


taskflow源码分析及功能定制
概述
Taskflow(https://github.com/taskflow/taskflow)是一个用于并行和异构任务编程的通用系统。它支持静态和动态任务图构建、条件任务编程以及GPU任务编程。该库最初由学术界发起,现在已经广泛应用在工业界,如英伟达、赛灵思等公司。该库是header-only的,无需复杂安装过程即可集成到项目中。
初识
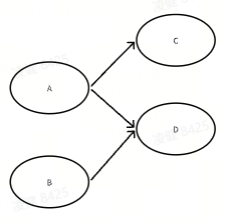
taskflow的拓扑图中的节点具有不同的类型,简单来说,没有返回值的节点称为静态节点,具有返回值的节点称为条件节点,它返回i则触发它的第i个后继节点的执行。
|
|
静态节点
|
条件节点
|
|
依赖关系
|
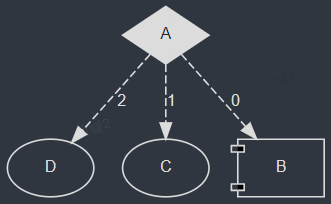
A是C的强依赖,A执行后会触发C的执行;
A和B是D的强依赖,A和B都执行后才会触发D的执行;
|
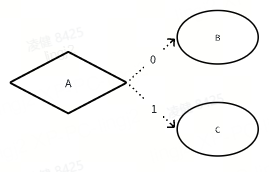
A是B和C的弱依赖,A返回0触发第0个后继节点B的执行, 返回1则触发第1个后继节点C的执行;
|
|
拓扑图
|
|
|
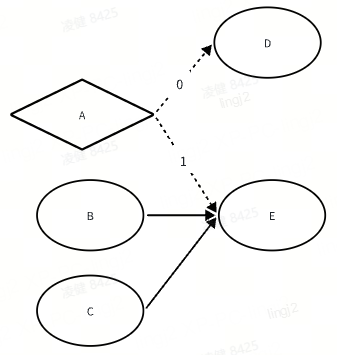
当某一个节点同时有强依赖和弱依赖节点时,它什么时候会被触发执行呢?
Rule1:某个节点所有的强依赖项都执行完后,该节点会被触发执行;
Rule2:某个节点任意一个弱依赖项执行完后,该节点会被触发执行;
如下图所示,某个时刻当A返回1的时候,E会被调度执行;另一个时刻B和C都执行完后,E也会被调度执行;也就是说一个节点在一次拓扑执行过程中是可以被重复多次触发的。
原理
我们先看一个简单的例子:
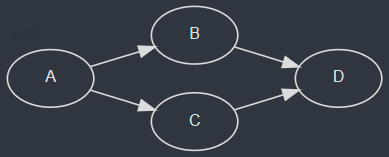
#include <taskflow/taskflow.hpp> // the only include you need int main(){ tf::Executor executor; tf::Taskflow taskflow("static"); auto [A, B, C, D] = taskflow.emplace( //the type of A,B,C,B is tf::Task []() { std::cout << "TaskA\n"; }, []() { std::cout << "TaskB\n"; }, []() { std::cout << "TaskC\n"; }, []() { std::cout << "TaskD\n"; } ); A.precede(B, C); // A runs before B and C D.succeed(B, C); // D runs after B and C executor.run(taskflow).wait(); return 0; }
g++ -std=c++17 simple.cpp -I. -O2 -pthread -o simple
在深入源码之前,我们先看一下各个类的定义(仅展示主要成员)。
类定义
Node类:
class Node { std::string _name; Topology* _topology {nullptr};//拓扑图 Node* _parent {nullptr}; //subflow的父结点,可先忽略 SmallVector<Node*> _successors;//后继 SmallVector<Node*> _dependents;//前驱 std::atomic<size_t> _join_counter {0}; //每个节点的入度,只有强依赖计算在内 handle_t _handle;//存储了节点类型及callable func size_t num_successors() const; size_t num_dependents() const; size_t num_strong_dependents() const; size_t num_weak_dependents() const; inline void Node::_precede(Node* v) { _successors.push_back(v); v->_dependents.push_back(this); } };
Topology类
class Topology { Taskflow& _taskflow; SmallVector<Node*> _sources;//拓扑图中的起始节点 std::atomic<size_t> _join_counter {0};//整个拓扑图中就绪节点的数量 }
Task类是Node的观察者,只有一个Node*成员变量,只是不想让用户接触底层的Node数据。
class Task { size_t num_successors() const; size_t num_dependents() const; size_t num_strong_dependents() const; size_t num_weak_dependents() const; template <typename... Ts> Task& precede(Ts&&... tasks); //用户调用的precede函数 template <typename... Ts> Task& succeed(Ts&&... tasks);//用户调用的succeed函数 Node* _node {nullptr}; };
worker类
class Worker { size_t _id; size_t _vtm;//受害者线程(被偷线程) Executor* _executor; std::thread* _thread;//绑定的线程 TaskQueue<Node*> _wsq;//本地就绪队列 };
Executor类
class Executor { std::vector<std::thread> _threads;//所有子线程 std::vector<Worker> _workers;//所有worker(和子线程绑定) std::list<Taskflow> _taskflows; TaskQueue<Node*> _wsq;//主线程的就绪队列 inline tf::Future<void> Executor::run(Taskflow& f);//用户调用的run函数 };
taskflow类
class Taskflow : public FlowBuilder { std::string _name; Graph _graph;//存储了所有Node std::queue<std::shared_ptr<Topology>> _topologies; } template <typename C, std::enable_if_t<is_static_task_v<C>, void>*> Task FlowBuilder::emplace(C&& c) { //用户调用的emplace函数,传入参数为callable func,返回Task return Task(_graph._emplace_back("", 0, nullptr, nullptr, 0, std::in_place_type_t<Node::Static>{}, std::forward<C>(c) )); }
Graph
class Graph { std::vector<Node*> _nodes;//存储了所有节点 Node* _emplace_back(ArgsT&&...);//创建节点并加入_nodes中 }
执行过程
Executor在构造时会创建N个子线程,加上主线程总共有N+1个线程,主线程会获取拓扑图中的起始节点并push进自己的就绪队列中,但是它不会执行任何节点。最开始worker线程的本地就绪队列都是空的,它们会从主线程的就绪队列中窃取节点并执行,执行完该节点后其后继节点的入度会减一,如果入度降为0便将该后继节点push进自己的就绪队列中。
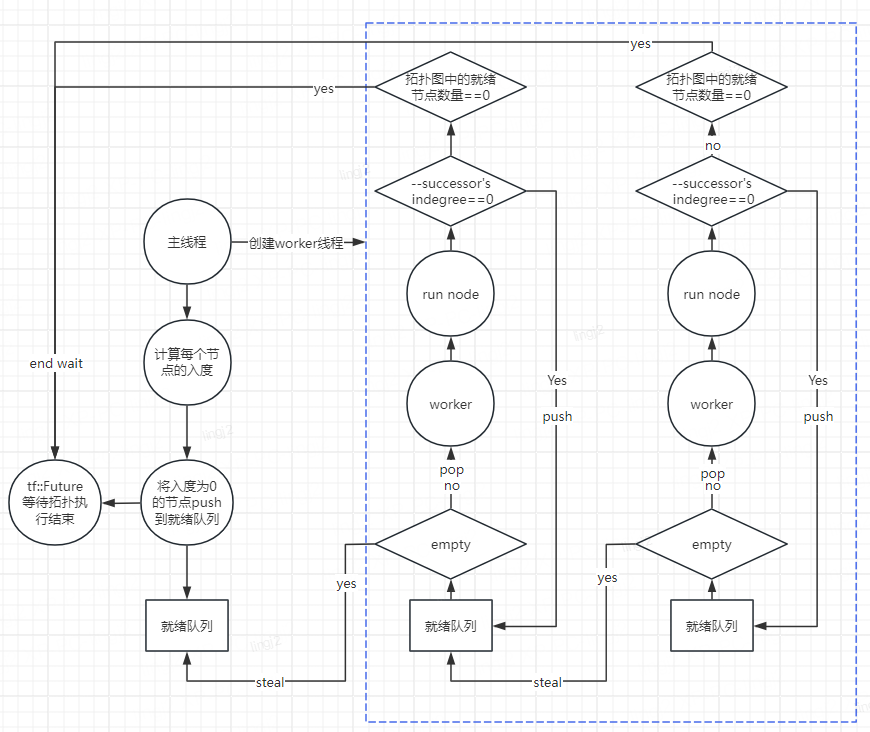
Executor构造函数调用Executor::_spawn()创建N个worker线程。该开始每个worker的窃取对象初始化为自己,观察第15行代码,可知第一次窃取的对象是主线程的就绪队列,此后会随机生成受害者id。
inline void Executor::_spawn(size_t N) { for(size_t id=0; id<N; ++id) { _workers[id]._id = id; _workers[id]._vtm = id;//初始化窃取对象 _workers[id]._executor = this; _threads[id] = std::thread([&, &w=_workers[id]] () { Node* t = nullptr; while(1) { while(t) { _invoke(w, t);//执行节点 t = w._wsq.pop();//取出节点 } std::uniform_int_distribution<size_t> rdvtm(0, _workers.size()-1); do {//窃取别的worker的就绪队列里的节点 t = (w._id == w._vtm) ? _wsq.steal() : _workers[w._vtm]._wsq.steal(); if(t) { break; } w._vtm = rdvtm(w._rdgen);//随机生成受害者id } while(!_done); if(_done) { break; } } }); }
确定节点类型
之前提到,taskflow会根据传入的callable func的函数签名确定一个节点的类型,通过传入的lambda函数的参数和返回值确定Node的类型,这是怎么做到的呢?答案是通过C++17提供的

std::is_invocable_r_v特性,比如对于条件节点(返回值为int),我们使用std::is_invocable_r_v<int, C>来判断即可。

1 template <typename C> 2 Task& Task::work(C&& c) { 3 if constexpr(is_static_task_v<C>) { 4 _node->_handle.emplace<Node::Static>(std::forward<C>(c)); 5 } 6 else if constexpr(is_condition_task_v<C>) { 7 _node->_handle.emplace<Node::Condition>(std::forward<C>(c)); 8 } 9 else { 10 static_assert(dependent_false_v<C>, "invalid task callable"); 11 } 12 return *this; 13 } 14 15 template <typename C> 16 constexpr bool is_condition_task_v = 17 (std::is_invocable_r_v<int, C> || std::is_invocable_r_v<int, C, Runtime&>) && 18 !is_subflow_task_v<C>;
Run taskflow
我们调用 executor.run(taskflow)之后,实际调用的是Executor::run_until函数,该函数会初始化topology, 将拓扑图中的起始节点加入主线程的本地就绪队列,并返回一个future,我们在主线程中调用future.wait()等待拓扑执行结束。
//p是谓词,等于true的时候停止执行, c是在拓扑结束时执行的callable函数。 template <typename P, typename C> tf::Future<void> Executor::run_until(Taskflow& f, P&& p, C&& c) { _increment_topology(); // create a topology for this run auto t = std::make_shared<Topology>(f, std::forward<P>(p), std::forward<C>(c)); // need to create future before the topology got torn down quickly tf::Future<void> future(t->_promise.get_future(), t); // modifying topology needs to be protected under the lock { std::lock_guard<std::mutex> lock(f._mutex); f._topologies.push(t); if(f._topologies.size() == 1) { _set_up_topology(_this_worker(), t.get());//调用_schedule,将拓扑的起始节点加入本地就绪队列 } } return future; } inline void Executor::_set_up_topology(Worker* worker, Topology* tpg) { tpg->_sources.clear(); tpg->_taskflow._graph._clear_detached(); _set_up_graph(tpg->_taskflow._graph, nullptr, tpg, 0, tpg->_sources); //_set_up_graph: 给每一个node设置join_counter, 并收集起始节点 tpg->_join_counter.store(tpg->_sources.size(), std::memory_order_relaxed); //tpg->_join_counter: 整个拓扑图中入度为0的节点,当它降为0时,表示拓扑图已经执行完 if(worker) { _schedule(*worker, tpg->_sources); } else { _schedule(tpg->_sources); } } inline void Executor::_set_up_graph( Graph& g, Node* parent, Topology* tpg, int state, SmallVector<Node*>& src ) { for(auto node : g._nodes) { node->_topology = tpg; node->_parent = parent; node->_state.store(state, std::memory_order_relaxed); if(node->num_dependents() == 0) { src.push_back(node);//收集拓扑图中的起始节点 } node->_set_up_join_counter();//设置node的join_counter node->_exception_ptr = nullptr; } } inline void Executor::_schedule(Worker& worker, Node* node) { auto p = node->_priority; node->_state.fetch_or(Node::READY, std::memory_order_release); if(worker._executor == this) { worker._wsq.push(node, p);//加入本地就绪队列 _notifier.notify(false); return; } { std::lock_guard<std::mutex> lock(_wsq_mutex); _wsq.push(node, p); } }
还记得创建子线程时绑定的函数吗?这个函数里调用了Executor::_invoke, 它正是节点被执行的地方,它先判断节点的类型,然后调用节点绑定的工作函数,执行完工作函数后,如果是静态节点,将其后继节点的强依赖数减一,如果减到了0, 则将该节点加入就绪队列,并将拓扑的join_counter加一;如果该节点是条件节点,直接将其后继节点加入就绪队列,并将拓扑的join_counter加一。最后,在_tear_down_invoke函数中将topology->_join_counter减一(因为本次Executor::_invoke消耗了一个就绪节点),如果减到0,则发出整个taskflow已经执行完毕的通知。
inline void Executor::_invoke(Worker& worker, Node* node) { SmallVector<int> conds; switch(node->_handle.index()) { // static task case Node::STATIC:{ _invoke_static_task(worker, node);//执行节点绑定的工作函数 } break; // condition task case Node::CONDITION: { _invoke_condition_task(worker, node, conds);//执行节点绑定的工作函数 } break; // monostate (placeholder) default: break; } // acquire the parent flow counter auto& j = (node->_parent) ? node->_parent->_join_counter : node->_topology->_join_counter; // Invoke the task based on the corresponding type switch(node->_handle.index()) { // condition and multi-condition tasks case Node::CONDITION: { for(auto cond : conds) { if(cond >= 0 && static_cast<size_t>(cond) < node->_successors.size()) { auto s = node->_successors[cond]; s->_join_counter.store(0, std::memory_order_relaxed); j.fetch_add(1, std::memory_order_relaxed);//有节点就绪了,++_topology->_join_counter _schedule(worker, s);//加入就绪队列 } } } break; // non-condition task default: { for(size_t i=0; i<node->_successors.size(); ++i) { if(auto s = node->_successors[i]; fetch_sub(1, std::memory_order_acq_rel) == 1) {//若node的依赖降为0 j.fetch_add(1, std::memory_order_relaxed); _schedule(worker, s); } } } break; } // tear_down the invoke _tear_down_invoke(worker, node); } inline void Executor::_invoke_static_task(Worker& worker, Node* node) { std::get<Node::Static>(node->_handle).work();//调用用户传入的工作函数 }
Extras
接下来介绍两个展示taskflow灵活性的功能,分别是Runtime和Corun.
Runtime
taskflow允许在一个节点的执行体内调度另一个节点,这是强制调度,不管被调度节点的依赖执行情况。
如代码所示,在Task B的工作函数内强制调度Task C.
tf::Task A, B, C, D; std::tie(A, B, C, D) = taskflow.emplace( [] () { return 0; }, [&C] (tf::Runtime& rt) { // C must be captured by reference std::cout << "B\n"; rt.schedule(C); }, [] () { std::cout << "C\n"; }, [] () { std::cout << "D\n"; } ); A.precede(B, C, D); executor.run(taskflow).wait();
inline void Runtime::schedule(Task task) { auto node = task._node; node->_join_counter.store(0, std::memory_order_relaxed); j.fetch_add(1, std::memory_order_relaxed); _executor._schedule(_worker, node); }
Corun
当拓扑节点中中有subflow或者嵌套了另一个taskflow时,如果需要在某个worker里执行它们,要用到专门的方法void Executor::corun. 当worke在执行subflow时,它的就绪节点可能被别的worker窃取,当worker执行完它绑定的subflow后,它才会去窃取其他的worker的就绪节点。
不复用Executor::run方法的原因: run返回的是tf::Future对象,wait时会阻塞当前工作线程,这样会引起死锁。
tf::Executor executor(2); tf::Taskflow taskflow; std::array<tf::Taskflow, 1000> others; std::atomic<size_t> counter{0}; for(size_t n=0; n<1000; n++) { for(size_t i=0; i<500; i++) { others[n].emplace([&](){ counter++; }); } taskflow.emplace([&executor, &tf=others[n]](){ // blocking the worker can introduce deadlock where // all workers are waiting for their taskflows to finish // executor.run(tf).wait(); // the caller worker will not block but corun these // taskflows through its work-stealing loop executor.corun(tf); }); } executor.run(taskflow).wait();
定制功能
Schedule once
Bug or feature?
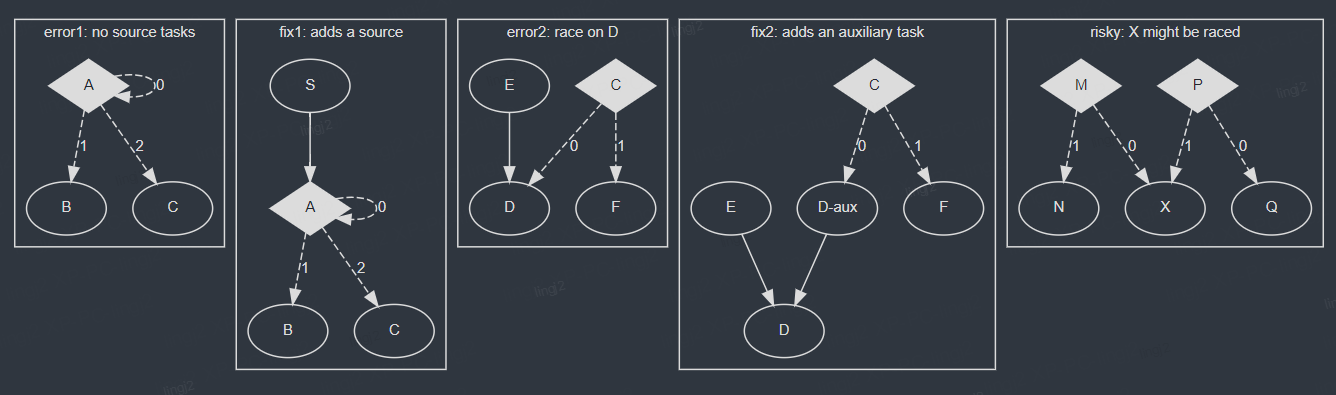
In the
error1 scenario, there is no source task for the scheduler to start with, and the simplest fix is to add a task S that has no dependents. In the error2 scenario, D might be scheduled twice by E through the strong dependency and C through the weak dependency (on returning 0). To fix this problem, you can add an auxiliary task D-aux to break the mixed use of strong dependency and weak dependency. In the risky scenario, task X may be raced by M and P if M returns 0 and P returns 1.在error2的场景中,D可能被调度2次,如果我们的实际场景要求支持这种拓扑图,并且在单轮执行过程中每个节点只允许被调度一次该怎么做呢?
很简单,我们可以添加一个std::atomic_flag is_scheduled,在节点被_schedule之前判断它是否已经被调度过,如下面第8行所示,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | switch(node->_handle.index()) { // non-condition task default: { for(size_t i=0; i<node->_successors.size(); ++i) { //if(auto s = node->_successors[i]; --(s->_join_counter) == 0) { if(auto s = node->_successors[i]; s->_join_counter.fetch_sub(1, std::memory_order_acq_rel) == 1) { if (!s->is_scheduled.test_and_set(std::memory_order_relaxed)) { j.fetch_add(1, std::memory_order_relaxed); _schedule(worker, s);//加入就绪队列 } } } } break;} |
本轮拓扑执行完后,如果紧接着开始第二遍执行该拓扑图,应该在哪里将s->is_scheduled clear呢?答案是在Executor::_set_up_topology函数中,因为每次重新跑拓扑图都会重新_set_up_topology。
Err handling
在实际应用场景中,每个节点绑定的工作函数可能会在运行过程中碰到一些业务中非预期的问题,这个时候我们希望不再调度该节点的后继节点。在taskflow中应该怎么实现呢?
对于taskflow的条件节点,它绑定的工作函数具有返回值,我们可以规定返回值-1表示该工作函数遇到了非预期的问题,执行失败,并在Executor::_invoke函数中进行特判if(cond >= 0).
case Node::CONDITION: { for(auto cond : conds) { if(cond >= 0 && static_cast<size_t>(cond) < node->_successors.size()) {
但是对于静态节点,它绑定的工作函数没有传入参数也没有返回值,taskflow无法获取该节点执行成功与否的情况,这个时候我们可以更改静态节点绑定的函数的类型,比如要求该函数具有传入参数bool&, 以此将执行结果反馈给框架。
auto [A, B, C, D] = taskflow.emplace( [](bool& result) { std::cout << "TaskA failed\n"; result = false;}, [](bool& result) { std::cout << "TaskB\n"; result = true;}, [](bool& result) { std::cout << "TaskC\n"; result = true;}, [](bool& result) { std::cout << "TaskD\n"; result = true;} );
template <typename C> constexpr bool is_static_task_v = std::is_invocable_r_v<void, C, bool&>;
inline void Executor::_invoke_static_task(Node* node, bool& result) { std::get<Node::Static>(node->_handle).work(result); }
Tips: 为什么不设置静态节点绑定的工作函数的返回值是bool呢?因为即使返回值是bool也会匹配std::is_invocable_r_v<int, C>(这正是条件节点的函数签名), 它会被taskflow判定成条件节点。
参考文档


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具
· AI 智能体引爆开源社区「GitHub 热点速览」