


Java集合
Java集合
集合
什么是集合,集合有什么作用
- 数组其实就是一个集合,集合实际上就是一个容器,可以容纳其他类型的数据
- 集合为什么说在开发中使用较多:
- 集合是一个容器,是一个载体,可以一次容纳多个对象
- 在实际开发中,假设连接数据库,数据库当中有10条记录,那么假设把这10条记录查询出来,在java程序中会将10条数据封装成10个java对象,然后将10个java对象放到某一个集合当中,讲集合传到前端,然后遍历集合,将一个数据一个数据展现出来
集合存储的是Java对象(引用)
- 集合当中存储的都是Java对象的内存地址(或者说集合中存储的是引用)
- list.add(100); //自动装箱Integer
- 注意:
- 集合在java中本身是一个容器,是一个对象
- 集合中任何时候存储的都是"引用";
java中每一个不同的集合,底层都对应着不同的数据结构
- 在java中每一个不同的集合,底层会对应不同的数据结构,往不同的集合中存储元素,等于将数据放到了不同数据结构;不同的数据结构,数据存储方式不同,
- 常见的有:数组,二叉树,链表,哈希表.....
java中常用的集合梳理
集合图
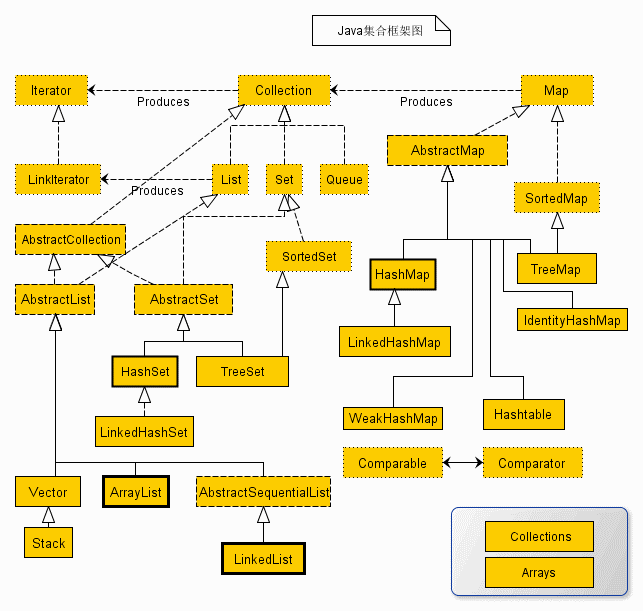
集合类简介
- 常用的有Collection下的Iterator(迭代器)、List接口下的ArrayList、Linkedist;Set接口写的HashSet和TreeSet
- Map接口下的HashMap和TreeMap以及Properties属性类
Iterable接口
-
Collection下的集合都可以使用Iterable接口下的iteator()方法拿到迭代器,返回一个Iterator类型的数据
-
这个接口下有三个方法:
-
hasNext() : 判断集合中是否还有元素,返回的是一个Boolean类型,如果为true,继续迭代
-
next(): 通过hasNext()判断,如果有元素就通过next()方法继续迭代
-
remove() :删除元素,通过迭代器调用,在迭代过程中不能使用对象来调用remove()方法来删除元素,会出现异常
-
public class CollectionTest01 { public static void main(String[] args) { Collection<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); Iterator<Integer> iterator = list.iterator(); while(iterator.hasNext()){ System.out.println(iterator.next()); } iterator.remove(); //删除 System.out.println(list); } }
-
List接口
-
List接口是Collection的子接口,List的存储特点是:有序可重复,元素有下标
-
List集合对象的创建:
-
List<String> list = new ArrayList<>(); //创建List集合的对象为list
-
-
向每个元素中添加元素
-
list.add("list"); list.add("string");
-
-
从集合中取出某个元素
-
public class CollectionTest01 { public static void main(String[] args) { List<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); System.out.println(list.get(2)); //通过index来获取元素 } }
-
-
遍历元素
-
方法一:通过Iterable迭代器的方法来迭代元素
-
public class CollectionTest01 { public static void main(String[] args) { List<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); Iterator<Integer> iterator = list.iterator(); while (iterator.hasNext()){ System.out.println(iterator.next()); } } }
-
-
方法二:通过for循环或者增强for循环来迭代元素
-
public class CollectionTest01 { public static void main(String[] args) { List<Integer> list = new ArrayList<>(); list.add(1); list.add(2); list.add(3); for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i)); } for(Integer i:list){ //增强for循环 System.out.println(i); } } }
-
-
常用方法:
-
boolean add(E e) //将指定的元素到这个列表的末尾 void add(int index, Object element) //通过索引来添加元素 Object set(int index, Object element) //用指定元素替换此列表中指定位置的元素 Object get(int index) //通过索引来获取该位置的元素 int indexOf(Object o) //返回此列表中指定元素的第一个出现的索引 int lastIndexOf(Object o) //返回此列表中指定元最后一个出现的索引 Object remove(int index) //删除指定的元素 int size() //返回此列表中元素的数目。 boolean contains(Object o) //判断当前集合中是否包含元素o,包含返回true,不包含返回false boolean isEmpty() //判断该集合中元素的个数是否为0 Object[] toArray() //调用这个方法可以把集合转换成数组
-
-
ArrayList实现类
- ArrayList底层采用了数组这种数据结构,是非线程安全的
- ArrayList集合初始化容量为0,调用add()方法后,容量为10,扩容为原容量的1.5倍
- 建议给定一个预估记的初始化容量,减少数组的扩容次数,这是ArrayLIst集合比较重要的优化策略
- 数组的优缺点:
- 优点:检索效率比较高
- 缺点:随即删除元素效率低
- 但是向数组末尾添加元素,效率还是很高的
LinkedList实现类
- LinkedList集合是双向链表
- 对于链表数据结构来说,随机增删效率较高,检索效率较低
- 链表中的元素,在空间存储上内存地址不连续
- 双向列表的每一个Node中含有上一个Node的内存地址,数据,下一个Node的内存地址
Vector实现类
- Vector集合底层是数组,是线程安全的
- Vector的所有方法都是有了synchronized关键字修饰,所以线程安全,但是效率较低,所以很少使用Vector集合
Set接口
- Set集合是Collection的子接口,常用的实现类类有TreeSet和HashSet ,Set集合的特点是无序不可重复,没有下标,无序是指存入的数据的顺序和存储的数据顺序不一定相同
- 由于Set集合下的实现类在实例化过程中都是创建了Map接口下的集合对象,所以在此处不深究
HashSet实现类
- 实际上HashSet集合在new的时候,底层是new了一个hashMap集合;向HashSet集合中存储元素没实际上是存储到HashMap集合中了,HashMap集合是一个哈希表数据结构
- HashSet集合初始化容量是16,初始化容量建议是2的倍数;扩容之后是元容量的倍数
TreeSet实现类:
- TreeSet集合是实现了SortedSet接口:
- SortedSet集合存储元素的特点:
- 由于继承了Set集合,所以它的特点也是无序不可重复的,但是放在SortedSet集合中的元素可以自动排序;
- SortedSet集合存储元素的特点:
- new TreeSet集合的时候,底层实际上是new了一个TreeMap集合
- 往TreeSet集合中放数据的时候,实际上是将数据放到TreeMap集合中了,
- TreeMap集合底层采用了二叉树数据结构
Map 接口
-
Map接口和Collection集合没有关系
-
Map集合以key和value的这种键值对的方式存储元素
-
key和value都是存储的Java的内存地址
-
所有Map集合的key特点:无序不可重复
-
Map集合的key和Set集合元素特点相同
-
Map集合的元素增加:
-
public Class Test{ public static void main(String[] args){ Map<Integer, String> map = new HashMap<>(); map.put(0,"size"); map.put(1, "123"); //增加元素 map.put(2,"assd"); map.put(3,"love"); } }
-
-
Map集合通过key来获取value
-
public class MapTest { public static void main(String[] args) { Map<Integer, String> map = new HashMap<>(); map.put(0,"size"); map.put(1, "123"); //增加元素 map.put(2,"assd"); map.put(3,"love"); String value = map.get(2); //通过key拿到value System.out.println(value); } }
-
-
其他常用方法:
-
public class MapTest { public static void main(String[] args) { Map<Integer, String> map = new HashMap<>(); map.put(0,"size"); map.put(1, "123"); //增加元素 map.put(2,"assd"); map.put(3,"love"); System.out.println(map.size()); //键值对一共有多少 map.remove(2); //删除第二个元素 System.out.println(map.size()); System.out.println(map.containsValue("123")); //map是否存在"123"的键值对 System.out.println(map.isEmpty()); //map是否为空 System.out.println("+++++++++++++++++++++++++++++++++++"); } }
-
-
Map集合元素的遍历:
-
package com.ljinw.Test; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set; public class TestDemo{ public static void main(String[] args){ Map<Integer,String> map = new HashMap<>(); map.put(1,"zhangsan"); map.put(2,"zhangsi"); map.put(3,"zhouliu"); map.put(4,"libai"); //第一种遍历方法,通过迭代器 Set<Integer> keys = map.keySet(); //把map中key通过keySet()方法映射到Set集合中,Map集合没有iterator()方法 Iterator<Integer> it = keys.iterator(); while(it.hasNext()){ Integer key = it.next(); //next方法返回值是一个int类型的数据 String value= map.get(key); //通过key来获取value System.out.println(key + "=" + value); } //第二种遍历方法,通过Entry()方法来迭代获取value Set<Map.Entry<Integer,String>> set = map.entrySet(); //拿到的set是一个node节点,通过hashCode()方法和equals()方法来判断该元素的位置 //hashCode()方法是实例方法,底层通过hash()方法来决定哈希表中的一维数组的元素下标 //equals(0方法是实例方法,通过比较元素是否相同来决定value的值 System.out.println("-------我是一条分割线---------"); Iterator<Map.Entry<Integer,String>> it2 = set.iterator();//拿到迭代器 while(it2.hasNext()){ Map.Entry<Integer,String> node = it2.next(); //这个node包含两个元素,key和value Integer key = node.getKey(); //拿到key,返回一个Integer类型的数据(因为定义时 在泛型中规定了元素类型) String value = node.getValue(); //拿到value,返回String类型的数据 System.out.println(key + "=" + value); } } } -
//用for:each循环来替换上面的方案 package com.ljinw.Test; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set; public class TestDemo{ public static void main(String[] args){ Map<Integer,String> map = new HashMap<>(); map.put(1,"zhangsan"); map.put(2,"zhangsi"); map.put(3,"zhouliu"); map.put(4,"libai"); //第一种方法,用增强for循环来替换迭代器进行遍历集合拿到value Set<Integer> keys = map.keySet(); for(Integer key: keys){ System.out.println(key + "=" +map.get(key)); } Set<Map.Entry<Integer,String>> set = map.entrySet(); for(Map.Entry<Integer,String> node : set){ //拿到的是一个node节点 System.out.println(node.getKey()+"="+node.getValue()); } } } -
通过Entry()方法来遍历元素,如果Map集合中传入的数据类型是自己自定的就需要重写hashCode()方法和equals()方法
-
//自定义Student类 package com.ljinw.Student; import java.util.Objects; public class student { private String name; public student(){ }; public student(String name){ this.name=name; }; public void SetName(String name){ this.name=name; }; public String getName(){ return name; } //重写equals方法 @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; student student = (student) o; return Objects.equals(name, student.name); } //重写hashCode()方法 @Override public int hashCode() { return Objects.hash(name); } } -
import java.util.HashMap; import java.util.Map; import java.util.Set; public class HashMapTest { public static void main(String[] args) { student s1 = new student("zhangsan"); student s2 = new student("lisi"); student s3 = new student("lisi"); HashMap<student,student> hashMap = new HashMap(); hashMap.put(s1,s1); hashMap.put(s2,s2); hashMap.put(s3,s3); System.out.println(s3.equals(s2)); //true System.out.println(s2.hashCode()); //3322034 System.out.println(s3.hashCode()); //3322034 System.out.println(hashMap.size()); //通过hashCode()方法比较,hash值相等,说明在同一链表中 //通过equals比价,元素相同,所以删除这一元素 Set<Map.Entry<student, student>> entries = hashMap.entrySet(); for (Map.Entry<student, student> entry : entries) { System.out.println(entry.getKey().getName()+"="+entry.getValue().getName()); } } }
-
-
HashMap实现类
- HashMap集合底层是哈希表数据结构,在JDK1.8之后,如果哈希表单向链表中元素超过8个,单向链表这种数据机构会变成红黑树数据结构;当红黑树上的节点少于6时,会重新把红黑树编程单向链表数据结构,这种方式也是为了提高检索效率,二叉树的检索会再次缩小扫描范围,提高效率
- HashMap集合初始化容量是16,默认加载因子是0.75,也就是时候当集合容量达到75%时集合就会扩容,扩容之后的是原容量的2倍
- HashMap集合key和value允许null
TreeMap实现类
- TreeMap实现了SortedMap接口:
- SortedMap集合的key元素特点:
- 无序不可重复,另外放在SortedMap集合key部分的元素自动按照大小顺序排序
- SortedMap集合的key元素特点:
- TreeMap集合底层的数据结构是一个二叉树
Properties属性类
-
Properties属性类是Hashtable的子类:
- Hashtable集合底层也是哈希表数据结构,是线程安全的,效率较低
- Hashtable的key和value不允许null
- Hashtable集合初始化容量11
- Hashtable集合扩容是:*2+1
-
Properties是线程安全的,因为继承了Hashtable
-
Properties集合存储的key和value都必须是String类型的数据,不支持其他类型
-
常用方法 setProperty()方法和getProperty()
-
public class TestDemo{ public static void main(String() args){ Properties pro = new Properties(); //因为Properties规定了key和value都是String,所以就没有必要再用泛型来规定key和value的数据类型 pro.setProperty("url","jdbc:myql://localhost:3306/bjpowernode"); pro.setProperty("driver","com.mysql.jdbc.Driver"); pro.setProperty("username","root"); pro.setProperty("password","123"); //通过key来获取value String url = pro.getProperty("url"); String driver = pro.getProperty("driver"); String username = pro.getProperty("username"); String password = pro.getProperty("password"); System.out.println(url); System.out.println(driver); System.out.println(username); System.out.println(password); } }
-
实现排序
-
TreeMap的key或者TreeSet集合中的元素要想排序有两种方法:
-
第一种:实现Java.lang.Comparable接口
-
public class TreeTestDemo1{ TreeSet< } -
public class Vip implements Comparable<Vip>{ String name; int age; public Vip(String name,int age){ this.name=name; this.age=age; } @Override public String toString(){ return "Vip{" + "name='" + name + '\'' + ", age=" + age + '}'; } //CompareTO方法的返回值: //返回0表示相同,value会覆盖 //返回>0,会继续在右子树上找 [10 - 9 = 1,1>0说明左边这个数字比较大,所以在右子树上找] //返回<0,会继续在左子树上找 @Override public int compareTO(Vip v){ //排序规则 if(this.age == v.age){ //年龄相同时按照名字排序 //姓名是String类型,可以直接比,调用compareTO来完成比较 return this.name.compareTo(v.name); }esle{ return this.age - v.age } } }
-
-
第二种:单独编写一个比较器Comparable接口
-
import java.util.Comparator; import java.util.TreeSet; public class TreeMapTest02 { public static void main(String[] args) { TreeSet<WuGui>wuGuis = new TreeSet<>(new Comparator<WuGui>() {//采用匿名内部类实现实例化 @Override //比较规则 public int compare(WuGui o1, WuGui o2) { return o1.age-o2.age; } }); wuGuis.add(new WuGui(1000)); wuGuis.add(new WuGui(800)); wuGuis.add(new WuGui(810)); for (WuGui wuGui : wuGuis) { System.out.println(wuGui); } } } class WuGui{ int age; public WuGui(int age){ this.age=age; } @Override public String toString() { return "WuGui{" + "age=" + age + '}'; } } -
自平衡二叉树:
-
-
-
TreeSet集合中元素可排序的第二种方式:使用比较器的方式:
最终的结论:
放到TreeSet或者TreeMap集合key部分的元素要想做到排序,包括两种方式:
第一种:放在集合中的元素实现java.lang.Comparable接口
第二种:在构造TreeSet或者TreeMap集合的时候给它穿一个比较器对象
Comparable和Comparator怎么选择?
当比较规则不会发生改变的时候,或者说当比较规则只有1个的时候,建议实现Comparable接口
如果比较规则有多个,并且需要多个比较规则之间频繁切换,建议使用Comparator接口
Comparator接口的设计符合OCP原则

集合工具类Collections
-
synchronizedLIst方法:将线程不安全的集合变成线程安全的集合
-
sort方法(要求集合中元素实现Comparable接口)
-
package com.ljinw.Test; import java.util.*; public class CollectionsTest { public static void main(String[] args) { List<String> list = new ArrayList<>(); //变成线程安全的 Collections.synchronizedList(list); List<WuGui2> wuGui2s = new ArrayList<>(); wuGui2s.add (new WuGui2(1000)); wuGui2s.add(new WuGui2(800)); wuGui2s.add(new WuGui2(700)); for (WuGui2 wuGui2 : wuGui2s) { System.out.println(wuGui2); } //Set集合 Set<String> set = new HashSet<>(); set.add("king"); set.add("KingSoft"); set.add("king2"); set.add("king1"); //根据ArrayList构造方法得知可以传入一个Colletion集合转换成数组 List<String> myList = new ArrayList<>(set); System.out.println(myList); Collections.sort(myList); for (String s : myList) { System.out.println(s); } } } class WuGui2 implements Comparable<WuGui2> { int age; public WuGui2(int age) { this.age = age; } @Override public int compareTo(WuGui2 o) { return this.age - o.age; } @Override public String toString() { return "WuGui2{" + "age=" + age + '}'; } }
本文来自博客园,作者:小幸福Y,转载请注明原文链接:https://www.cnblogs.com/ljinw/p/15370975.html

