Neo4j 第二篇:图形数据库
在深入学习图形数据库之前,首先理解属性图的基本概念。一个属性图是有向图,由顶点(Vertex),边(Edge),标签(Lable),关系类型(Relationship Type)和属性(Property)组成。
在属性图形中,节点和关系是最重要的实体,顶点也称作节点(Node),边也称作关系(Relationship)。所有的节点是独立存在的,但是可以为节点设置标签,那么拥有相同标签的节点属于一个分组,也就是一个集合。关系通过关系类型来分组,类型相同的关系属于同一个集合。节点可以有0个、1个或多个标签,但是关系必须设置关系类型,并且只能设置一个关系类型。
关系是有向的,关系的两端是起始节点和结束节点,通过有向的箭头来标识方向,节点之间的双向关系通过两个方向相反的关系来标识。
Neo4j图形数据库的查询语言是Cypher,用于操作和查询属性图,它是图形数据库语言中事实上的标准。
我的Neo4j系列的文章收录在:Neo4j
一,图形数据库的基本概念
使用Neo4j创建的图(Graph)基于属性图模型,在该模型中,每个实体都有ID(Identity)唯一标识,每个节点由标签(Lable)分组,每个关系都有一个唯一的关系类型。
属性图模型的基本概念:
- 实体(Entity)是指节点(Node)和关系(Relationship);
- 每个实体都有一个唯一的ID;
- 通常情况下,节点除了ID属性之外,都会设置Name属性,用于以文本的方式来标识节点,Name属性的值通常是唯一的。
- 每个实体都有零个,一个或多个属性,一个实体的属性键是唯一的;
- 每个节点都有零个,一个或多个标签,属于一个或多个分组;
- 每个关系仅有一个关系类型,关系用于连接两个节点;
- 每个实体都有一个唯一的ID;
- 路径(Path)是指由起始节点和终止节点之间的实体(节点和关系)构成的有序组合;
- 标记(Token)是非空的字符串,用于表示 标签(Lable)、关系类型(Relationship Type)、或属性键(Property Key);
- 标签(Label):用于对节点进行分组,多个节点可以有相同的标签,一个节点可以有多个标签,拥有相同标签的节点属于同一个分组;
- 关系类型(Relationship Type):用于表示关系的类型,多个关系可以有相同的关系类型,但是一个关系仅有一个关系类型;
- 属性键:用于唯一标识一个属性,在一个关系或节点中,属性键是唯一的;
- 属性(Property)是一个键值对(Key/Value Pair),每个节点或关系可以有一个或多个属性;属性值可以是标量类型(Boolean、Integer、Float、String)、或组合类型(List,Map);
二,图形结构的示例
在下面的图中,存在三个节点和两个关系共5个实体,其中 Person和Movie是Lable,ACTED_ID和DIRECTED是关系类型,name,title,roles等是节点和关系的属性键。
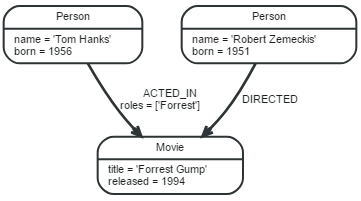
实体包括节点和关系,节点有标签和属性,关系是有向的,链接两个节点,具有属性和关系类型。
1,实体
在示例图形中,包含3个节点和2个关系,这3个节点分别有2个属性:
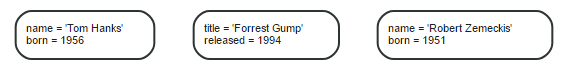
这2个关系分别是:
- 两个关系类型:ACTED_IN和DIRECTED,
- 两个关系:ACTED_IN关系(连接name='Tom Hank'的节点和Movie节点),DIRECTED关系(连接name='Forrest Gump'的节点和Movie节点),
- 其中关系ACTED_IN包含一个属性 roles,属性值是一个List

2,标签(Lable)
在图形结构中,标签用于对节点进行分组,相当于节点的类型,拥有相同标签的节点属于同一个分组。一个节点可以拥有零个,一个或多个标签,因此,一个节点可以属于多个分组。对分组进行查询,能够缩小查询的节点范围,提高查询的性能。
在示例图形中,有两个标签Person和Movie,两个节点是Person,一个节点是Movie,标签有点像节点的类型,每个节点可以有多个标签。
3,属性(Property)
属性是一个键值对(Key/Value),用于为节点或关系提供扩展的信息。一般情况下,每个节点都有name属性,用于命名节点,通常情况下,name属性的值是唯一的。
在示例图形中,Person节点有两个属性name和born,Movie节点有两个属性:title和released,
关系ACTED_IN有一个属性:roles,该属性值是一个List,而关系DIRECTED没有属性:
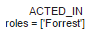
三,遍历(Traversal)
遍历一个图形,是指沿着关系及其方向,访问图形的节点。关系是有向的,以连接的两个节点为单位,从起始节点沿着关系,一步一步导航(navigate)到结束节点的过程叫做遍历,遍历经过的节点和关系的有序组合称作路径(Path)。
在示例图形中,查找Tom Hanks参演的电影,遍历的过程是:从Tom Hanks节点开始,沿着ACTED_IN关系,寻找标签为Movie的目标节点。遍历的路径如图:

四,图形数据库的模式
Neo4j的模式(Schema)通常是指索引、约束和统计,通过创建模式,Neo4j能够获得查询性能的提升和建模的便利;Neo4j数据库的模式可选的,也可以是无模式的。
1,索引
图形数据库也能创建索引,用于提高图形数据库的查询性能。和关系型数据库一样,索引是图形数据的一个冗余副本,通过额外的存储空间和牺牲数据写操作的性能,来提高数据搜索的性能,避免创建不必要的索引,这样能够减少数据更新的性能损失。
Neo4j在图形节点的一个或多个属性上创建索引,在索引创建完成之后,当图形数据更新时,Neo4j负责索引的自动更新,索引的数据是实时同步的;在查询被索引的属性时,Neo4j自动应用索引,以获得查询性能的提升。
例如,使用Cypher创建索引:
CREATE INDEX ON :Person(firstname)
CREATE INDEX ON :Person(firstname, surname)
2,约束
在图形数据库中,能够创建四种类型的约束:
- 节点属性值唯一约束(Unique node property):如果节点具有指定的标签和指定的属性,那么这些节点的属性值是唯一的
- 节点属性存在约束(Node property existence):创建的节点必须存在标签和指定的属性
- 关系属性存在约束(Relationship property existence):创建的关系存在类型和指定的属性
- 节点键约束(Node Key):在指定的标签中的节点中,指定的属性必须存在,并且属性值的组合是唯一的
例如,使用Cypher创建约束:
CREATE CONSTRAINT ON (book:Book) ASSERT book.isbn IS UNIQUE; CREATE CONSTRAINT ON (book:Book) ASSERT exists(book.isbn); CREATE CONSTRAINT ON ()-[like:LIKED]-() ASSERT exists(like.day); CREATE CONSTRAINT ON (n:Person) ASSERT (n.firstname, n.surname) IS NODE KEY;
3,统计信息
当使用Cypher查询图形数据库时,Cypher脚本被编译成一个执行计划,执行该执行计划获得查询结果。为了生成一个性能优化的执行计划,Neo4j需要收集统计信息以对查询进行优化。当统计信息变化到一定的赋值时,Neo4j需要重新生成执行计划,以保证Cypher查询是性能优化的,Neo4j存储的统计信息包括:
- The number of nodes with a certain label.
- Selectivity per index.
- The number of relationships by type.
- The number of relationships by type, ending or starting from a node with a specific label.
默认情况下,Neo4j自动更新统计信息,但是,统计信息的更新不是实时的,更新统计信息可能是一个非常耗时的操作,因此,Neo4j在后台运行,并且只有当变化的数据达到一定的阈值时,才会更新统计信息。
Neo4j keeps the statistics up to date in two different ways. For label counts for example, the number is updated whenever you set or remove a label from a node. For indexes, Neo4j needs to scan the full index to produce the selectivity number. Since this is potentially a very time-consuming operation, these numbers are collected in the background when enough data on the index has been changed.
Neo4j把执行计划被缓存起来,在统计信息变化之前,执行计划不会被重新生成。通过配置选项,Neo4j能够控制执行计划的重新生成:
- dbms.index_sampling.background_enabled:是否在后台统计索引信息,由于Cypher查询的执行计划是根据统计信息生成的,及时更新索引的统计数据对生成性能优化的执行计划非常重要;
- dbms.index_sampling.update_percentage:在更新索引的统计信息之前,索引中有多大比例的数据被更新;
- cypher.statistics_divergence_threshold:当统计信息变化时,Neo4j不会立即更新Cypher查询的执行计划;只有当统计信息变化到一定的程度时,Neo4j才会重新生成执行计划。
参考文档:

