


kettle工具使用——测试基本面
金融数据的来源:万得资讯、财汇、聚源,利用kettle工具和kettle脚本,将有用的数据传输到我们自己使用的数据库中。
如何测试kettle脚本。
一、背景业务知识
1、证券交易信息:投资者买卖证券的申报记录进入证券交易系统后汇总,并按照一定规则进行排序,形成申报数据库。投资者申报的内容经证券交易所系统自动撮合后形成交易记录,汇集成成交数据库。与此同时,证券交易所的行情系统生成软件在申报数据和成交数据库中进行指定指标抽取,结合部分指标的统计计算,形成固定数据格式的行情数据库。
2、万德的数据来源:上海证券交易所、深圳证券交易所授权的证券信息经营机构和专业资讯数据提供商如恒生指数、财华社等获取,从其他第三方数据收集机构购买。购买专业媒体和研究机构的报告。万得资讯将数据采集、录入和分析,会按照数据源的不同(如海外市场、香港等)而分成几个大组处理各种信息。
3、金融机构购买万德整理的数据,就是我们所说的wind数据库里的信息。将这些信息利用kettle工具和kettle脚本将Wind数据库的数据拆分、提取分类插入或更新到我们自己的sirm系统的数据库中。
二、明确测试要求
1、验证脚本是否能正确的通过kettle工具从Wind数据库中提取出我们所需要的数据,并正确实时的插入到sirm系统中。
a、我们所需要的基本面数据根据项目需求,sirm有一套基本面数据库字典,根据需要的数据确定我们sirm数据库需要哪些表以及表里的数据。举例:比如仅仅只需要A股数据和申万行业体系的数据;首先需要确定需要哪些表,然后确定数据。其他具体见附件一。
b、根据数据字典以及关系表确认数据来源。静态验证脚本,可以自己编辑sql脚本,对比kettle脚本。具体查看kettle脚本,见附件二。
c、kettle的实时调用有两种:1、kettle工具自动定时调用kettle脚本进行数据提取插入;2、一般项目会有固定的代码定时任务调用kettle脚本,因此需要测试sirm系统定时任务能否能否正确的调用kettle工具来执行kettle脚本。根据具体情况
三、kettle概念:Kettle是一款国外开源的ETL工具(即数据库提取插入工具),纯java编写,可以在Window、Linux、Unix上运行,绿色无需安装,数据抽取高效稳定。Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。Kettle这个ETL工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的用户环境来描述你想做什么,而不是你想怎么做。Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换即ktr文件(可看到数据库表的每一个字段的数据来自数据源的哪个表哪个字段),job则完成整个工作流的控制(控制数据源是哪个,在哪儿查询,在哪儿插入,先查询什么,后干什么)。通俗来讲,一个复杂的数据过滤插入脚本基本上是由kjb文件调用Ktr文件来共同实现整个数据的提取的。
四、操作:如何导入kettle脚本,执行脚本,进行数据提取
4.1、前期准备工作:启动kettle,连接数据库,导入kettle脚本,更改数据库连接
1、解压kettle安装包:pdi-ce-4.1.0-stable,点击pdi-ce-4.1.0-stable\data-integration中的spoon.bat文件打开spoon
2、创建资源库
第一步:新建资源库,点击“Tools-资源库-连接资源库”弹出如下窗口
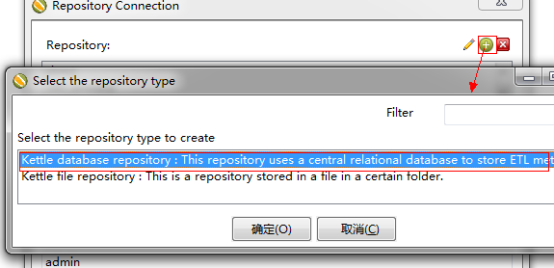
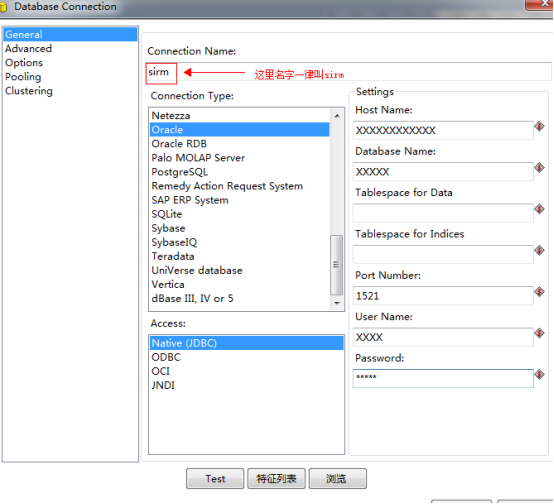
第二步:建立数据库连接

第三步:点击Test测试数据库连接是否正确

第四步:创建资源库表结构
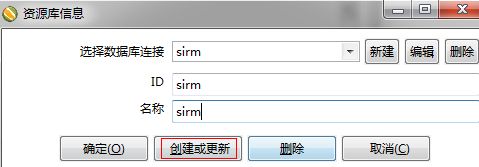
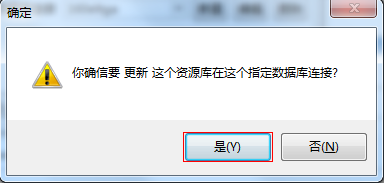
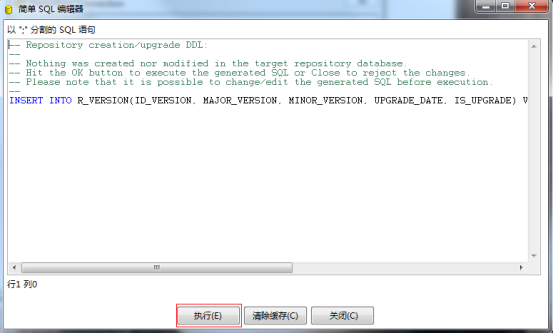
点击执行后,再点击确定按钮,最后关闭窗口。创建完毕后,默认密码为admin
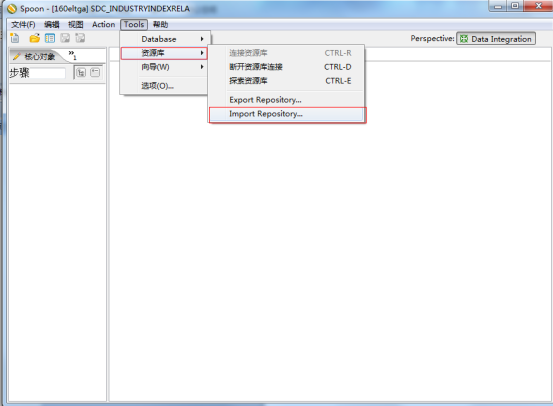
3. 导入资源数据
第一步:如下图: 点击Tools-资源库- Import Repository(必须在登录状态,没登录的话先点击Tools-资源库-连接资源库)
第二步:1.找到数据资源文件;2.选择script文件夹内的所有脚本后 按 打开 。
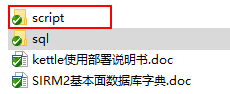
注意:文件路径不可含有中文,否则导入失败!
第三步:选择你要放的资源库的文件夹,放在根目录。
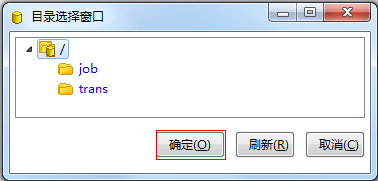
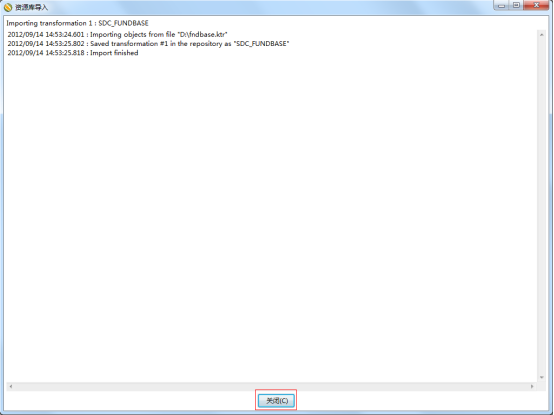
第四步:点击,可以看到导入的脚本

4. 修改连接
修改连接,关闭所有转换,点击
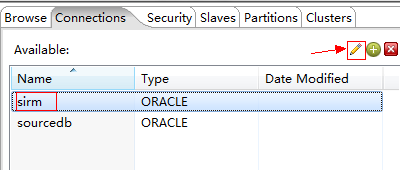
Sirm是sirm系统的数据库连接(即接收端数据库)
Sourcedb是数据源的数据库连接
点击修改以上两个连接,之后断开资源库
注意:退出kettle前 最好先断开资源库,然后再关闭,否则有些操作会无效,比如删除脚本会删不掉、修改连接会无效等。
五、查看脚本,理解脚本,根据脚本,自动拉取,编辑正确的查询的sql。
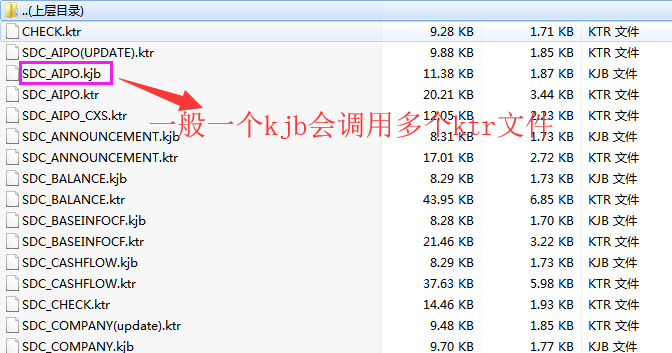
1、如下是kettle脚本文件。一般一个kjb文件会调用多个ktr文件。
2、连接数据库,点击,可以查看到脚本文件。
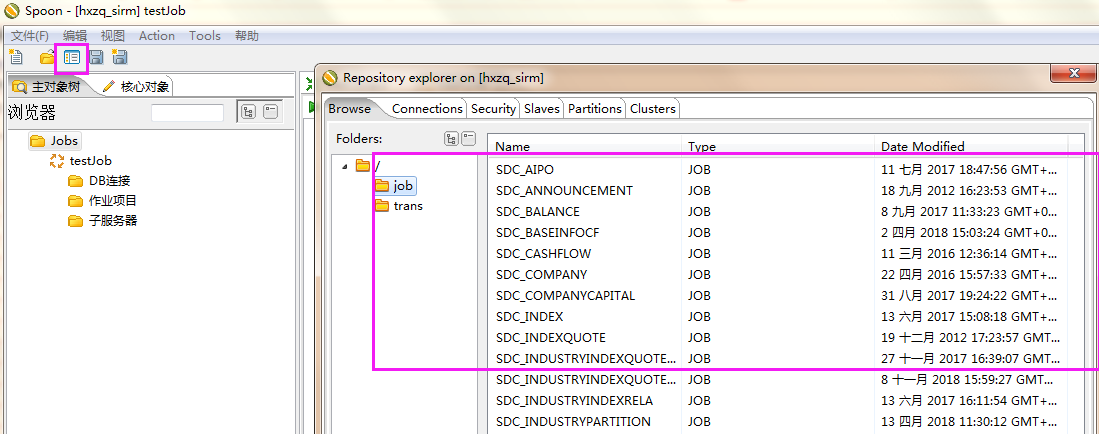
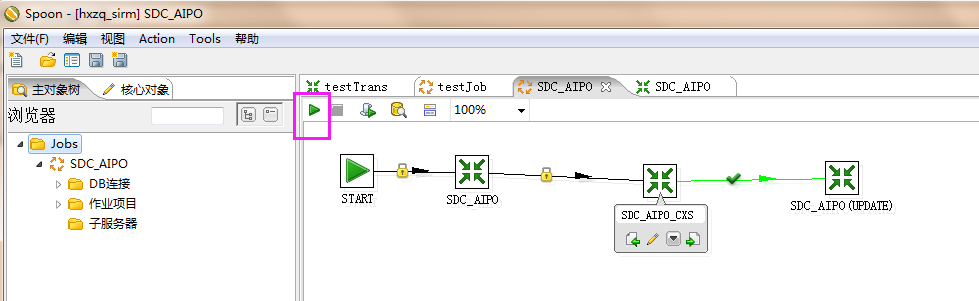
3、点击job下的文件,查看表的控制工作流。
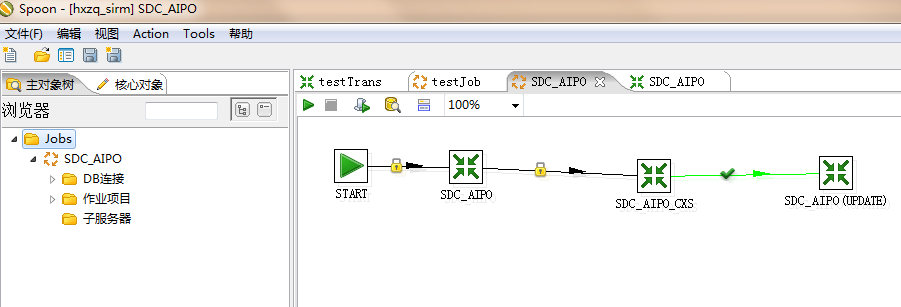
4、根据kjb转换文件查询对应的ktr脚本,例如上图在sdc_aipo.kjb文件中,调用了三个sdc_aipo、sdc_aipo_cx、sdc_aipo(update) ktr文件,查看每个ktr的具体操作。
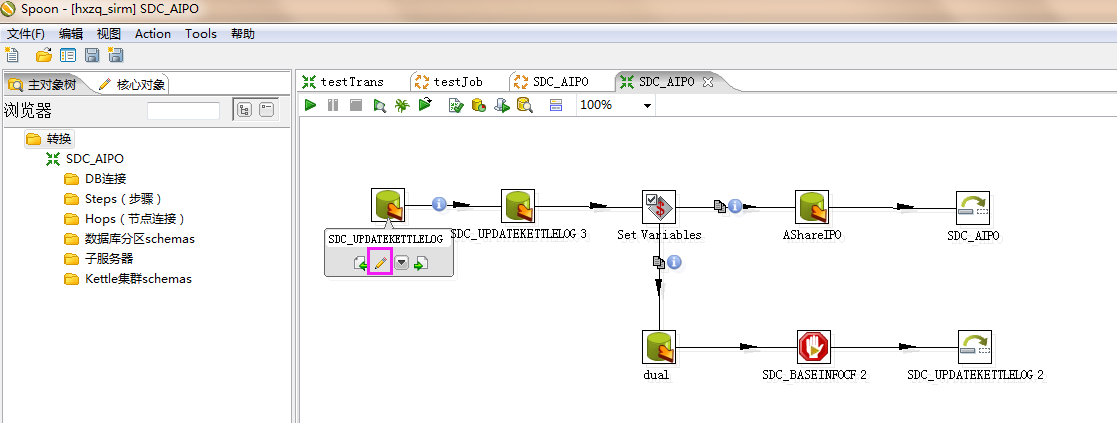
5、查看ktr中每个节点的具体操作,点击上图中铅笔图标进行编辑,可查看到脚本具体内容如下,连接的是sirm数据库,查询xxx表中kettle更新的时间。
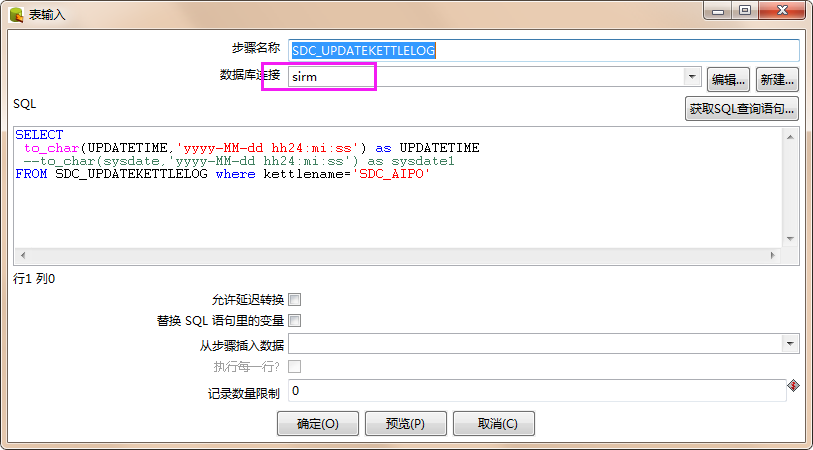
6、根据每个节点操作的sql,根据数据字典和表字段对应关系查看这些脚本是否编写正确,确认脚本正确后,执行kjb文件,开始导入数据;
六、如何进行测试:从拿到需求到测试完成的一个过程。
手把手教学,一开始领导让我从拿到需求到测试完成都写下来,我还是有点拒绝的,因为做测试这个工作,每个人的能力,深度广度不一样,思考和入手的方向就不一样,做测试是需要思考的,我不想让自己的思维限制了大家的,也希望 大家多加思考,测试并不是一个培训或者手把手教学,你就能按部就班的。
6.1了解开发是如何将这个功能开发出来的,最好自己也编写一个相关的脚本,了解相关业务及工具,更加全面的进行测试。
我发现这篇文章写的很好,介绍keettle的组件和使用,步骤清晰,大家可以直接点进查看:https://www.cnblogs.com/zhangchenliang/p/4179775.html。
下面是我编写的一个简单的脚本,模拟将wind数据库的某个表的某个字段导入到另外一个数据库的某个表的某个字段中,复杂的需要各位深入学习,在后面的测试示例中我会简单做脚本介绍。
6.1.1、将wind中的 compintroduction(公司简介)根据sirm基本面数据字典要求导入到sdc_companytest表中(为简单,sdc_companytest只需要:id、公司代码、公司简称、是否上市)。
已存在的条件:wind数据源数据库(192.168.x.xxx/1521:orcl:wind);测试sirm数据库(172.16.x.xxx/1521:sirmbroker5)
6.1.2、 准备的sirm数据库,进行清库,清表,重新创建干净的需要字段的sdc_company表。所以一般开发脚本的部署包需要以下三个sql脚本。
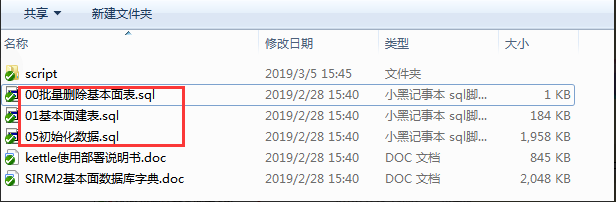
在我们的案例中,有sdc_company表的先要清表,然后再创建新的sdc_company保证有我们所需要的字段,此表不需要初始化数据因此不需要初始化sql脚本。
1)清表数据结构及主外键:sdc_companytest没有外键,无需删除外键
直接:drop table sdc_companytest
2)创建表及结构:
3) create table SDC_COMPANYtest --公司表
( GUID VARCHAR2(40) default Sys_guid() not null,
COMPANYCODE VARCHAR2(50),-----------公司代码
NAME VARCHAR2(200),-----公司简称
IS_LISTED NUMBER(1),----是否上市
CREATETIME DATE default sysdate,
UPDATETIME DATE default sysdate);
---为字段添加注释
comment on column SDC_COMPANYtest.COMPANYCODE
is '公司代码';
comment on column SDC_COMPANYtest.NAME
is '公司简称';
comment on column SDC_COMPANYtest.IS_LISTED
is '是否上市';
4)Kettle创建脚本
步骤1:创建一个kjb转换和一个ktr作业。
步骤2:在ktr转换上创建两个DB链接,一个wind数据源,一个sirm数据库。
步骤3:创建步骤与步骤之间的关系。
1:在核心对象中添加表输入,查询出所需要数据源导出的表数据
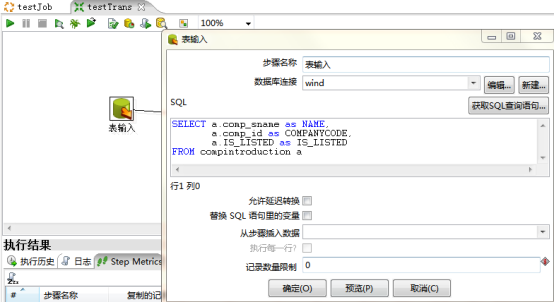
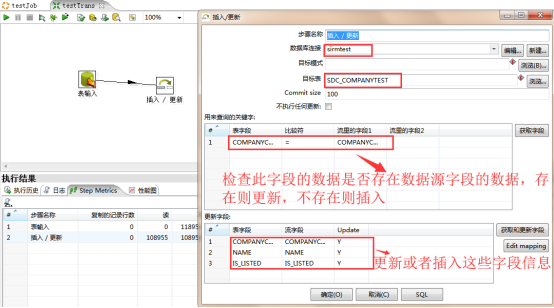
2:创建另外一个步骤【插入/ 更新】,然后在【表输入】上同时按住shift键和鼠标左键滑向【插入/ 更新】,这样建立两个步骤之间的连接,【插入/ 更新】执行的逻辑是如果wind表中的记录在sirm中不存在那么就插入,如果存在就更新,如下图,在插入更新中我们可以做一些关键条件和字段映射,这里我们是最简单的!点击保存,把我们建立的转换保存一下。建立好转换之后,我们可以直接运行这个转换,检查一下是否有错,如图,有错误都会在下面的控制台上输出。
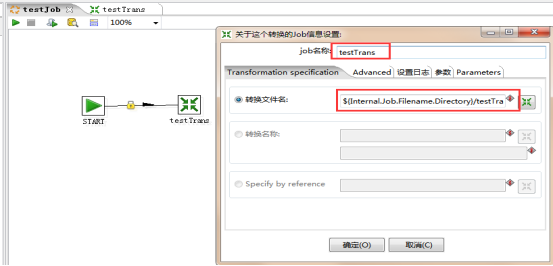
步骤4:转换定时执行,建立作业。在通用中建立一个start,然后添加一个转换,配置上我们前面创建的转换的ktr文件。
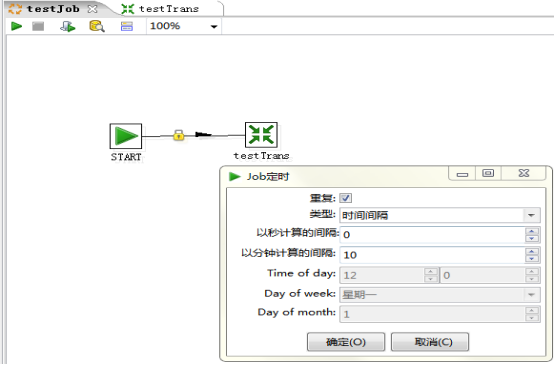
步骤5:双击start,配置相应的定时执行,这样这个作业就制定好了,点击保存之后,我们就可以在图形化界面上点击开始执行了。在我们的项目中,是通过项目的kettle定时任务来执行kettle脚本的,因此不需要进行这个步骤五进行定时。此时点击绿色三角形就可以执行了。
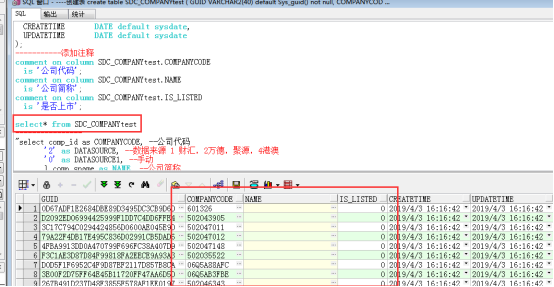
步骤6:查询sirm系统的sdc_companytest就可以看到导入的数据,如图,数据导入成功。
6.2 、理解需求。
拿到的需求如下,需求写的不好,需求背景、需求目标、业务逻辑、功能特性、数据上报都没写。不想继续吐槽,大家将就一下吧(题外话:在实际的工作中,中小型企业大多追求的是利益最大化,效率最高效,反而一些前期细节注重的不好,导致后期延期工作进展不顺利、得不偿失。)

需求提供个人长期业务接触得出以下几点详细需求拆分:
1、项目需要一个oracle11g的数据库。
2、项目需要基本面数据,数据来源于新wind数据源。
3、项目所需数据:需要所有的必须的基本面表、基本面数据(只需要A股、申万行业体系数据)、其他必须初始化数据
4、数据来源范围:1)新wind数据库中wind用户下的表的数据。
2)表中A股的数据和申万行业体系数据
5、基本面数据,利用脚本通过工具导入,我们公司使用的是kettle工具脚本导入。
6、数据导入:1)首次全量导入;2)数据动态增量导入。
7、数据导入成功后在项目系统中的配置和展示。
以上通俗来将就是:1、数据表是哪些;2、数据来源是哪些;3、数据如何导入;4、数据静态、动态导入场景;5、数据导入后的使用。
6.3、根据需求和实际项目业务编写相关测试点。
根据测试点以及表的要求,对表进行表名、字段长度、类型、注解、导入数据数量、数据正确性进行详细核对。
结束!

