SQL Server 管理全文索引
一,倒转索引的结构
为了便于描述,把全文索引中存储的一行数据叫做一个文档,每一个文档都使用唯一的文档ID(DocID)标识,这个DocID也就是在创建全文索引之前,必须创建的唯一索引键。
大家知道,全文索引中存储的不是整个文本,而是把文本分词之后,存储单个标记(Token)的信息,标记(Token)是分词,及其位置等信息的统称。在填充全文索引的时候,分词器(word breader)将字符串拆分成多个单词。如果单词是一个停用词(stopword),那么该分词被过滤掉,不会存储到倒转索引中,但是停用词的位置(position)会被考虑,一个分词在全文索引中的位置(Position)是该分词在源文本中的位置。简而言之,倒转索引中存储的数据是分词和DocID之间的映射。
由DocID来查询分词,是正向的;而由分词来定位DocID,是倒转的,这就是倒转索引名称的由来。
例如,一个基础表Document有两列,DocumentID和Title,在字段Title上创建全文索引:

全文引擎首先要对Title字段的文本进行分词,倒转索引中主要包含四个字段:
- Keyword字段:单个分词,从Title字段中抽取的一个标记(Token)。
- ColId字段:列序号,用于标记全文索引的列。
- DocId字段:文档ID,是8Byte的long类型,用于唯一标记当前的文档。如果唯一索引键是整数类型,那么DocID就是唯一索引键;如果唯一索引键不是整数类型,那么DocID经过中间的映射表、唯一映射到唯一索引键。因此,整数类型的唯一索引键能够优化全文查询的性能。
- Occurrence字段:分词的位置,或者叫做偏移量(Offset)。
- CreateTime字段:时间戳字段(timestamp ),用于记录倒转索引创建的时间。
例如,下图是Document表的索引片段Fragment1:
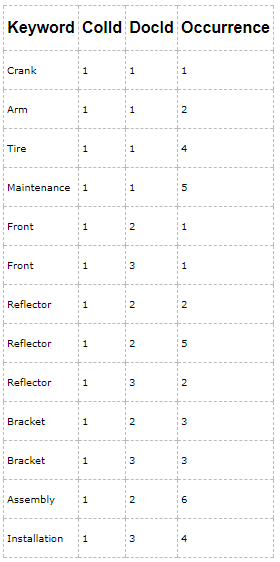
对于DocumentID=1的文档,分词器把Title字段拆分成5个分词,这5个分词分别是:Crank、Arm、and、Tire、Maintenance,出现的位置分别是1,2,3,4,5,由于分词and是一个停用词,过滤器会把分词and过滤掉,但是and分词的位置会计算在后续的分词上。因此,分词Tire的位置(Occurrence)是4,而不是3。
二,全文索引的拆分
全文索引通常会拆分成多个索引片段,一些索引片段可能包含新的数据,而一些索引片段可能包含已经被删除的数据。例如,如果有一个用户把DocumentID=3的文档的Title字段更新为Rear Reflector:
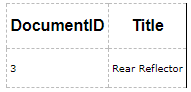
全文索引会新建一个索引片段Fragmeng2,如下图所示,

因此,如果有用户查询"Rear Reflector" ,DocID3将会被返回。每一个Fragment都会记录创建的时间,当相同的DocID出现在不同的索引片段中,创建时间晚的是最新的数据。索引片段的创建时间可以从系统视图:sys.fulltext_index_fragments 中查看。
三,全文索引片段的重组
当数据持续更新时,索引片段的数量也会持续增加,而全文查询必须首先搜索每一个索引片段,然后丢弃无用的老数据,这会导致全文查询的性能下降,必须减少索引片段的数量。由于每一个全文索引都属于一个全文目录(fulltext catalog),SQL Server使用TSQL 命令 ALTER FULLTEXT CATALOG 和REORGANIZE 选项对目录中的所有全文索引进行重组操作。
SQL Server使用master merge来重组全文索引,也就是说,把全文索引的各个索引片段归并到一个打的片段中,然后把废弃的文档从全文索引中删除,这样重组之后,全文索引中包含的都是纯净的数据:
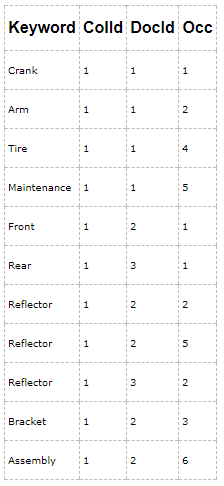
在填充全文索引时,为了提高全文索引的填充速度,全文引擎使用Range来管理。Range是并行处理的进程,需要大量消耗CPU资源。batch是基础表(underlying table)的数据块,每个Range 都会产生多个batch,分batch处理数据能够提高全文索引填充(population)的速度。SQL Server 从基础表中读取数据产生batch,每个batch经过全文引擎的处理,会产生一个索引片段。在填充操作完成后,SQL Server 会进行一次Master Merge 操作,将索引片段归并到Master Fragment。
通过 sys.dm_fts_population_ranges 查看当前正在被处理的Ranges,每个Range都会分batch来处理。SQL Server 处理Batches的过程,可以通过 sys.dm_fts_outstanding_batches 来监控,其 crawl_memory_address column 指定其Parent Range。
全文索引的重组,可以设置调度程序(Schedule),通过Population Schedule tab,创建schedule和Job,按照schedule对全文索引进行重组(reorganize):
四,配置全文索引的停用词
为了阻止全文索引把停用词填充到全文索引中,SQL Server允许用户自定义停用词列表,把常用词(这些词对查询没有任何帮助)添加到停用词列表中。在填充全文索引时,全文引擎会把停用词过滤掉,这意味着,全文查询不会搜索停用词,尽管全文索引会忽略停用词,但是,停用词的位置会被考虑进去,每个分词的位置是该分词在源文本中的偏移量。
通过 CREATE FULLTEXT STOPLIST (Transact-SQL) 创建停用词列表(StopLists),通过ALTER FULLTEXT STOPLIST (Transact-SQL) 向停用词列表中增加和删除停用词(Stopword),通过ALTER FULLTEXT INDEX (Transact-SQL) 更新全文索引引用的停用词列表,实例代码如下:
CREATE FULLTEXT STOPLIST stoplist_name FROM SYSTEM STOPLIST; ALTER FULLTEXT STOPLIST stoplist_name ADD 'stopword' LANGUAGE language_term; ALTER FULLTEXT INDEX ON table_name SET STOPLIST =stoplist_name [WITH NO POPULATION];
五,查看分词
分词是全文引擎的一项重要的功能,通过 sys.dm_fts_parser 可以分词器对文本分词之后的结果,这也可以用于查看contains 子句产生的分词:
sys.dm_fts_parser('query_string', lcid, stoplist_id, accent_sensitivity)
1,查看语句的分词
SELECT fp.keyword, fp.group_id, fp.phrase_id, fp.occurrence, fp.special_term, fp.display_term, case fp.expansion_type when 0 then N'Single word case' when 2 then N'Inflectional expansion' when 4 then N'Thesaurus expansion/replacement' end as expansion_type, fp.source_term FROM sys.dm_fts_parser (' "The Microsoft business analysis" or "MS revenue" or "multi-million" ', 1033, 0, 0) as fp
2,查看contains 谓词如何解析 FORMSOF 子句
查看同源词, 'query_string' 的格式是: 'FORMSOF( INFLECTIONAL, query_term )'
SELECT fp.keyword, fp.group_id, fp.phrase_id, fp.occurrence, fp.special_term, fp.display_term, case fp.expansion_type when 0 then N'Single word case' when 2 then N'Inflectional expansion' when 4 then N'Thesaurus expansion/replacement' end as expansion_type, fp.source_term FROM sys.dm_fts_parser ('FORMSOF(INFLECTIONAL,run ) ', 1033, 0, 0) as fp

查看同义词, 'query_string' 的格式是: 'FORMSOF( THESAURUS, query_term )'
SELECT fp.keyword, fp.group_id, fp.phrase_id, fp.occurrence, fp.special_term, fp.display_term, case fp.expansion_type when 0 then N'Single word case' when 2 then N'Inflectional expansion' when 4 then N'Thesaurus expansion/replacement' end as expansion_type, fp.source_term FROM sys.dm_fts_parser ('FORMSOF(THESAURUS,run ) ', 1033, 0, 0) as fp
六,查看全文索引的元数据
1,查看数据库中的全文索引


select object_name(i.object_id) as TableName, i.unique_index_id, i.fulltext_catalog_id, c.name as fulltext_catalog_name, i.is_enabled, i.change_tracking_state_desc, i.crawl_type_desc, i.has_crawl_completed, iif(i.has_crawl_completed=1,datediff(minute,i.crawl_start_date,i.crawl_end_date),0) as crawl_duration_minute, i.crawl_start_date, i.crawl_end_date, i.incremental_timestamp, i.stoplist_id, i.data_space_id, ds.name as data_space_Name, ds.type_desc as data_sapce_type from sys.fulltext_indexes i inner join sys.data_spaces ds on i.data_space_id=ds.data_space_id inner join sys.fulltext_catalogs c on i.fulltext_catalog_id=c.fulltext_catalog_id
2,查看全文索引的所有分词
declare @db_id int declare @table_id int set @db_id=db_id() set @table_id=object_id(N'schema_name.table_name',N'U') select kw.keyword, kw.display_term, kw.column_id, kw.document_count from sys.dm_fts_index_keywords(@db_id,@table_id) as kw
3,查看单个文档的分词
declare @db_id int declare @table_id int set @db_id=db_id() set @table_id=object_id(N'meetup.Events',N'U') select kw.keyword, kw.display_term, kw.column_id, kw.document_id, kw.occurrence_count from sys.dm_fts_index_keywords_by_document(@db_id,@table_id) as kw
4,查看全文索引的内部表(Internal Tables)
SELECT SCHEMA_NAME(itab.schema_id) AS [schema] ,itab.name AS internal_table_name ,typ.name AS column_data_type ,col.name as column_name ,col.column_id ,OBJECT_NAME(itab.parent_object_id) as base_table_name FROM sys.internal_tables AS itab INNER JOIN sys.columns AS col ON itab.object_id = col.object_id INNER JOIN sys.types AS typ ON typ.user_type_id = col.user_type_id where itab.internal_type_desc=N'FULLTEXT_COMP_FRAGMENT' ORDER BY itab.name, col.column_id;
5,查看每一个倒转索引的大小和包含的数据行数
select object_name(table_id) as base_table_name, object_name(fragment_object_id) as fragment_table_name, fragment_id as Ordinal, status, data_size, row_count, [timestamp] from sys.fulltext_index_fragments
字段 Status 表示索引片段的状态:
- 0 = Newly created and not yet used
- 1 = Being used for insert during fulltext index population or merge
- 4 = Closed. Ready for query
- 6 = Being used for merge input and ready for query
- 8 = Marked for deletion. Will not be used for query and merge source.
当状态值为4或6时,表示索引片段已经是全文索引的一部分,可以被查询,字段
6,查看全文索引填充的状态
通过sys.dm_fts_index_population 查看当前正在运行的填充,每一次填充都会分多个Ranges并行填充,每一个Range可以分多个Batch进行。
select ip.database_id, object_name(ip.table_id,ip.database_id) as table_name, c.name as catalog_name, ip.population_type,ip.population_type_description, ip.is_clustered_index_scan, ip.range_count, ip.completed_range_count, ip.outstanding_batch_count, ip.status, ip.status_description, pr.session_id as Range_SessionID, pr.processed_row_count, ob.batch_id from sys.dm_fts_index_population ip left join sys.fulltext_catalogs c on ip.catalog_id=c.fulltext_catalog_id left join sys.dm_fts_population_ranges pr on ip.memory_address=pr.parent_memory_address left join sys.dm_fts_outstanding_batches ob on pr.memory_address=ob.crawl_memory_address order by ob.batch_id
参考文档:
Manage and Monitor Semantic Search
Create and Manage Full-Text Indexes

 浙公网安备 33010602011771号
浙公网安备 33010602011771号