
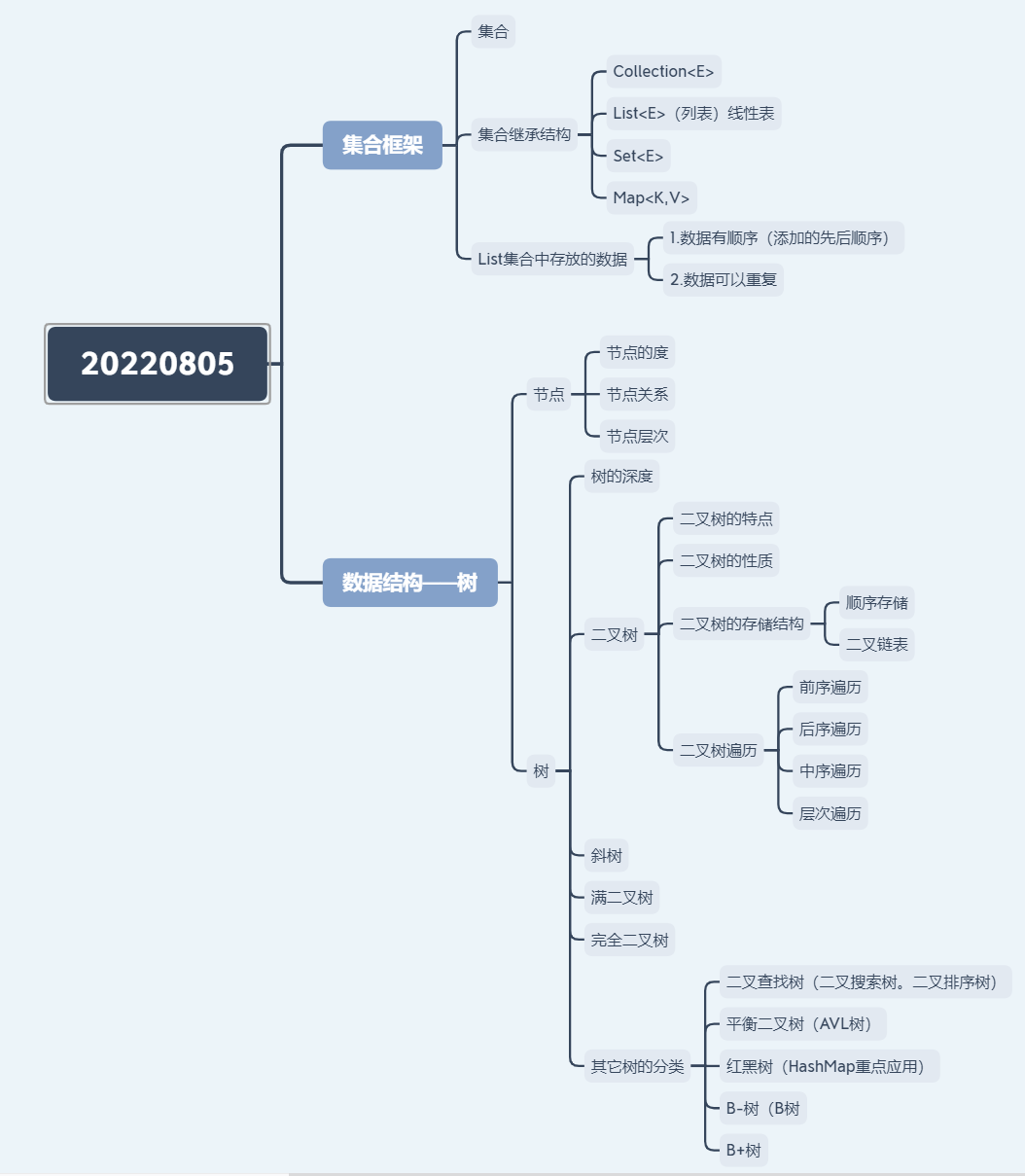
学习笔记——树
一、学习重点
二、学习内容
import java.util.ArrayList; import java.util.List; public class ArrayConvertUtil { public static Object[] toArrayConvert(List list) { Object[] objects = new Object[list.size()]; for (int i = 0; i < list.size(); i++) { objects[i] = list.get(i); } return objects; } public static List toListConvert(Object [] arr) { List list = new ArrayList(); for (Object o : arr) { list.add(o); } return list; } } import java.util.ArrayList; import java.util.List; public class Test { public static void main(String[] args) { List<Integer> l1 = new ArrayList<>(); l1.add(1); l1.add(2); l1.add(3); l1.add(4); l1.add(5); l1.add(1,-1); Object[] objects = ArrayConvertUtil.toArrayConvert(l1); System.out.println(objects[0]); } }
三、笔记内容
集合
前提知识:数据结构——树
节点:节点是数据结构中的基础,构成复杂数据结构的基本组成单位
树(tree):是n(n>=0)个结点的有限级,n=0,称为空树
在任意的非空数中:
1、有且仅有一个特定的称为根节点
2、当n>1时,其余节点可分为m个互不相交的有限集
定义树的时候
1、根节点是唯一的,不能存在多个根节点
2、子树的个数没有限制,但他们一定是互不相交的
树的定义中,使用了递归的方式。递归在树的学习过程中起着重要的作用。
节点的度:
节点拥有子节点的数量称为结点的度。
节点关系:
节点子树的根节点称为该节点的孩子结点。
相应该节点称为孩子结点的父节点(双亲结点)。
节点层次
树的深度:
树中节点的最大层数称之为树的深度或高度
二叉树:
二叉树是n个结点的有限集合,如果 n = 0 ,则称为空二叉树
二叉树的特点:
1、每个节点最多只有两颗子树,所以二叉树中不存在度大于2的节点
2、左子树和右子树是有顺序的,次序不能任意颠倒
3、即使树种某个节点只有一颗子树,也要区分它是左子树还是右子树
二叉树的性质:
1、在二叉树中第i层上最多有2^(i-1)个节点(i>=1)
2、二叉树中,如果深度为k,那么最多有2^k - 1个节点
3、n0 = n2 + 1 n0表示度数为0的节点,n2表示度数为2的节点数
4、在完全二叉树中,具有n个结点的完全二叉树的深度为[log2n]+1
其中[log2n]向下取整
5、若对含n个节点的完全二叉树从上到下且从左到右进行1至n的编号,
则对完全二叉树中任意一个编号为i的节点有如下特性
(1)若i= 1 ,则该节点是二叉树的根,无父节点,否则,编号为i/2的节点
(2)若2i > n ,则该节点无左孩子节点,否则,编号为2i的节点为其左孩子节点
(3)若2i +1 > n ,则该节点无右孩子节点,否则,编号为2i+1的节点为右孩子节点
斜树:
所有的节点都只有左子树的二叉树叫做左斜树。所有节点都是只有右子树的二叉树叫右斜树
满二叉树:
在一颗二叉树中,如果所有分支结点都存在左子树和右子树,并且所有的叶子都在同一层上,
这样的二叉树叫做满二叉树。
满二叉树特点:
1、叶子只能出现在下一层。
2、非叶子节点的度一定是2
3、在同样的深度的二叉树中。满二叉树的节点个数最多,叶子数最多
完全二叉树:
对一颗具有n个节点的二叉树按层编号,如果编号为i(1<= i <=n)同样深度的满二叉树中编号为i的结点位置完全相同。
这颗二叉树就称为完全二叉树。
二叉树的存储结构
1、顺序存储:使用一维数组存储二叉树的节点,并且节点的存储位置,就是数组的下标索引
当二叉树为完全二叉树时,节点刚好填满数组。
如果二叉树不是完全二叉树,采用顺序存储,顺序存储结构中已经出现了空间浪费的情况。
比如右斜树极端情况,采用顺序存储的方式是十分浪费空间。
顺序存储只适用于完全二叉树。
2.二叉链表
顺序存储不能满足二叉树的存储要求,采用链式存储。
二叉树的每个结点都有两个孩子。
可以将结点数据结构定义成一个数据和两个指针域。
数据结点:
二叉树遍历:重点考察
二叉树的遍历从根节点出发,按照某种次序依次访问二叉树中所有节点,使得每个结点被访问一次,且仅被访问一次。
二叉树的访问次序可以分为四种:
递归遍历。
自上而下,从左到右,每个结点会走三次。
前序遍历
从二叉树的根结点出发,按照先向左再向右的方向访问。(根左右)
后序遍历
从二叉树的根结点出发,先向左再向右的方向访问。(左右根)
中序遍历
从二叉树的根结点出发,按照先向左再向右访问。(左根右)
层次遍历
按照树的层次自上而下的遍历二叉树。ABCDEFGHIJ
class TreeNode<T> { T data; // 数据本身 TreeNode left; // 左孩子 TreeNode right; // 右孩子 public TreeNode(T data) { this.data = data; } // 前序遍历 // 传入的参数就是根节点 public static void preorder(TreeNode root){ if(root == null){ return; } System.out.println(root.data); // 递归 preorder(root.left); preorder(root.right); } // 中序遍历 public static void inorder(TreeNode root) { if(root == null){ return; } inorder(root.left); System.out.println(root.data); inorder(root.right); } // 后序 public static void postorder(TreeNode root){ if(root == null){ return; } postorder(root.left); postorder(root.right); System.out.println(root.data); } } public class Ch01 { public static void main(String[] args) { TreeNode<Integer> root = new TreeNode<>(1); root.left = new TreeNode(2); root.right = new TreeNode(3); root.left.left = new TreeNode(4); root.left.right = new TreeNode(5); root.right.left = new TreeNode(6); root.right.right = new TreeNode(7); // 前序遍历 System.out.println("----------前序遍历--------------"); TreeNode.preorder(root); System.out.println("----------中序遍历--------------"); TreeNode.inorder(root); System.out.println("----------后序遍历--------------"); TreeNode.postorder(root); } }
用栈
class Node { int value; Node left; Node right; public Node(int value) { this.value = value; } public static void preorder(Node head){ if(head != null){ Stack<Node> stack = new Stack<>(); stack.add(head); while(!stack.isEmpty()){ head = stack.pop(); System.out.print(head.value + "、"); if(head.right != null){ stack.push(head.right); } if(head.left != null){ stack.push(head.left); } } } System.out.println(); } } public class Ch02 { public static void main(String[] args) { Node root = new Node(1); root.left = new Node(2); root.right = new Node(3); root.left.left = new Node(4); root.left.right = new Node(5); root.right.left = new Node(6); root.right.right = new Node(7); Node.preorder(root); } }
其他的树分类:
1.二叉查找树(二叉搜索树。二叉排序树)
(1)若左子树不为空,左子树的所有的值小于它的根节点的值
(2)若右子树不为空,右子树的所有的值大于它的根节点的值
(3)左右子树也是一个二叉查找树
(4)没有键值相等的点
2.平衡二叉树(AVL树)
含有形同结点的二叉树的不同形态,找出一个查找平均长度最小的一颗二叉查找树
(1)要么是一颗空树,要么其根结点的左右子树的深度之差的值不超过1
(2)左右子树也都是平衡二叉树
(3)二叉树结点的平衡因子定义为该结点的左子树的深度减去右子树的深度。
平衡因子 = 左子树的深度 - 右子树的深度 -1 0 1
3.红黑树(HashMap重点应用)
自平衡的二叉树。又增加了一个颜色的属性。
结点的颜色只能是红色或黑色。
(1)根节点只能是黑色
(2)红黑树中,所有的叶子结点后面再接上左右两个空结点,保持算法的一致性,所有的空结点都是黑色
(3)其他的结点要么是黑色,要么是红色,红色结点的父节点和左右孩子结点都是黑色,黑红相间
(4)在任一颗子树中,从根节点向下走到空结点的路径上所经理的黑结点数相同,平衡二叉树
4.B-树(B树)
B-树是一种平衡多路查找树,它在文件系统中很有用。一颗 m 阶 B- 树
(1)树中每个子节点至多有m颗子树
(2)若根节点不是叶子结点,则至少有2棵子树
(3)除根节点外所有非终端结点至少有[m/2]棵子树
(4)每个节点的信息结构(A0,K1,A1,K2....Kn,An),其中n表示关键字个数
K为关键字,A是指针
(5)所有的叶子节点都出现在同一层次上,且不带任何信息。
5.B+树
B-树和B+树,后序在数据库阶段才会重点应用!!!
集合框架(重要)
集合:容器,存放数据的一个容器
使用集合的目的:更方便的存储和操作数据,CRUD。
集合继承结构
Collection<E>:存放单值的最大父接口
List<E>(列表)线性表:和数组类似,List可以动态增长,查找元素效率高
插入删除元素的效率低,因为会引起其他元素位置的改变。
Set<E>也是线性表,检索元素效率低,删除和插入的效率高,插入和删除不会引起
元素移位。
Map<K,V>:存放对值的最大父接口
Map(映射)用于保存具有映射关系的数据,Map保存着两组数据:key和value。
key和value都可以是任意的引用数据类型,但key不能重复。
List,Set继承自Collection,Map不是
import java.util.ArrayList; import java.util.Arrays; import java.util.List; /** * ArrayList:内部结构是一个数组 * * * */ public class Ch02 { public static void main(String[] args) { // 创建了一个ArrayList集合 // 开发中,一般情况下,使用多态创建集合 // 向上转型 List<Integer> l1 = new ArrayList<>(); // 集合的新增 l1.add(1); l1.add(2); l1.add(3); l1.add(4); l1.add(5); l1.add(1,-1); List<Integer> l2 = new ArrayList<>(); l2.add(-1); l2.add(-2); l2.add(-3); l2.add(-4); l2.add(-5); l2.add(1,100); l1.addAll(l2); // 清空集合 // 清空之后,集合中没有数据size==0,集合为null // l1.clear(); // l1.remove(Integer.valueOf(100)); l1.set(0,200); // Object[] objects = l1.toArray(); // System.out.println(l1.size()); // 直接打印集合对象 // System.out.println(l1); // System.out.println(l1.contains(-3)); // System.out.println(l1.get(0)); // System.out.println(l1.indexOf(1000)); // System.out.println(l1.isEmpty()); // 集合和数组之间的转换 // 数组--->集合 // int [] arr = new int[]{1,2,3,4,5}; List<Integer> integers = Arrays.asList(1, 2, 3, 4, 5); List<Integer> integers1 = List.of(1, 23, 4, 5); // List<int[]> arr1 = List.of(arr); // System.out.println(arr1.get(0)[0]); // 数组和集合之间的转换,建议自己封装一个工具类 } }
1.如果初始化集合尽量指定初始化容量,如果确定不了,默认指定为16(阿里规约)
2.使用泛型,数据的类型时候,一定要使用引用数据类型。
public static void main(String[] args) { List<Integer> l1 = new ArrayList<>(16); l1.add(1); l1.add(2); l1.add(3); l1.add(4); l1.add(5); l1.add(1,-1); Integer [] arr = new Integer[]{1,2,3,4,5}; List<Integer> arr1 = List.of(arr); List<Integer> integers = Arrays.asList(arr); }
List集合中存放的数据:
1.数据有顺序(添加的先后顺序)
2.数据可以重复

 浙公网安备 33010602011771号
浙公网安备 33010602011771号