分区表介绍
通常情况下,我们创建的表都是未分区的表,或者说,只有一个分区的表,数据只能存储在一个文件组(File Group)中,默认情况下,表数据存储在PRIMARY文件组。对表进行分区后,每一个分区都独立存储在文件组(File Group)中。把表分区,实际上是把逻辑上完整的表,按照特定的字段拆分成多个分区,每个分区分配到(相同或不同的)FileGroup中,每一个分区在文件组中都是独立存储,即使多个分区分配到相同的文件组中。
为什么要对数据表(Table)分区?这是因为分区(Partition)之间是物理上独立存储的,对单个分区进行操作,不会影响其他分区,这能提高查询性能,避免死锁;而分区切换甚至能够不移动数据,而删除海量数据。
一,创建分区表
在创建表时,使用ON 子句指定存储的逻辑位置:
- on filegroup:表示逻辑存储位置是FileGroup;
- on partition_scheme ( partition_column ) :表示逻辑存储位置是partition scheme,存储引擎按照partition_column把表拆分成多个分区,每一个分区都存储在指定的一个Filegroup中。
CREATE TABLE [schema_name . ] table_name
( <column_definition> )
[ ON { partition_scheme ( partition_column ) | filegroup } ]
分区是表的逻辑存储空间,而分区的物理存储空间是由FileGroup指定的,FileGroup是File的集合,每一个File都属于唯一的FileGroup。把表的存储空间分割到不同的FileGroup中,逻辑上是将table的存储管理体系增加了一层 Partition,介于Table和FileGroup中间,Table的数据存储在Partition,Partition存储在FileGroup中,FileGroup管理着File,File是实际存储data的物理文件。
二:创建分区表的步骤
Step1, 创建分区函数
分区函数的作用是提供分区字段的类型和分区的边界值
CREATE PARTITION FUNCTION [pf_int](int) AS RANGE LEFT FOR VALUES (10, 20)
pf_int 的含义是按照int类型分区,分区的边界值是10,20,left表示边界值属于左边界。两个边界值能够分成三个分区,别是(-infinite,10],(10,20],(20,+infinite)。
Step2,创建分区scheme
分区scheme的作用是为Parition分配FileGroup,Partition Scheme和FileGroup在逻辑上等价,都是数据存储的逻辑空间,只不过Partition Scheme指定的是多个FileGroup。
CREATE PARTITION SCHEME [ps_int] AS PARTITION [pf_int] TO ([PRIMARY], [db_fg1], [db_fg1])
不管是在不同的FileGroup中,还是在相同的FileGroup中,分区都是独立存储的。
Step3,创建分区表
创建分区表,实际上是使用on子句指定table存储的逻辑位置。
create table dbo.dt_test ( ID int, code int ) on [ps_int] (id)
二,查看分区表的元数据
分区表的元数据是指分区函数,分区scheme,分区边界值,分区对应的文件组,这些元数据都能从SQL Server提供的系统视图中查看。
1,查看分区函数
使用系统视图:sys.partition_functions 查看当前数据库中创建的分区函数,使用sys.partition_range_values 查看每个分区的边界值,使用sys.partition_parameters查看分区函数的参数,分区函数的参数是分区表的分区列,分区列是什么不重要,重要的是分区列的数据类型,如下图,分区函数的ID是65536,参数的系统类型system_type_id是56:

从sys.types查看对应的数据类型,类型名称是int,这说明分区列的数据类型必须是int:
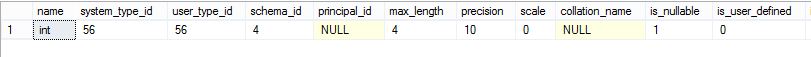
2,查看分区架构(Scheme)
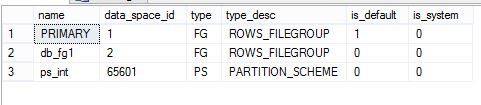
使用系统视图:sys.partition_schemes 查看分区函数对应的分区schema,

分区架构和文件组统称为数据空间(Data Space),data_space_ID 是数据空间的ID,每一个Parition Scheme都有一个唯一的ID,每一个文件组都有一个唯一的数据空间ID。
从sys.filegroups中查看文件组的数据空间ID:

从系统视图:sys.data_spaces 查看数据库中的数据空间,可以看到 sys.data_spaces 是sys.filegroups 和 sys.partition_schemes 结果的并集,这说明,partition scheme和filegroup都是数据存储的逻辑空间。
3,用于存储分区的文件组
一个partition scheme能够使用多个filegroup存储数据,同时一个filegroup可以被多个partition scheme使用,partition scheme和filegroup 之间的关系是many-to-many,SQL Server使用 sys.destination_data_spaces 显示partition scheme和filegroup 之间的关系。
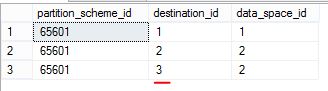
该视图只有三列,显示分区,文件组和分区架构之间的映射:
- partition_scheme_id :标识一个Partition Scheme;
- data_space_id :是 sys.filegroups的data_space_id,用于指定分区存在的哪一个文件组中;
- destination_id :是 分区编号(Partition number)。Partition Number是一个数字,从1开始,从左向右依次加1,对于分区表,最左边的分区,分区编号是1,最右边的分区,编号最大。
4,查看分区的信息
通过sys.partitions 查看每个索引的分区信息,如果 index=0,表示数据表是一个堆表;如果index=1,表示数据表上创建了聚集索引。rows:分区包含的数据行数目。data_compression和data_compression_desc 用于表示分区使用的数据压缩类型。

5,查看分区的统计信息
使用 sys.dm_db_partition_stats 查看分区的统计数据
- used_page_count:分区使用的总的数据页数量
- reserved_page_count:分区保留的总的数据页数量
- row_count:分区存储的数据行数量
三,查看数据表使用的数据空间
系统视图:sys.indexes 包含一个字段 data_space_id,用于指定村粗索引数据的数据空间(Data Space),数据空间是一个文件组或分区架构(Partition Scheme)。两个特殊的index_id,如果index_id=0,表明数据表是一个堆表;如果index_id=1,表明数据表上已经创建聚集索引。数据表上的index_id要么存在1,要么是0,不可能同时存在,实际上,index_id=0 或1, 是数据表本身,而数据表本身要么没有创建聚集索引(堆表结构),要么创建聚集索引(B-Tree结构)。
select object_schema_name(t.object_id) +'.'+ t.name as table_name ,ds.name as data_space ,ds.data_space_id ,ds.type_desc as data_space_type ,ds.type from sys.indexes i inner join sys.tables t on i.object_id=t.object_id and t.type='U' inner join sys.data_spaces ds on i.data_space_id=ds.data_space_id where i.index_id<=1
参考文档:
