部署AlwaysOn第三步:集群资源组的健康检测和故障转移
资源组是由一个或多个资源组成的组,WSFC的故障转移是以资源组为单位的,资源组中的资源是相互依赖的。一个资源所依赖的其他资源必须和该资源处于同一个资源组,跨资源组的依赖关系是不存在的。在任何时刻,每个资源组都仅属于集群中的一个结点,该结点就是资源组的活跃结点(Active Node),由活跃结点为应用程序提供服务。AlwaysOn建立在WSFC的健康检测和故障转移的特性之上,和故障转移集群有了不可分割的关系,因此,从底层的集群资源来理解可用性组,知其然知,其所以然,有助于更好地维护AlwaysOn。
一,AlwaysOn的可用性组是集群的资源组
AlwaysOn的可用性组(Availability Group)是集群的资源组,其资源类型是“SQL Server Availability Group”,由于,WSFC的故障转移是以资源组为单位的,因此,AlwaysOn的每次故障转移都会将整个可用性组里的数据库一起转移。
1,查看集群的资源组
打开故障转移集群管理器(Failover Cluster Manager),选中集群结点,点开Roles,集群的每个角色就是一个资源组,在右边的资源组监控器面板中,能够看到创建成功的可用性组 TestAG,角色类型(Type)是Other;

2,资源组的故障转移属性
右击角色的属性,在Failover Tab中,查看集群的故障转移属性的设置,默认设置如下图:
- 故障转移(Failover)属性:设置集群在指定的时间区间内执行故障转移的次数;
- 故障恢复(Failback)属性:设置集群在发生故障转移之后,把资源组移回到最优先节点;
两者的区别是:
- 故障转移(Failover)是指:出现故障后转移,集群把故障结点拥有的资源组转移到另一个可用的结点上;
- 故障恢复(Failback)是指:出现故障后恢复,在发生故障转移之后,如果最优先结点恢复正常,把资源组移回到最优先节点;
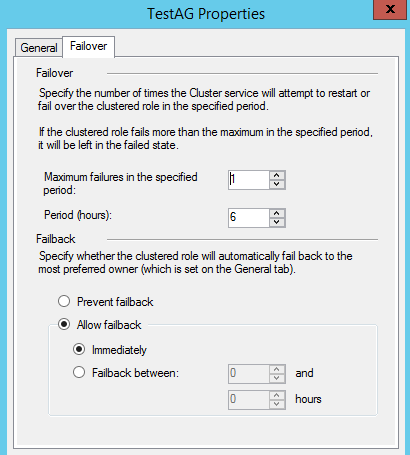
3,切换到General Tab
首选结点(Preferred Owners)选项的默认设置是勾选集群中的所有结点,优先顺序是从上到下,第一个勾选的结点是最优先结点(Most Preferred Owners)。
在发生故障转移之后,如果最优先结点恢复健康,那么故障恢复(Failback)将资源组移回到最优先选结点;

二,从集群资源的角度来看待SQL Server 可用性组
由于AlwaysOn 可用性组建立在故障转移集群之上,可用性组就是Windows 集群的资源组,在故障转移集群管理器中,通过配置集群资源的属性,控制AlwaysOn 可用性组的健康检测和故障转移特性的底层特性。
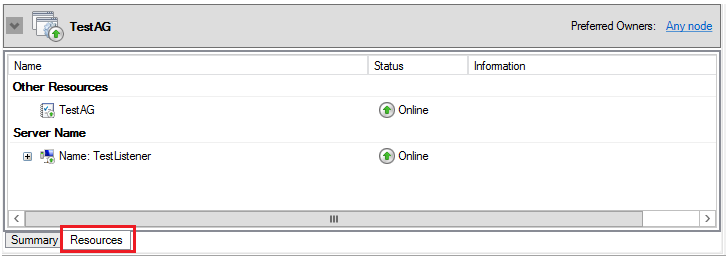
点击角色TestAG下方面板Resource选项卡,能够看到该资源组拥有两个资源:可用性组TestAG和侦听器TestListener。这两个资源在创建AlwaysOn时,由系统自动创建。每个资源,都有Status标识该资源的健康状态。
在Server Name 选项卡中,列出AlwaysOn可用性组中包含的Listener,该Listener 的集群资源类型是Network Name,这就是说,AlwaysOn不使用Windows集群的虚拟网络名和虚拟IP地址,而是使用Listener来作为访问可用性组的网络接口。无论Windows 集群的虚拟网络名,还是AlwaysOn的侦听器Listener,其资源类型都是相同的(Network Name),都有虚拟网络名(DNS Name)和虚拟IP地址,只是一个服务于Windows集群,一个服务于AlwaysOn,其行为是相同的:
- 使用Windows集群的虚拟网络名,用户看不到集群背后的一堆Windows Server,当资源发生故障时,WSFC自动将资源转移到健康的结点上;
- 使用Listener,用户看不到AlwaysOn集群背后的一堆可用性副本,当一个副本发生故障时,AlwaysOn自动转移到健康的副本上;
- 根本差异在于:集群使用共享资源,没有数据的冗余,而AlwaysOn的各个可用性副本(Availability Replica)上都存储数据的一个副本;
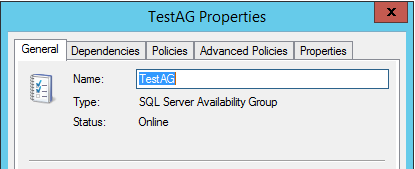
1,集群资源(可用性组)的属性
TestAG资源的类型是SQL Server Availability Group,状态是Online
2,切换到Dependencies Tab,查看资源的依赖关系
资源组中的资源是相互依赖的,一个资源所依赖的其他资源必须和该资源处于同一个资源组,跨资源组的依赖关系是不存在的。资源TestAG 和 资源Server Name之间是“and”的关系,这就是说,只有这两个资源都处于Online状态之后,整个资源组才处于可用的Online状态。
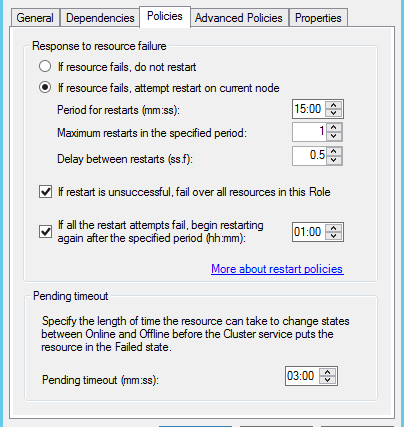
3,切换到Policies Tab,查看资源出现故障时,集群监控器的响应策略
该选项卡的选项决定了资源发生故障转移时的行为,建议保留其默认设置,默认设置是当资源出现故障时,会在15分钟内尝试在当前结点重启(一般是立即尝试重启,不需要等待15分钟),第一次尝试重启失败,就会将整个资源组转移到其他的结点上,默认的关键选项:
选项“If resource fails, attempt restart on current node”:选择该选项,WSFC在检测到当前资源出现故障后,尝试在当前结点重启;
选项 “If restart is unsuccessufll, fail over all resources in this service or application” :勾选该选项,WSFC在第一次重启失败后,将整个资源组转移到集群中的其他结点上;如果不勾选该选项,该资源出现故障,并不会导致整个资源组的故障转移。
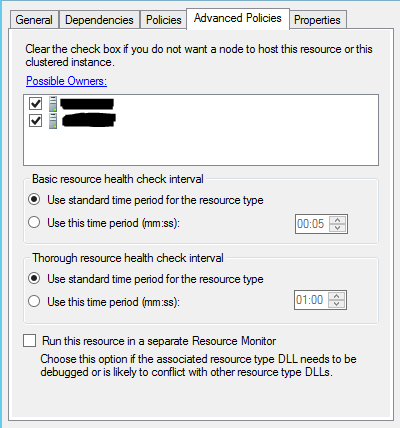
4,切换到Advanced Policies Tab
配置持有资源的集群结点:在Possible Owners 选项卡中,罗列出当前资源能够转移到的结点,也就是指定哪些结点会是当前资源的拥有者;如果一个结点没有被勾选,就意味着当前资源不会在该结点上运行。
配置检测资源健康的时间间隔:WSFC为了检测每个资源是否工作正常,会使用不同的时间间隔来做两种不同程度的检查,对于SQL Server可用组资源类型:
- “Basic resource health check interval” 称作“Looksalive check”,默认的时间间隔是5s;
- “Thorough resource health check interval”称作“Isalive check”,默认的时间间隔是30s;
第三章节会详细描述集群资源的检查检测。
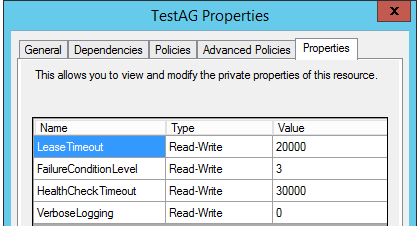
5,切换到Properties Tab,查看和配置资源的私有属性
HealthCheckTimeout属性:健康检测的超时时间,默认设置是30000ms,这就是说,WSFC在认定SQL Server 可用性组资源出现故障之前,需要等待诊断存储过程(sp_server_diagnostics)返回诊断信息的最长时间间隔 ;
诊断存储过程对系统进行诊断的时间间隔的公式是diagnostics_internal=max(5s, HealthCheckTimeout/3),这就是说,sp_server_diagnostics的查询时间间隔是HealthCheckTimeout/3,但不会少于5秒。WSFC会持续收到诊断存储过程返回的结果,如果诊断存储过程在diagnostics_internal时间范围内没有返回结果,就会产生超时错误,WSFC开始0到2次等待,如果在HealthCheckTimeout属性规定的时间范围内,诊断存储过程都没有返回结果,那么WSFC判定健康检查失败,该资源出现故障。也就是说,WSFC最多等待3次诊断存储过程(sp_server_diagnostics)超时未返回,才会判定资源出现故障。
FailureConditionLevel属性:设置资源出现故障的级别,从0到5共6个级别,默认值是3。对于级别1~5,每个级别除了当前级别的条件外,还包括之前级别的所有条件,这意味着级别越高,发生故障转移或重新启动的概率就越大。级别0表示无论发生任何故障,WSFC都不会自动转移或重新启动。
在默认的FailureConditionLevel=3设置下,WSFC连接到可用性主副本上的SQL Server实例,并执行存储过程 sp_server_diagnostics获得可用性组的诊断信息,藉此评估可用组的健康状况。WSFC将存储过程 sp_server_diagnostics的评估结果和FailureConditionLevel属性值相比较,如果满足条件,那么WSFC判定当前的主副本出现故障,并将可用性组切换到新的可用性副本上;
6,故障检测存储过程(sp_server_diagnostics)
系统存储过程 sys.sp_server_diagnostics 用于诊断系统的健康状态,发现潜在的故障,该SP返回的诊断信息对于WSFC判断系统是否执行故障转移是至关重要的,该存储过程只有一个参数:重复间隔的秒数,返回两个重要的字段:
- 字段State:表示组件的健康状态,可能值是:0(Unknown),1(clean),2(warning),3(error);
- 字段component_name:表示组件的类型,可能类型是system,resource,query_processing,io_subsystem,events,availability group;
sp_server_diagnostics [@repeat_interval =] 'repeat_interval_in_seconds'
诊断信息和FailureConditionLevel的关系是:
- 当FailureConditionLevel属性值为3,如果诊断结果返回“系统错误”,表示需要进行故障转移或重新启动;
- 当FailureConditionLevel属性值为4,如果诊断结果返回“资源错误”或“系统错误”,表示需要进行故障转移或重新启动;
- 当FailureConditionLevel属性值为5,如果诊断结果返回“query_processing错误”,“资源错误”或“系统错误”,表示需要进行故障转移或重新启动;
故障检测存储过程(sp_server_diagnostics)返回的组件和可能出现的状态之间的关系如下图:
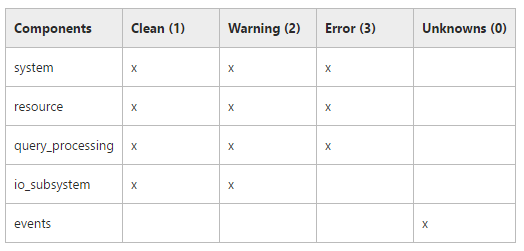
可以看到,只有system,resource和query_processing这三个组件会出现“Error”的运行状态,用于和FailureConditionLevel属性值比较,用作故障转移的条件;而 io_subsystem 的状态只能是Clean或Warning,Events 的状态只能是Unknowns。用户可以手动执行该存储过程,查看服务器诊断的结果:
EXEC sys.sp_server_diagnostics
三,集群资源的健康检测
集群中的每个资源都有一个资源类型,WSFC根据不同类型的资源,使用不同的方式进行Isalive和Looksalive检查,一般会把SQL Server Availability Group资源类型配置成“If resource fails, attempt restart on current node” 和 “If restart is unsuccessufll, fail over all resources in this service or application”模式,即在资源的Policies 选项卡中勾选相应的选项:
Looksalive检查:WSFC检查活跃结点的SQL Server服务(Service Name 是 MSSQLServer)是否处于“启动状态”,根据SQL Server Availability Group资源的Advance Polices 选项卡中的设置,这个检查默认每5s做一次;
Isalive检查:WSFC连接活跃结点,并在活跃结点中执行TSQL查询语句(select @@ServerName),如果活跃结点返回查询的结果,那么Isalive检查成功;如果活跃结点的SQL Server实例连接不上,或没有返回查询结果,那么Isalive检查失败,根据SQL Server Availability Group资源的Advance Polices选项卡中的设置,这个检查默认每30s做一次。
每执行6次Looksalive检查,就会执行一次Isalive检查,WSFC之所以需要对SQL Server 可用性组执行Isalive检查,是因为即使SQL Server 服务处于正在运行(Running)状态,也不能说明SQL Server 可以响应应用程序的请求,有时,可能整个SQL Server实例已经挂起,但是SQL Server服务的状态还是Running,所以需要Isalive 检查深入检查SQL Server的状态。此外,一旦looksalive检查失败,WSFC就会立即执行Isalive检查。
如果Isalive检查失败,WSFC会根据设置,重试3~5次Isalive检查。如果这些检查都失败了,WSFC就根据Polices选项卡中的设置进行故障转移,由集群仲裁选举出新的主副本(Primary Replica),Listener将SQL Server实例名和IP地址指向集群中新的主副本,由其该结点为应用程序继续提供服务,切换的过程是透明的。根据故障转移模式的不同,分为自动故障转移,手动故障转移和强制故障转移,详细信息请阅读《部署AlwaysOn第二步:配置AlwaysOn,创建可用性组》。
四,资源组的故障转移
故障转移完成之后,故障转移的目标辅助副本转换成为主副本,其数据库转换成主数据库,新的主副本重做已经固化的事务日志,回滚尚未提交的事务,使主数据库恢复到原主副本发生故障时的事务一致性的状态;如果原先的主副本从故障中恢复而重新运行,它会发现集群中已经存在新的主副本,于是它就把自己转换为辅助副本,其数据库转为辅助数据。当心的辅助数据库连接上主数据库之后,辅助数据库就开始进行同步操作,执行日志的固化和重做。
1,自动故障转移
在主副本出现故障之后,AlwaysOn迅速将资源组转移到其他辅助副本,使数据库再次变为可用,要发生自动故障转移,必须满足:
- 当前主副本和一个辅助副本都设置为同步提交模式和自动故障转移模式;
- 辅助副本必须和主副本同步,即辅助副本处于SYNCHRONIZED状态;
- 主副本变得不可用,此时将发生自动故障转移;
2,手动故障转移
当主副本和辅助副本可用,并且辅助数据库处于SYNCHRONIZED状态时,可以执行手动故障转移,但是,在手动转移的过程中,如果主副本停止运行,那么辅助副本将进入“RESOLVING”角色,此时,该副本既不是辅助副本,也不是主副本,但可以执行强制故障转移把辅助副本升级为主副本,但是,可能会丢失数据。
通过故障转移集群管理器(Failover Cluster Manager),能够手动执行资源组的转移操作,但是,建议始终通过SSMS执行任意模式的故障转移操作,能够避免操作错误和数据丢失。
3,强制故障转移
一旦执行强制故障转移,主副本尚未发送到原来的辅助副本上的事务日志都会丢失,这意味着,新的主数据库可能会缺少一些最近提交的数据更新,在强制故障转移之后,剩余的辅助副本上的辅助数据库都将处于挂起状态,要重新恢复辅助副本的配置,必须以某个副本上的数据为基础,重新配置可用性组。
五,监控AlwaysOn的健康状态
AlwaysOn的健康状态可以从故障转移集群管理器(Failover Cluster Manager)和SSMS来监控,建议通过SSMS来手动故障转移和监控,配置故障转移集群控制器来对AlwaysOn的异常进行故障排除。
打开SSMS,连接到主副本(Primary Replica)上,点击“AlwaysOn High Availability”能够看到与该SQL Server 实例相关联的可用性组(Availability Group),右击可用性组,打开Dashboard,能够查看可用性组的详细信息,并对可用性组执行手动故障转移操作。
参考文档:
《SQL Server 2012 实施与管理实战指南》第二章

 浙公网安备 33010602011771号
浙公网安备 33010602011771号