Linked Server 3:SQL Server 分布式数据库性能测试
我在三台安装SQL Server 2012的服务器上搭建分布式数据库,把产品环境中一年近1.4亿条数据大致均匀地存储在这三台服务器中,每台Server 存储4个月的数据,物理机的系统配置基本相同:内存16G,双核 CPU 3.6GHz,软件环境是Windows Server 2012 R,和SQL Server 2012。
1,创建水平分区视图
基础表是dbo.Commits,每个基础表大致存储4个月的数据,近5000万条记录:


CREATE TABLE [dbo].[Commits] ( [CommitID] [bigint] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL, [AuthorID] [bigint] NOT NULL, [CreatedDate] [datetime2](7) NOT NULL, [CreatedDateKey] [int] NOT NULL, CONSTRAINT [PK__Commits_CommitID] PRIMARY KEY CLUSTERED ( [CommitID] ASC, [CreatedDateKey] ASC ) )
创建分区视图,Linked Server的Alias是db2 和 db3,Catalog 是 tdw(test data warehouse):
CREATE view [dbo].[view_commits] as select [CommitID] ,[AuthorID] ,[CreatedDate] ,[CreatedDateKey] from dbo.commits c with(nolock) where c.[CreatedDateKey] between 20150900 and 20160000 union ALL select [CommitID] ,[AuthorID] ,[CreatedDate] ,[CreatedDateKey] from db3.tdw.dbo.commits c with(nolock) where c.[CreatedDateKey] between 20150000 and 20150500 union ALL select [CommitID] ,[AuthorID] ,[CreatedDate] ,[CreatedDateKey] from db2.tdw.dbo.commits c with(nolock) where c.[CreatedDateKey] between 20150500 and 20150900 WITH check OPTION; GO
2,查询性能测试
Test1,在基础表上测试,基础表是全部的数据,cost:79s
select count(0) from dbo.commits_total c with(nolock) where day(c.[CreatedDate])=1

Test2,使用分区视图测试,cost=134s,比Test1的查询性能明显降低。
select count(0) from dbo.view_commits c with(nolock) where day(c.[CreatedDate])=1
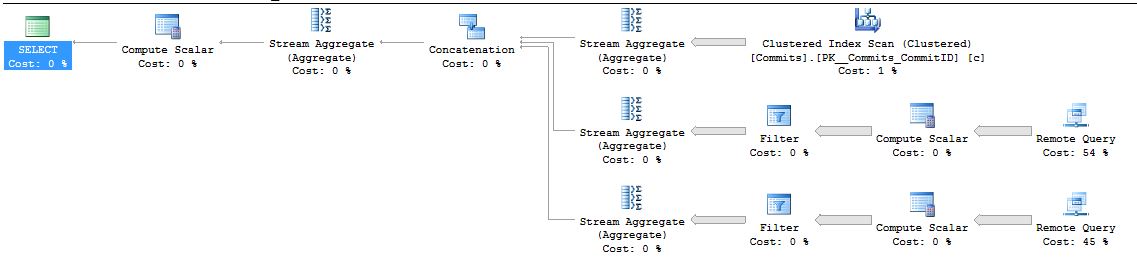
3,使用OpenQuery查询
OpenQuery把查询语句直接发送到Linked Server上执行,返回查询的结果,cost:105s,还是很高,相对提高20%的性能。
select sum(t.cnt) as cnt from ( select count(0) as cnt from dbo.commits c with(nolock) where day(c.[CreatedDate])=1 UNION all select p.cnt from openquery(db2, N'select count(0) as cnt from dbo.commits c with(nolock) where day(c.[CreatedDate])=1') as p UNION all select p.cnt from openquery(db3, N'select count(0) as cnt from dbo.commits c with(nolock) where day(c.[CreatedDate])=1') as p ) as t
4,使用C# 多线程编程
创建三个Task同时运行在三台Server上,Cost:28s
static void Main(string[] args) { List<Task> tasks = new List<Task>(); int c1=0, c2=0, c3=0; Task t1 = new Task(()=> { c1= GetCount("xxx"); }); Task t2 = new Task(() => { c2= GetCount("xxx"); }); Task t3 = new Task(() => { c3= GetCount("xxx"); }); tasks.Add(t1); tasks.Add(t2); tasks.Add(t3); Stopwatch sw = new Stopwatch(); sw.Start(); t1.Start(); t2.Start(); t3.Start(); Task.WaitAll(tasks.ToArray()); int sum = c1 + c2 + c3; sw.Stop(); Console.Read(); } static int GetCount(string str) { using (SqlConnection con = new SqlConnection(str)) { con.Open(); var cmd = con.CreateCommand(); cmd.CommandText = @" select count(0) as cnt from dbo.commits c with(nolock) where day(c.[CreatedDate]) = 1"; int count = (int)cmd.ExecuteScalar(); con.Close(); return count; } }
5,结论
- 将数据水平切分,分布式部署在不同的SQL Server上,其查询性能并不一定比单一DB性能更好。
- 使用OpenQuery函数将查询语句在Remote Server上执行,返回查询结果,能够优化Linked Server 的查询性能。
- 在使用分布式数据库查询数据时,针对特定的应用,编写特定的代码,这需要fore-end 更多的参与。
参考doc:
作者:悦光阴
本文版权归作者和博客园所有,欢迎转载,但未经作者同意,必须保留此段声明,且在文章页面醒目位置显示原文连接,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号