态Logger绑定,那么2.x之后应该是准备采用SPI的机制来进行绑定。
LoggerFactory提供日志工厂:
public static Logger getLogger(String name) {
ILoggerFactory iLoggerFactory = getILoggerFactory();
return iLoggerFactory.getLogger(name);
}
这里通过调用getILoggerFactory()方法来获取一个ILoggerFactory的具体实例。在通过这个具体的日志工厂来获取对应的Logger,
public static ILoggerFactory getILoggerFactory() {
//如果没有进行初始化,进行双重检查锁判断处理
if (INITIALIZATION_STATE == UNINITIALIZED) {
synchronized (LoggerFactory.class) {
if (INITIALIZATION_STATE == UNINITIALIZED) {
//初始化前 先将初始化状态设置为 正在初始化
INITIALIZATION_STATE = ONGOING_INITIALIZATION;
//执行初始化
performInitialization();
}
}
}
switch (INITIALIZATION_STATE) {
case SUCCESSFUL_INITIALIZATION:
// 通过StaticLoggerBinder获取一个单例的对象,通过单例对象获取LoggerFactory
return StaticLoggerBinder.getSingleton().getLoggerFactory();
case NOP_FALLBACK_INITIALIZATION:
// 应急工厂
return NOP_FALLBACK_FACTORY;
case FAILED_INITIALIZATION:
//初始化失败抛异常
throw new IllegalStateException(UNSUCCESSFUL_INIT_MSG);
case ONGOING_INITIALIZATION:
// support re-entrant behavior.
// See also http://jira.qos.ch/browse/SLF4J-97
return SUBST_FACTORY;
}
throw new IllegalStateException("Unreachable code");
}
这里和之前不同的是,不是通过SPI机制进行绑定,是通过StaticLoggerBinder类进行的静态绑定。先进入初始化方法:
private final static void performInitialization() {
// 进行绑定
bind();
if (INITIALIZATION_STATE == SUCCESSFUL_INITIALIZATION) {
versionSanityCheck();
}
}
private final static void bind() {
try {
Set<URL> staticLoggerBinderPathSet = null;
// 判断不是安卓,查找所有的可能的StaticLoggerBinder
if (!isAndroid()) {
staticLoggerBinderPathSet = findPossibleStaticLoggerBinderPathSet();
reportMultipleBindingAmbiguity(staticLoggerBinderPathSet);
}
// 判断StaticLoggerBinder是否有getSingleton()方法,没有会抛出异常,这里设计的不是很好
StaticLoggerBinder.getSingleton();
INITIALIZATION_STATE = SUCCESSFUL_INITIALIZATION;
reportActualBinding(staticLoggerBinderPathSet);
} catch (NoClassDefFoundError ncde) {
String msg = ncde.getMessage();
if (messageContainsOrgSlf4jImplStaticLoggerBinder(msg)) {
INITIALIZATION_STATE = NOP_FALLBACK_INITIALIZATION;
Util.report("Failed to load class \"org.slf4j.impl.StaticLoggerBinder\".");
Util.report("Defaulting to no-operation (NOP) logger implementation");
Util.report("See " + NO_STATICLOGGERBINDER_URL + " for further details.");
} else {
failedBinding(ncde);
throw ncde;
}
} catch (NoSuchMethodError nsme) {
String msg = nsme.getMessage();
if (msg != null && msg.contains("org.slf4j.impl.StaticLoggerBinder.getSingleton()")) {
INITIALIZATION_STATE = FAILED_INITIALIZATION;
Util.report("slf4j-api 1.6.x (or later) is incompatible with this binding.");
Util.report("Your binding is version 1.5.5 or earlier.");
Util.report("Upgrade your binding to version 1.6.x.");
}
throw nsme;
} catch (Exception e) {
failedBinding(e);
throw new IllegalStateException("Unexpected initialization failure", e);
} finally {
postBindCleanUp();
}
}
这里设计的不是很好,和SPI机制相比,这种静态绑定的机制真的不好!再看前面的StaticLoggerBinder.getSingleton().getLoggerFactory()
这个时候你会发现StaticLoggerBinder类在logback-classic的包下面,也就是说其他的日志也需要写一个这样的静态StaticLoggerBinder类并且包路径必须为org.slf4j.impl.StaticLoggerBinder这样,slf4j在初始化的时候会自动的在类路径下查找这个类进行绑定,如果出现多个会警告。你可能会问那slf4j 编译的时候怎么通过的,应该是编译通过后,把这个类排除掉了。
slf4j怎么和logback对接的?
slf4j委托具体实现框架的StaticLoggerBinder来返回一个ILoggerFactory,从而对接到具体实现框架上
主要在前面提到的:
StaticLoggerBinder.getSingleton().getLoggerFactory()
通过logback的StaticLoggerBinder来返回一个LoggerFactory工厂,那他是如何创建日志工厂的呢?
StaticLoggerBinder实现了LoggerFactoryBinder接口:
public interface LoggerFactoryBinder {
ILoggerFactory getLoggerFactory();
String getLoggerFactoryClassStr();
}
StaticLoggerBinder有一个getSingleton()方法:
//这样就保证这个类只有一个实例
private static StaticLoggerBinder SINGLETON = new StaticLoggerBinder();
public static StaticLoggerBinder getSingleton() {
return SINGLETON;
}
它还有一个静态代码块,当该类加载时会执行:
static {
SINGLETON.init();
}
void init() {
try {
try {
// 委托ContextInitializer类对defaultLoggerContext进行初始化。这里如果找到了任一配置文件,就会根据配置文件去初始化LoggerContext,如果没找到,会使用默认配置
new ContextInitializer(defaultLoggerContext).autoConfig();
} catch (JoranException je) {
Util.report("Failed to auto configure default logger context", je);
}
if (!StatusUtil.contextHasStatusListener(defaultLoggerContext)) {
StatusPrinter.printInCaseOfErrorsOrWarnings(defaultLoggerContext);
}
// 对ContextSelectorStaticBinder类进行初始化,
// 这里判断选择器,其实追一下源码什么也没做
contextSelectorBinder.init(defaultLoggerContext, KEY);
initialized = true;
} catch (Exception t) {
Util.report("Failed to instantiate [" + LoggerContext.class.getName() + "]", t);
}
}
走完init()StaticLoggerBinder就初始化完成了,然后进入到getLoggerFactory():
public ILoggerFactory getLoggerFactory() {
//如果没有进行初始化或者初始化出错(抛异常了,没有执行上面的initialized = true)直接返回默认的LoggerContext
if (!initialized) {
return defaultLoggerContext;
}
if (contextSelectorBinder.getContextSelector() == null) {
throw new IllegalStateException("contextSelector cannot be null. See also " + NULL_CS_URL);
}
// 返回刚才初始化的ContextSelectorStaticBinder类他还是使用的是已经初始化的defaultLoggerContext,然后返回一个LoggerContext,其实这里大多数还是使用的默认的defaultLoggerContext
return contextSelectorBinder.getContextSelector().getLoggerContext();
}
最后返回一个LoggerContext。到这里slf4j和logback绑定上了。说了这么多其实就是为了让Slf4j的LoggerFactory可以拿到Logback的LoggerContext的日志工厂对象。StaticLoggerBinder类只是为了让他们可以对接和对LoggerContext的初始化。
如果我不想要slf4j直接使用logback呢?
LoggerContext loggerContext = new LoggerContext();
new ContextInitializer(loggerContext).autoConfig();
Logger logger = loggerContext.getLogger(Test.class);
logger.info("test logback logger");
这样也是可以的。
Logback是如何创建Logger的?
注:我看的Logback版本是1.2.3(logback-core 和logback-classic 都是1.2.3)不同的版本有一些不一样但是大体逻辑是差不多的。
------------------------------------------------------我是分割线------------------------------------------------------
根据上面的可以看出 logback的LoggerContext就是一个日志工厂,因为上面的getLoggerFactory()最终返回的是defaultLoggerContext对象,说明LoggerContext是实现了ILoggerFactory接口的,那这个日志工厂是如何创建的Logger对象的呢?还有为什么Logger直接可以有父子层级关系?
LoggerContext类除了实现ILoggerFactory接口之外,还实现了LifeCycle接口,并继承自ContextBase类
补充:前面说到StaticLoggerBinder创建了LoggerContext,StaticLoggerBinder是单例的而每次都是通过他的getLoggerFactory()方法获取他的defaultLoggerContext所以LoggerContext也是单例的,所以我们每次LoggerFactory.getLogger(xxx)使用的LoggerContext也单例的。
在StaticLoggerBinder被创建的时候,defaultLoggerContext对象也被创建只是还未被初始化。
private LoggerContext defaultLoggerContext = new LoggerContext();
我们来看看LoggerContext()是如何创建的,先看构造器:
public LoggerContext() {
super();
// 初始化loggerCache 缓存所有创建的Logger对象
this.loggerCache = new ConcurrentHashMap<String, Logger>();
// 是一个LoggerContext的VO对象,保存了LoggerContext的一些值
this.loggerContextRemoteView = new LoggerContextVO(this);
// 对根Logger进行初始化
this.root = new Logger(Logger.ROOT_LOGGER_NAME, null, this);
//设置根Logger的日志级别
this.root.setLevel(Level.DEBUG);
// 将根Logger缓存起来
loggerCache.put(Logger.ROOT_LOGGER_NAME, root);
initEvaluatorMap();
//用来记录创建的Logger个数,现在有一个根Logger,所以是1
size = 1;
this.frameworkPackages = new ArrayList<String>();
}
我们平时使用是通过LoggerFactory.getLogger(xxx),来获取我们的Logger,又回到最开始就可以看出,实际是通过StaticLoggerBinder创建的LoggerContext日志工厂实例的getLogger()方法返回的Logger对象
public static Logger getLogger(String name) {
ILoggerFactory iLoggerFactory = getILoggerFactory();
return iLoggerFactory.getLogger(name);
}
那我们来看LoggerContext的getLogger()方法是如何创建的:
@Override
public final Logger getLogger(final String name) {
// 判断Logger的名字不得为空
if (name == null) {
throw new IllegalArgumentException("name argument cannot be null");
}
// 如果请求的是根Logger那么直接返回根Logger
if (Logger.ROOT_LOGGER_NAME.equalsIgnoreCase(name)) {
return root;
}
//如果loggerCache缓存了我们想要的Logger对象那么就直接返回
Logger childLogger = (Logger) loggerCache.get(name);
if (childLogger != null) {
return childLogger;
}
int i = 0;
// 先定义一个局部变量的logger然后把根给他
Logger logger = root;
// 如果需要的Logger对象不存在那么就依次创建他的父子层级关系的Logger对象,
// 直到无法再通过分割符去分割子Logger为止,返回最终的Logger对象
String childName;
while (true) {
/**
* LoggerNameUtil工具类主要在这里起到一个分割Logger名字的一个作用
* 在下面我稍微修改了一下,但是原理和功能没有改变,只是方便阅读
*/
//这里从name的索引i开始返回name的分隔符索引
int h = LoggerNameUtil.getSeparatorIndexOf(name, i);
if (h == -1) {
// 如果从name的索引i开始没有找到分隔符的话,name就是childName
childName = name;
} else {
//否则找到了从0开始到分割符截取给childName
childName = name.substring(0, h);
}
// i指向当前找到的分隔符的下一个索引,为下次分割做准备
i = h + 1;
//加锁创建logger的子Logger(第一次logger是root根Logger)
synchronized (logger) {
//如果当前logger有对应的子Logger对象则不创建
childLogger = logger.getChildByName(childName);
if (childLogger == null) {
//这里会创建logger的子Logger并且会把自己的Level给到子Logger
childLogger = logger.createChildByName(childName);
//创建后缓存起来
loggerCache.put(childName, childLogger);
//创建数量自增一
incSize();
}
}
//将当前子Logger给logger下次循环的时候会创建他的子Logger
logger = childLogger;
if (h == -1) {
return childLogger;
}
}
}
LoggerNameUtil工具类:
public class LoggerNameUtil {
/**
* 获取第一个分割符的索引
*/
public static int getFirstSeparatorIndexOf(String name) {
return getSeparatorIndexOf(name, 0);
}
/**
* 从fromIndex开始获取分隔符('.'、'$')的位置,
* 如果都不存在返回-1
* 如果都存在,取小的那个
*/
public static int getSeparatorIndexOf(String name, int fromIndex) {
int dotIndex = name.indexOf('.', fromIndex);
int dollarIndex = name.indexOf('$', fromIndex);
if (dotIndex == -1 && dollarIndex == -1)
return -1;
if (dotIndex == -1)
return dollarIndex;
if (dollarIndex == -1)
return dotIndex;
return Math.min(dotIndex, dollarIndex);
}
/**
* 返回名字被分隔符('.'、'$')分割之后的所有字符
* 例如:a.bb$ccc.d
* 返回 [a, bb, ccc, d]
*/
public static List<String> computeNameParts(String loggerName) {
List<String> partList = new ArrayList<String>();
int fromIndex = 0;
while (true) {
int index = getSeparatorIndexOf(loggerName, fromIndex);
if (index == -1) {
partList.add(loggerName.substring(fromIndex));
break;
}
partList.add(loggerName.substring(fromIndex, index));
fromIndex = index + 1;
}
return partList;
}
}
所以到此Logback创建Logger就告一段落了。如果你对创建父子层级的Logger哪里有点晕的话,我写了一个小的模拟demo希望可以帮到你理解:
public static void main(String[] args) {
String name = "ch.qos.logback.classic";
String loggerName = "ROOT";
String childName;
int i = 0;
while (true) {
int h = LoggerNameUtil.getSeparatorIndexOf(name, i);
if (h == -1) {
childName = name;
} else {
childName = name.substring(0, h);
}
i = h + 1;
// 模拟创建Logger
System.out.println("正在模拟创建:["+loggerName+"]的子Logger:"+childName);
loggerName = childName;
if (h == -1) {
System.out.println("最终返回Logger的名字:" + childName);
break;
}
}
}
Logger对象是如何记录日志的?
Logger实现的接口:
public final class Logger implements org.slf4j.Logger, LocationAwareLogger, AppenderAttachable<ILoggingEvent>, Serializable
他实现了org.slf4j.Logger的接口,所以我们使用slf4j的info(),实际是调logback的info()。还实现了AppenderAttachable<ILoggingEvent>接口,内部还有一个transient private AppenderAttachableImpl<ILoggingEvent> aai;字段,所以AppenderAttachable接口的方法其实是由Logger代理aai的真实对象来完成操作的,这里用到了静态代理模式
Logger的字段介绍:
//该类的完全限定名
public static final String FQCN = ch.qos.logback.classic.Logger.class.getName();
// Logger 的名字
private String name;
// 该Logger的分配级别,当配置文件中没有配置时,这个分配级别可以为null
transient private Level level;
// effectiveLevelInt是该Logger的生效级别,会从父Logger继承得到
transient private int effectiveLevelInt;
// 父Logger
transient private Logger parent;
// 子Logger
transient private List<Logger> childrenList;
// 所依附的所有Appender集合
transient private AppenderAttachableImpl<ILoggingEvent> aai;
// 是否继承父类Logger的Appender(为true的话如果子Logger写了日志父Logger也会写)
transient private boolean additive = true;
// 日志上下文,就是前面说的单例的LoggerContext
final transient LoggerContext loggerContext;
我们来看常用的info()方法:
public void info(String msg) {
filterAndLog_0_Or3Plus(FQCN, null, Level.INFO, msg, null, null);
}
我们的消息传递了进来又调用了filterAndLog_0_Or3Plus()方法:
private void filterAndLog_0_Or3Plus(final String localFQCN, final Marker marker, final Level level, final String msg, final Object[] params,
final Throwable t) {
// 请求TurboFilter来判断是否允许记录这次日志信息
final FilterReply decision = loggerContext.getTurboFilterChainDecision_0_3OrMore(marker, this, level, msg, params, t);
/** 如果筛选的状态是中立(NEUTRAL)的那就判断当前Logger生效级别和传递过来的level级别的大小
* 如果生效级别比传递的level级别大就什么都不做
* 如果筛选结果是拒绝(DENY)也什么都不做
*/
if (decision == FilterReply.NEUTRAL) {
if (effectiveLevelInt > level.levelInt) {
return;
}
} else if (decision == FilterReply.DENY) {
return;
}
// 构建日志事件LoggingEvent和Append
buildLoggingEventAndAppend(localFQCN, marker, level, msg, params, t);
}
该方法首先要请求TurboFilter来判断是否允许记录这次日志信息。TurboFilter是快速筛选的组件,筛选发生在LoggingEvent创建之前,这种设计也是为了提高性能 ,经过筛选再进行 构建日志事件LoggingEvent和Append
private void buildLoggingEventAndAppend(final String localFQCN, final Marker marker, final Level level, final String msg, final Object[] params,
final Throwable t) {
// 创建日志事件对象
LoggingEvent le = new LoggingEvent(localFQCN, this, level, msg, t, params);
le.setMarker(marker);
//构建Appender对象
callAppenders(le);
}
创建完日志对象后将日志对象给callAppenders()方法,并构建Appender,因为Appender对象一些操作需要日志事件对象并且Appender不止有一个
public void callAppenders(ILoggingEvent event) {
int writes = 0;
//每次循环都会调用当前Logger的appendLoopOnAppenders(event)方法
//然后再指向自己的父Logger再去调用,知道父Logger的additive为false
for (Logger l = this; l != null; l = l.parent) {
writes += l.appendLoopOnAppenders(event);
if (!l.additive) {
break;
}
}
// 如果一个Appender都没有和当前Logger关联(依附)就走这里
// 这里会抛出一个警告说没有一个Appender和当前Logger进行关联
if (writes == 0) {
loggerContext.noAppenderDefinedWarning(this);
}
}
该方法会调用此Logger关联的所有Appender,而且还会调用所有父Logger关联的Appender,直到遇到父Logger的additive属性设置为false为止,这也是为什么如果子Logger和父Logger都关联了同样的Appender,则日志信息会重复记录的原因 ,这里每次都会去调用appendLoopOnAppenders(event)方法,还把刚才创建的LoggingEvent对象(LoggingEvent对象里承载了日志信息等数据,最后输出的日志信息也来源于这个类)给他了。所以我们看看appendLoopOnAppenders(event)方法:
private int appendLoopOnAppenders(ILoggingEvent event) {
if (aai != null) {
return aai.appendLoopOnAppenders(event);
} else {
return 0;
}
}
这里又调用了aai的appendLoopOnAppenders(event)方法,就是说,上层有个循环,那么会调用每个父Logger的这个方法,其实这个方法是调用当前Logger所关联(依附)的所有的Appender的doAppend()方法。
public int appendLoopOnAppenders(E e) {
int size = 0;
final Appender<E>[] appenderArray = appenderList.asTypedArray();
final int len = appenderArray.length;
for (int i = 0; i < len; i++) {
// 在这里循环遍历的调用当前Logger依附的所有Appender的doAppend(e)方法
// LoggingEvent对象也给了这个方法
appenderArray[i].doAppend(e);
size++;
}
return size;
}
我们可以看到AppenderAttachableImpl类里有个appenderList属性,里面包含了当前Logger依附的所有的Appender,这个方法最终返回当前Logger依附的Appender的个数
到此我们知道,Logger是最终调用自己和自己的父Logger(直到父Logger的additive属性为false)的所有所依附的Appender的doAppend(e)方法来进行记录日志的。
你是否有疑问,Logger什么时候依附(关联)的Appender的?应该(我的猜测)在我们前面说到的加载配置文件的时候就创建缓存了(缓存到了那个defaultLoggerContext就是后面我们使用的LoggerContext)相关的Logger并将它的Appender依附上了:
new ContextInitializer(defaultLoggerContext).autoConfig();
Appender的doAppend(e)是如何记录日志的?
上集我们说到,Logger最终会调用自己和自己的父Logger所依附的所有Appender的doAppend(e)的方法来委托Appender组件来记录日志。我们来刨根问底,Appender的doAppend(e)方法是如何记录日志的?
我们继续来看代码:
public int appendLoopOnAppenders(E e) {
int size = 0;
final Appender<E>[] appenderArray = appenderList.asTypedArray();
final int len = appenderArray.length;
for (int i = 0; i < len; i++) {
// 在这里循环遍历的调用当前Logger依附的所有Appender的doAppend(e)方法
// LoggingEvent对象也给了这个方法
appenderArray[i].doAppend(e);
size++;
}
return size;
}
我们进入doAppend(e)
void doAppend(E event) throws LogbackException;
发现我们进入到了一个Appender接口的接口,这是在面向接口编程,具体的doAppend的逻辑还在具体的Appender实现类里,我们来看一下Appender的架构图
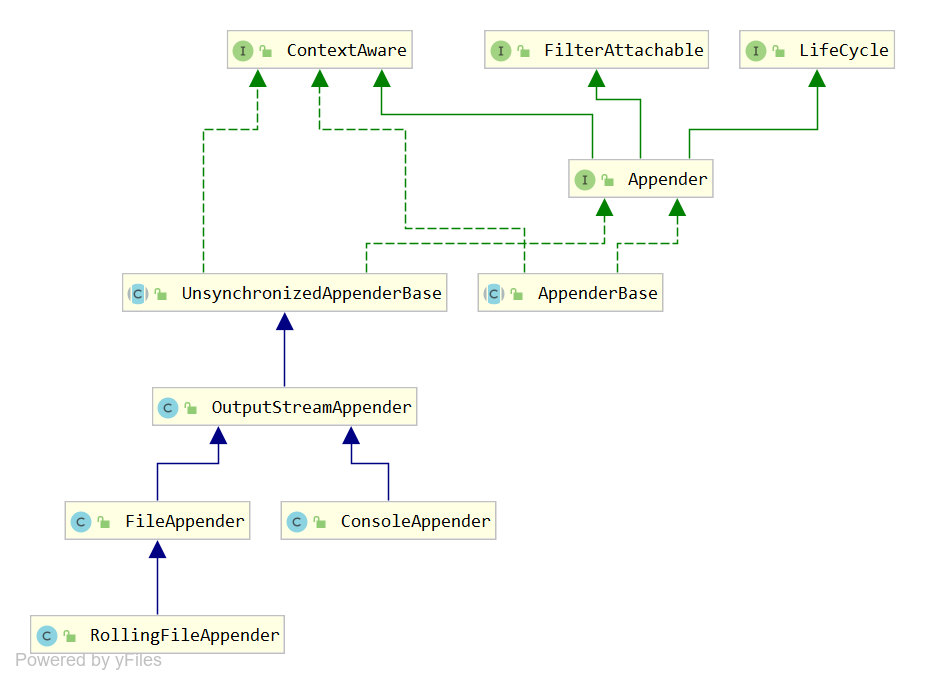
Appender的架构图很庞大,我列了几个常用的来进一步学习。
-
Appender接口有两个实现类UnsynchronizedAppenderBase和AppenderBase,顾名思义他们俩一个是非同步的一个是同步的,一个doAppend方法加了synchronized,一个没有
-
UnsynchronizedAppenderBase,Appender接口继承了FilterAttachable接口,UnsynchronizedAppenderBase中持有一个 FilterAttachableImpl类的实例,所以可以委托他来调用FilterAttachable中的方法,所以我们使用logback的配置文件时,可以在Appender中添加filter。这个和之前Logger调用Appender的逻辑是一样的,用到了静态代理模式。
-
OutputStreamAppender ,它继承UnsynchronizedAppenderBase,是最基本的以流的形式输出的Appender,内部有一个OutputStream流。并且我们都知道,在配置文件配置appender的时候,还需要配置encoder来格式化日志信息,所以内部还有Encoder,用来在写出日志之前对日志信息进行格式化用的。他的实现类有我们最常用的FileAppender、ConsoleAppender、和RollingFileAppender。
我们先来看看UnsynchronizedAppenderBase的doAppend方法是如何实现的,因为他的实现类都会先调它
public void doAppend(E eventObject) {
//这是防止Appender重复调用doAppend方法,不是重点
if (Boolean.TRUE.equals(guard.get())) {
return;
}
try {
guard.set(Boolean.TRUE);
// 检查Appender对象的状态
if (!this.started) {
if (statusRepeatCount++ < ALLOWED_REPEATS) {
addStatus(new WarnStatus("Attempted to append to non started appender [" + name + "].", this));
}
return;
}
// 使用我们上面说的FilterAttachableImpl的实例来检查过滤器Filter是否满足条件
if (getFilterChainDecision(eventObject) == FilterReply.DENY) {
return;
}
// 最后调用他的具体实现类的append()方法
this.append(eventObject);
} catch (Exception e) {
if (exceptionCount++ < ALLOWED_REPEATS) {
addError("Appender [" + name + "] failed to append.", e);
}
} finally {
guard.set(Boolean.FALSE);
}
}
这里只是做了Appender的状态和过滤检查,最后还是调用了他的具体实现类的append()方法。这里的OutputStreamAppender就是我们常用的他的实现类,我们进去看看:
@Override
protected void append(E eventObject) {
if (!isStarted()) {
return;
}
subAppend(eventObject);
}
这里只做了状态判断,就直接调他的subAppend(eventObject);方法了:
protected void subAppend(E event) {
if (!isStarted()) {
return;
}
try {
// 做了预处理
if (event instanceof DeferredProcessingAware) {
((DeferredProcessingAware) event).prepareForDeferredProcessing();
}
// 对输出的日志信息用encoder进行格式化
byte[] byteArray = this.encoder.encode(event);
//调用写出方法写出到输出流
writeBytes(byteArray);
} catch (IOException ioe) {
// as soon as an exception occurs, move to non-started state
// and add a single ErrorStatus to the SM.
this.started = false;
addStatus(new ErrorStatus("IO failure in appender", this, ioe));
}
}
这里对日志信息进行格式化后调用writeBytes(byteArray);写出:
private void writeBytes(byte[] byteArray) throws IOException {
if(byteArray == null || byteArray.length == 0)
return;
//加锁,防止多个线程同时操作同一个流
lock.lock();
try {
//将格式化好的日志信息写出到输出流中
this.outputStream.write(byteArray);
if (immediateFlush) {
this.outputStream.flush();
}
} finally {
lock.unlock();
}
}
到此我们知道了doAppend是如何打印日志的了,OutputStreamAppender 的子类分别添加了一下特殊的功能,比如向控制台写日志,向文件写日志,按照一定的滚动策略写日志等。。最后都是调用了这里writeBytes方法写到流中,只是流是具体的流了。如果你对其他的Appender感兴趣可以研究一下。
logback是如何初始化框架的?
前面我们不是有疑问,Logger的Appender是什么时候依附到Logger的?Appender的Filter和Encoder又是何时关联起来的?我们前面猜测是在加载配置文件的时候,进行了一系列初始化以后完成了这些关联操作,最后才返回日志工厂LoggerContext。现在让我们来探究一下。
我们来回顾一下slf4j和logback对接的时候logback返回给了slf4j一个ILoggerFactory的日志工厂实例,就是我们的LoggerContext实例:
StaticLoggerBinder.getSingleton().getLoggerFactory();
我们当时分析StaticLoggerBinder这个类的静态代码块中调用了init()的初始化方法:
static {
SINGLETON.init();
}
void init() {
try {
try {
// 委托ContextInitializer类对defaultLoggerContext进行初始化。这里如果找到了任一配置文件,就会根据配置文件去初始化LoggerContext,如果没找到,会使用默认配置
new ContextInitializer(defaultLoggerContext).autoConfig();
} catch (JoranException je) {
Util.report("Failed to auto configure default logger context", je);
}
if (!StatusUtil.contextHasStatusListener(defaultLoggerContext)) {
StatusPrinter.printInCaseOfErrorsOrWarnings(defaultLoggerContext);
}
// 对ContextSelectorStaticBinder类进行初始化,
// 这里判断选择器,其实追一下源码什么也没做
contextSelectorBinder.init(defaultLoggerContext, KEY);
initialized = true;
} catch (Exception t) {
Util.report("Failed to instantiate [" + LoggerContext.class.getName() + "]", t);
}
}
也就是说,在这个类加载的时候就进行对框架初始化操作,我们知道LoggerContext里缓存了所有的Logger对象,Logger对象又关联了Appender,Appender又关联了他的过滤器和Encoder。所以我们可以推测,这里委托ContextInitializer类对defaultLoggerContext进行初始化,其实是去读取了配置文件,创建了所有的相关对象缓存到了LoggerContext中
我们进去ContextInitializer的构造方法看看:
public ContextInitializer(LoggerContext loggerContext) {
this.loggerContext = loggerContext;
}
这是把StaticLoggerBinder类创建好的loggerContext给到自己的loggerContext属性。什么也没做。别急,我们再看看后面调用的.autoConfig()这个方法自动配置,一看名字就知道有点东西:
public void autoConfig() throws JoranException {
//这里其实什么都没做,可以自己追一下
StatusListenerConfigHelper.installIfAsked(loggerContext);
//查找默认配置文件,比如logback.xml文件
URL url = findURLOfDefaultConfigurationFile(true);
if (url != null) {
//如果找到了调用
configureByResource(url);
} else {
//如果没有找到用SPI的机制查找Configurator.class的配置类
Configurator c = EnvUtil.loadFromServiceLoader(Configurator.class);
if (c != null) {
//如果有相关的配置类把loggerContext给它让他做配置
try {
c.setContext(loggerContext);
c.configure(loggerContext);
} catch (Exception e) {
throw new LogbackException(String.format("Failed to initialize Configurator: %s using ServiceLoader", c != null ? c.getClass()
.getCanonicalName() : "null"), e);
}
} else {
//如果既没有找到配置文件,也没有配置类就使用BasicConfigurator的配置类
BasicConfigurator basicConfigurator = new BasicConfigurator();
basicConfigurator.setContext(loggerContext);
basicConfigurator.configure(loggerContext);
}
}
}
我们来看一下findURLOfDefaultConfigurationFile(true)方法是如何查找配置文件的:
public URL findURLOfDefaultConfigurationFile(boolean updateStatus) {
//获取一个类加载器
ClassLoader myClassLoader = Loader.getClassLoaderOfObject(this);
//查找系统的配置文件 logback.configurationFile
URL url = findConfigFileURLFromSystemProperties(myClassLoader, updateStatus);
if (url != null) {
return url;
}
//查找测试配置文件
url = getResource(TEST_AUTOCONFIG_FILE, myClassLoader, updateStatus);
if (url != null) {
return url;
}
//查找GROOVY配置文件
url = getResource(GROOVY_AUTOCONFIG_FILE, myClassLoader, updateStatus);
if (url != null) {
return url;
}
//查找默认的配置文件logback.xml
return getResource(AUTOCONFIG_FILE, myClassLoader, updateStatus);
}
这里会逐级去查找配置文件,调用getResource()方法来加载配置文件,其实跟进Loader.getResource(filename, myClassLoader)方法,底层还是通过classLoader.getResource(resource)来加载的配置文件。加载完配置文件返回配置文件的URL对象。回到上面:
别急我们先来看看如果加载到配置文件会怎么做?因为我们一般都会用配置文件来配置我们项目的日志:
public void configureByResource(URL url) throws JoranException {
//做了一个判空,前面都不为空才进这个方法,所以这里不会为空
if (url == null) {
throw new IllegalArgumentException("URL argument cannot be null");
}
final String urlString = url.toString();
//如果是groovy配置文件,有相应的配置loggerContext方法
if (urlString.endsWith("groovy")) {
if (EnvUtil.isGroovyAvailable()) {
GafferUtil.runGafferConfiguratorOn(loggerContext, this, url);
} else {
StatusManager sm = loggerContext.getStatusManager();
sm.add(new ErrorStatus("Groovy classes are not available on the class path. ABORTING INITIALIZATION.", loggerContext));
}
} else if (urlString.endsWith("xml")) {
//如果是xml,可能是logback.xml或者logback-test.xml\
//创建一个JoranConfigurator对象,然后把loggerContext和配置文件给它委托他去给loggerContext配置
JoranConfigurator configurator = new JoranConfigurator();
configurator.setContext(loggerContext);
configurator.doConfigure(url);
} else {
throw new LogbackException("Unexpected filename extension of file [" + url.toString() + "]. Should be either .groovy or .xml");
}
}
到此先停一下,我们知道了,logback在加载StaticLoggerBinder类的时候,进行的初始化,内部有一个静态代码块,代用init方法,然后委托ContextInitializer类的自动配置方法对StaticLoggerBinder创建的模式LoggerContext对象进行配置,如何配置的呢?先查找配置文件,我们一般是logback.xml做的配置文件,然后返回文件的URL,判断文件是否没有找到。
如果没有找到通过SPI机制查找是否有相关的配置类,如果还没有就用默认的基本配置BasicConfigurator类来对LoggerContext进行配置。
如果找到文件了呢?就判断文件是什么类型的一般我们使用的都是xml,然后使用JoranConfigurator配置类来对配置文件解析和loggerContext的配置。
JoranConfigurator配置类如何进行配置?
接下来有点打破砂锅问到底了,其实我们想一想xml文件多半是使用SAX流的形式处理配置文件,然后再以一种栈的结构来对LoggerContext进行配置。
这里进入JoranConfigurator的doConfigure方法看一下如何配置的xml配置文件:
public final void doConfigure(URL url) throws JoranException {
InputStream in = null;
try {
//通知容器使用URL配置
informContextOfURLUsedForConfiguration(getContext(), url);
//获取配置文件的连接
URLConnection urlConnection = url.openConnection();
urlConnection.setUseCaches(false);
in = urlConnection.getInputStream();
doConfigure(in, url.toExternalForm());
} catch (IOException ioe) {
String errMsg = "Could not open URL [" + url + "].";
addError(errMsg, ioe);
throw new JoranException(errMsg, ioe);
} finally {
if (in != null) {
try {
in.close();
} catch (IOException ioe) {
String errMsg = "Could not close input stream";
addError(errMsg, ioe);
throw new JoranException(errMsg, ioe);
}
}
}
}
这里我们可以看到,这里获取了配置文件的连接再转换成InputStream流然后调用doConfigure方法:
public final void doConfigure(InputStream inputStream, String systemId) throws JoranException {
InputSource inputSource = new InputSource(inputStream);
inputSource.setSystemId(systemId);
doConfigure(inputSource);
}
这里通过配置文件的流创建了一个InputSource对象,然后把这个对象给了doConfigure(inputSource);方法:
public final void doConfigure(final InputSource inputSource) throws JoranException {
long threshold = System.currentTimeMillis();
//将loggercontext和inputSource给到SaxEventRecorder
SaxEventRecorder recorder = new SaxEventRecorder(context);
//在这里配置文件流已经被转换成了SAX流了,并保存在了recorder.saxEventList字段里
recorder.recordEvents(inputSource);
doConfigure(recorder.saxEventList);
// no exceptions a this level
StatusUtil statusUtil = new StatusUtil(context);
if (statusUtil.noXMLParsingErrorsOccurred(threshold)) {
addInfo("Registering current configuration as safe fallback point");
registerSafeConfiguration(recorder.saxEventList);
}
}
我们可以看到这里创建了一个SaxEventRecorder对象,并把配置文件流和loggercontext给到了它,所以我们可以肯定,这是使用SAX以流的方式来解析XML文件并配置loggercontext对象的,我们进入doConfigure方法:
public void doConfigure(final List<SaxEvent> eventList) throws JoranException {
buildInterpreter();
// 防止重复配置
synchronized (context.getConfigurationLock()) {
interpreter.getEventPlayer().play(eventList);
}
}
我们看到在配置之前调用了buildInterpreter方法:
protected void buildInterpreter() {
// 创建了一个SimpleRuleStore类
RuleStore rs = new SimpleRuleStore(context);
addInstanceRules(rs);
// 对interpreter类进行初始化
this.interpreter = new Interpreter(context, rs, initialElementPath());
InterpretationContext interpretationContext = interpreter.getInterpretationContext();
interpretationContext.setContext(context);
addImplicitRules(interpreter);
addDefaultNestedComponentRegistryRules(interpretationContext.getDefaultNestedComponentRegistry());
}
这里创建了一个SimpleRuleStore类并把LoggerContext给了它,然后掉用了一个抽象方法addInstanceRules(rs),我们是从前面JoranConfigurator跟过来的,所以这里应该进入他的这个方法:
@Override
public void addInstanceRules(RuleStore rs) {
// 父类也是如此
super.addInstanceRules(rs);
rs.addRule(new ElementSelector("configuration"), new ConfigurationAction());
rs.addRule(new ElementSelector("configuration/contextName"), new ContextNameAction());
rs.addRule(new ElementSelector("configuration/contextListener"), new LoggerContextListenerAction());
rs.addRule(new ElementSelector("configuration/insertFromJNDI"), new InsertFromJNDIAction());
rs.addRule(new ElementSelector("configuration/evaluator"), new EvaluatorAction());
rs.addRule(new ElementSelector("configuration/appender/sift"), new SiftAction());
rs.addRule(new ElementSelector("configuration/appender/sift/*"), new NOPAction());
rs.addRule(new ElementSelector("configuration/logger"), new LoggerAction());
rs.addRule(new ElementSelector("configuration/logger/level"), new LevelAction());
rs.addRule(new ElementSelector("configuration/root"), new RootLoggerAction());
rs.addRule(new ElementSelector("configuration/root/level"), new LevelAction());
rs.addRule(new ElementSelector("configuration/logger/appender-ref"), new AppenderRefAction<ILoggingEvent>());
rs.addRule(new ElementSelector("configuration/root/appender-ref"), new AppenderRefAction<ILoggingEvent>());
rs.addRule(new ElementSelector("*/if"), new IfAction());
rs.addRule(new ElementSelector("*/if/then"), new ThenAction());
rs.addRule(new ElementSelector("*/if/then/*"), new NOPAction());
rs.addRule(new ElementSelector("*/if/else"), new ElseAction());
rs.addRule(new ElementSelector("*/if/else/*"), new NOPAction());
if (PlatformInfo.hasJMXObjectName()) {
rs.addRule(new ElementSelector("configuration/jmxConfigurator"), new JMXConfiguratorAction());
}
rs.addRule(new ElementSelector("configuration/include"), new IncludeAction());
rs.addRule(new ElementSelector("configuration/consolePlugin"), new ConsolePluginAction());
rs.addRule(new ElementSelector("configuration/receiver"), new ReceiverAction());
}
我们可以看到,这是将我们在xml中配置的元素给SimpleRuleStore对象,然后还有对应匹配的Action对象。也就是说,我们不同的元素标签将由不同的Action对象来解析完成。我们回到buildInterpreter()方法:
protected void buildInterpreter() {
RuleStore rs = new SimpleRuleStore(context);
addInstanceRules(rs);
//对interpreter字段实例化
this.interpreter = new Interpreter(context, rs, initialElementPath());
//创建一个interpretationContext并把context给他代理完成配置
InterpretationContext interpretationContext = interpreter.getInterpretationContext();
interpretationContext.setContext(context);
addImplicitRules(interpreter);
addDefaultNestedComponentRegistryRules(interpretationContext.getDefaultNestedComponentRegistry());
}
然后我们回到:
public void doConfigure(final List<SaxEvent> eventList) throws JoranException {
buildInterpreter();
// 防止重复配置
synchronized (context.getConfigurationLock()) {
interpreter.getEventPlayer().play(eventList);
}
}
这里委托了 EventPlayer来处理SAX流:
public void play(List<SaxEvent> aSaxEventList) {
eventList = aSaxEventList;
SaxEvent se;
for (currentIndex = 0; currentIndex < eventList.size(); currentIndex++) {
se = eventList.get(currentIndex);
if (se instanceof StartEvent) {
interpreter.startElement((StartEvent) se);
// invoke fireInPlay after startElement processing
interpreter.getInterpretationContext().fireInPlay(se);
}
if (se instanceof BodyEvent) {
// invoke fireInPlay before characters processing
interpreter.getInterpretationContext().fireInPlay(se);
interpreter.characters((BodyEvent) se);
}
if (se instanceof EndEvent) {
// invoke fireInPlay before endElement processing
interpreter.getInterpretationContext().fireInPlay(se);
interpreter.endElement((EndEvent) se);
}
}
}
这里对SAX流的所有元素进行了遍历然后又把元素给到了interpreter来解析处理,我们进入interpreter.startElement((StartEvent) se);看看:
public void startElement(StartEvent se) {
//设置文档定位器
setDocumentLocator(se.getLocator());
//继续调用
startElement(se.namespaceURI, se.localName, se.qName, se.attributes);
}
private void startElement(String namespaceURI, String localName, String qName, Attributes atts) {
//获取元素的TagName
String tagName = getTagName(localName, qName);
//将该元素进栈一会会在endElement中出栈
elementPath.push(tagName);
if (skip != null) {
// every startElement pushes an action list
pushEmptyActionList();
return;
}
// 通过RuleStore来匹配一下,得到处理的Action列表
List<Action> applicableActionList = getApplicableActionList(elementPath, atts);
if (applicableActionList != null) {
actionListStack.add(applicableActionList);
callBeginAction(applicableActionList, tagName, atts);
} else {
// every startElement pushes an action list
pushEmptyActionList();
String errMsg = "no applicable action for [" + tagName + "], current ElementPath is [" + elementPath + "]";
cai.addError(errMsg);
}
}
这个方法先得到元素的TagName,然后通过RuleStore来匹配一下,得到处理的Action列表,然后调用callBeginAction()方法来处理
void callBeginAction(List<Action> applicableActionList, String tagName, Attributes atts) {
//如果Action列表是空的什么都不做
if (applicableActionList == null) {
return;
}
//迭代遍历Action列表
Iterator<Action> i = applicableActionList.iterator();
while (i.hasNext()) {
Action action = (Action) i.next();
try {
//调用begin方法
action.begin(interpretationContext, tagName, atts);
} catch (ActionException e) {
skip = elementPath.duplicate();
cai.addError("ActionException in Action for tag [" + tagName + "]", e);
} catch (RuntimeException e) {
skip = elementPath.duplicate();
cai.addError("RuntimeException in Action for tag [" + tagName + "]", e);
}
}
}
这里会循环调用Action的begin然后让他处理相关的元素对应的逻辑。endElement方法也是大概如此,可自行探究
到此我们知道。JoranConfigurator配置类会先把配置文件流转换成SAX流,然后转换成SaxEvent事件,然后在配置之前,先初始化了interpreter解析器。解析器中有一个RuleStore规则存储对象,也就是说解析器解析的所有元素都是由这个规则存储对应元素的Action对象来处理(比如将我们的Logger和Appender绑定)然后加锁进行初始化,解析元素用一种栈的形式来进行解析。startElement方法进栈调用相关的Action的begin方法,startElement方法出栈调用相关的Action的end方法。最后完成初始化。
Action又是如何工作的?
前面我们说interpreter解析器最终会调用相关元素对应的Action对象来处理,那么是如何处理的呢?
我们选择LoggerAction做为案例来看一下吧。首先他继承自Action,实现了begin和end方法:
public void begin(InterpretationContext ec, String name, Attributes attributes) {
// Let us forget about previous errors (in this object)
inError = false;
logger = null;
//获取前面的LoggerContext
LoggerContext loggerContext = (LoggerContext) this.context;
// 日志名 这是会读取日志文件的name属性
String loggerName = ec.subst(attributes.getValue(NAME_ATTRIBUTE));
//判空
if (OptionHelper.isEmpty(loggerName)) {
inError = true;
String aroundLine = getLineColStr(ec);
String errorMsg = "No 'name' attribute in element " + name + ", around " + aroundLine;
addError(errorMsg);
return;
}
//通过loggerContext获取该日志对象,如果没有会自动创建
logger = loggerContext.getLogger(loggerName);
// level属性并判断如果不为空为前面创建的logger对象设置
String levelStr = ec.subst(attributes.getValue(LEVEL_ATTRIBUTE));
if (!OptionHelper.isEmpty(levelStr)) {
if (ActionConst.INHERITED.equalsIgnoreCase(levelStr) || ActionConst.NULL.equalsIgnoreCase(levelStr)) {
addInfo("Setting level of logger [" + loggerName + "] to null, i.e. INHERITED");
logger.setLevel(null);
} else {
Level level = Level.toLevel(levelStr);
addInfo("Setting level of logger [" + loggerName + "] to " + level);
logger.setLevel(level);
}
}
//设置是否继承父logger,逻辑一样
String additivityStr = ec.subst(attributes.getValue(ActionConst.ADDITIVITY_ATTRIBUTE));
if (!OptionHelper.isEmpty(additivityStr)) {
boolean additive = OptionHelper.toBoolean(additivityStr, true);
addInfo("Setting additivity of logger [" + loggerName + "] to " + additive);
logger.setAdditive(additive);
}
ec.pushObject(logger);
}
这里对读到的一个logger标签元素进行了对该元素对象的初始化。
public void end(InterpretationContext ec, String e) {
if (inError) {
return;
}
Object o = ec.peekObject();
if (o != logger) {
addWarn("The object on the top the of the stack is not " + logger + " pushed earlier");
addWarn("It is: " + o);
} else {
ec.popObject();
}
}
这里做了一些检查最后从InterpretationContext中弹出该对象
其他的Action处理逻辑都大体一样,可以看看源码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号