PowerBI开发 第21篇:关键因素(Key Influencer)
关键因素(Key Influencer)图表能够帮助用户分析KPI的因素,并按照因素的重要性进行排名,也就是说,该图表可以查看哪些因素会影响到KPI,并计算出因素的相对重要性。使用Key Influencer Visual,不仅可以查看单个因素的影响,还可以查看多个因素构成的组合(称作Segment)对指标的影响。
Key Influencer Visaul 的配置:
- Key Influencers 和 Top Segments,分别用于查看单因素和因素组合对指标的影响。
- Analyze用于指定要分析的指标,该Visual用于分析关于指标的一个问题,例如,What influences Rating to be Low? 对于类别型的指标,值是以下拉列表显示的,下图中Low是Rating的一个值。
- Analyze用于设置进行分析的指标,而Explain by用于设置分析(或解释)指标的维度,维度值是影响指标的因素。
- 底部的Sort by表示排序规则,可以按照Impact和Count对因素进行排序,默认是按照Impact(气泡显示的倍数)排序。当开启计数(Count)时,才会显示Count,并可以按照数量(因素包含的数据样本数量)来排序。当开启Count时,气泡的边缘会有一个环,该环代表Key Influencer包含数据的大致占比,环越趋向完整,包含的数据样本就越多,下图开启了计数。

开启计数(把Counts设置位On),计数的类型有两种:相对计数和绝对计数,绝对计数是指数量的实际值,而相对计数是相对于其他Key Influencer的计数。计数可以帮助用户优先考虑要关注的Key Influence,有时,Key Influencer可以产生重大影响,但包含的数据样本很少。
例如,Theme is usability是低评分的第二大影响因素,但是,可能只有少数客户抱怨可用性。

一,单因素对指标的影响
如果指标的值是类别类型,比如本例的Rating,有两个值:Low和High,选择Low表示要分析对指标起到负作用的因素。
Role in Org的值有三个:publisher、consumer和administrator,而consumer是导致Rating的首要因素。更准确地说,consumer对服务打低分的占比是其他Role in Org的 2.57 倍,Key Influencer Visaul左侧列出Role in Org 为 consumer是导致Rating降低的首要的因素。点击Role in Org is consumer的气泡,右侧显示了每个角色对低评级的可能性:
- 14.93%的消费者给低分。
- 平均而言,所有其他角色给出低评分的占比为 5.78%。
- 与所有其他角色相比,给出低分消费者是均值的2.57 倍,这个数值可以通过将绿色条除以红色虚线来确定。
已知Rating和Role in Org的数据,可以推导出这三个数值的计算逻辑。
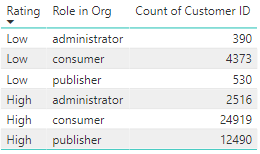
14.93%的消费者给低分,计算的逻辑是:4373位consumer给低分,24919位consumer给高分,给低分的consumer的占比是:4373/(4373+24919)=14.93%。
均值(排除已选择)5.78% 怎么计算的?排除consumer,只计算administrator和publisher给出低评分的占比:(390+530)/(390+530+2516+12490) = 5.78%。
气泡值是单个因素的占比/其他因素的均值,本例中,Role in Org is consumer的气泡值是2.57x,计算逻辑是:14.93% / 5.78% = 2.58, Power BI给出的值是2.57,我猜测是14.9% / 5.8% = 2.569,约等于2.57。
第二个最重要的因素与客户评论的主题(Theme)有关,与评论的其他主题如可靠性(reliability、设计(design)或速度(speed)的客户相比,评论产品可用性(usability )的客户给出低分的可能性是均值的 2.55 倍。评论可用性给出低评分的占比是28.68%,而均值是11.35%。
二,因素组合对指标的影响
选择“Top Segments”来查看因素组合对指标的影响,Top Segments显示Power BI发现的所有Segments的概述,以下示例找到了7个segments,按照Rating is Low的占比和population size进行排序。气泡的大小由population size决定,代表数据样本的数量。segment1的占比是30.8%对指标的影响最大,选择segment1查看更多因素组合的信息。

点击segment1的气泡,查看segment1的构成:
- Role in org is not publisher
- Subscription Type is Premier
- Theme is security
因素的组合占比是30.8%,均值是11.7%,高于均值19.1%,segment1包含1562个数据样本,占总样本数据的比例是3.5%, 占比很小,预示着这个segment1可能不是key influencer。
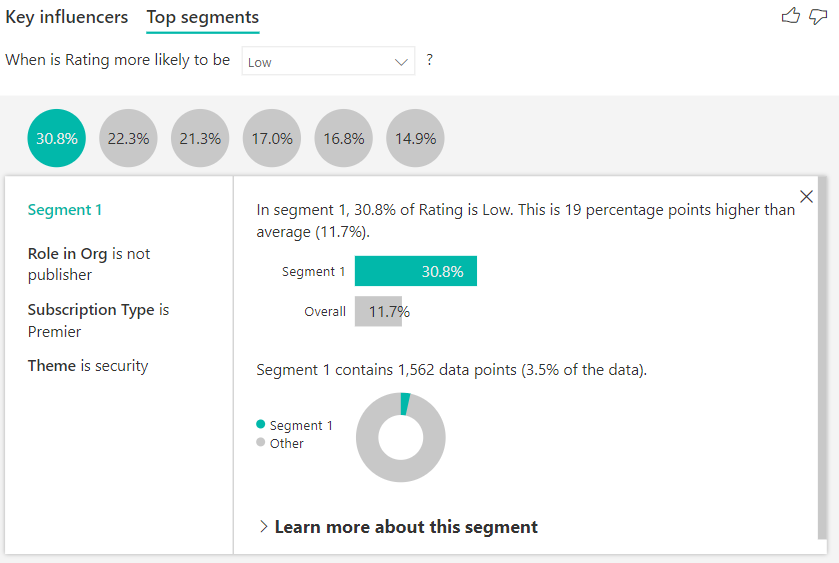
点击“Learn more about this segment”,更深入分析segment1,按照更多的维度来分解segment1。
三,影响指标的三种因素类型
影响指标(Metric)的因素类型可以是类别(categorical),连续的数值(numeric)和度量(measure),类别型指标包含有限的值,通常是文本值,上例中影响Rating的因素都是类别类型。Key Influencer 还能够分析Value是连续数值的因素。
1,把连续的数值解释为关键因素
对于连续的数值类型,分析方法主要是相关性和分箱。如果变量之间的关系不是线性的,那么就不能把这种关系描述为简单地增加或减少。因此,为了更准确表示目标和因素之间的关系,首先进行相关性测试,以确定因素和目标之间的线性程度。如果目标是连续的值,运行Pearson相关;如果目标是分类的,运行Point Biserial相关测试。如果检测到关系不够线性,那么会进行监督分箱(supervised binning),并生成最多五个分箱。 为了找出最有意义的分箱,Key Influencer使用了一种叫做监督分箱的方法,该方法着眼于解释因素和被分析目标之间的关系。
2,把度量或聚合解释为关键因素
用户可以在分析中使用度量和聚合作为解释性因素,例如,您可能想查看客户未结工单的平均持续时间对您收到的评分有什么影响。
四,分析指标的类型
指标的类型,可以是类别(categorical),连续的数值(numeric),度量(measure)或汇总字段三种类型。
1,数值类型的指标
如果把数值字段放到Analyze字段中,可以设置Analysis type为Continuous或Categorical。Metric的值选择increase或decrease,分析的问题是哪一个或哪几个因素导致数值指标的增长或下降。
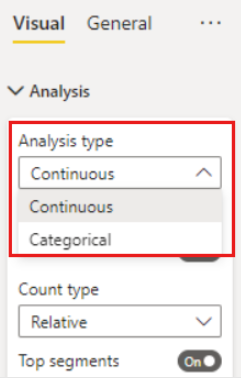
对于分类的(Categorical )分析类型(Analysis Type),可以把分析的问题修改为影响某个值的因素,例如,如果您正在查看从 1 到 10 的调查分数,问题可以是“What influences Survey Scores to be 1?”
对于连续的(Continuous )分析类型(Analysis Type),需要把将分析的问题更改为影响值增长或降低的因素性,比如,“What influences Survey Scores to increase/decrease?”
2,度量或汇总类型的指标
在度量或汇总列的情况下,Analysis type默认为Continuous,并且不能改变。
默认情况下,度量是连续的数值类型,分析度量和未汇总的数值列之间最大的区别是执行分析的数据级别(表级别或模型的维度级别)。
- 对于未汇总的列,分析通常运行在表级别(Table Level)。
- 对于度量或汇总列, Visual会使用Explain by字段指定的字段(或维度)来进行分析,通过这些维度来动态计算度量值,并根据这些维度的值来分析度量值增长或降低的因素。
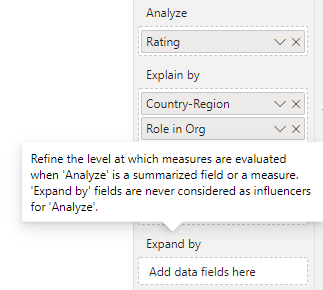
对度量或汇总字段进行分析,通常会用到Expand by功能。当Analyze是一个汇总字段或一个度量时,使用Expand by来细化度量评估的级别,即在更详细的粒度上对数据进行聚合。Expand by指定的字段可以降低度量或汇总字段的聚合级别,但是不会作为影响因素(influencer)出现。也就是说,Expand by指定的字段也会用于分析中,这点跟Explain by的字段的作用相同,但是唯一不同的是,Expand by字段不会作为关键因素。
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号