PowerBI开发 第二十篇:用自然语言来探索数据--Q&A
Power BI报表的用户,肯定会被Q&A的功能惊艳到,在查看报表时,仅仅通过输入文本就可以探索数据,并且结果是可视化的,更令人惊艳的时,结果几乎是实时显示出来的。这使得Q&A Visual就像一个搜索引擎,输入你想查询的问题,Q&A返回一个可视化的结果。
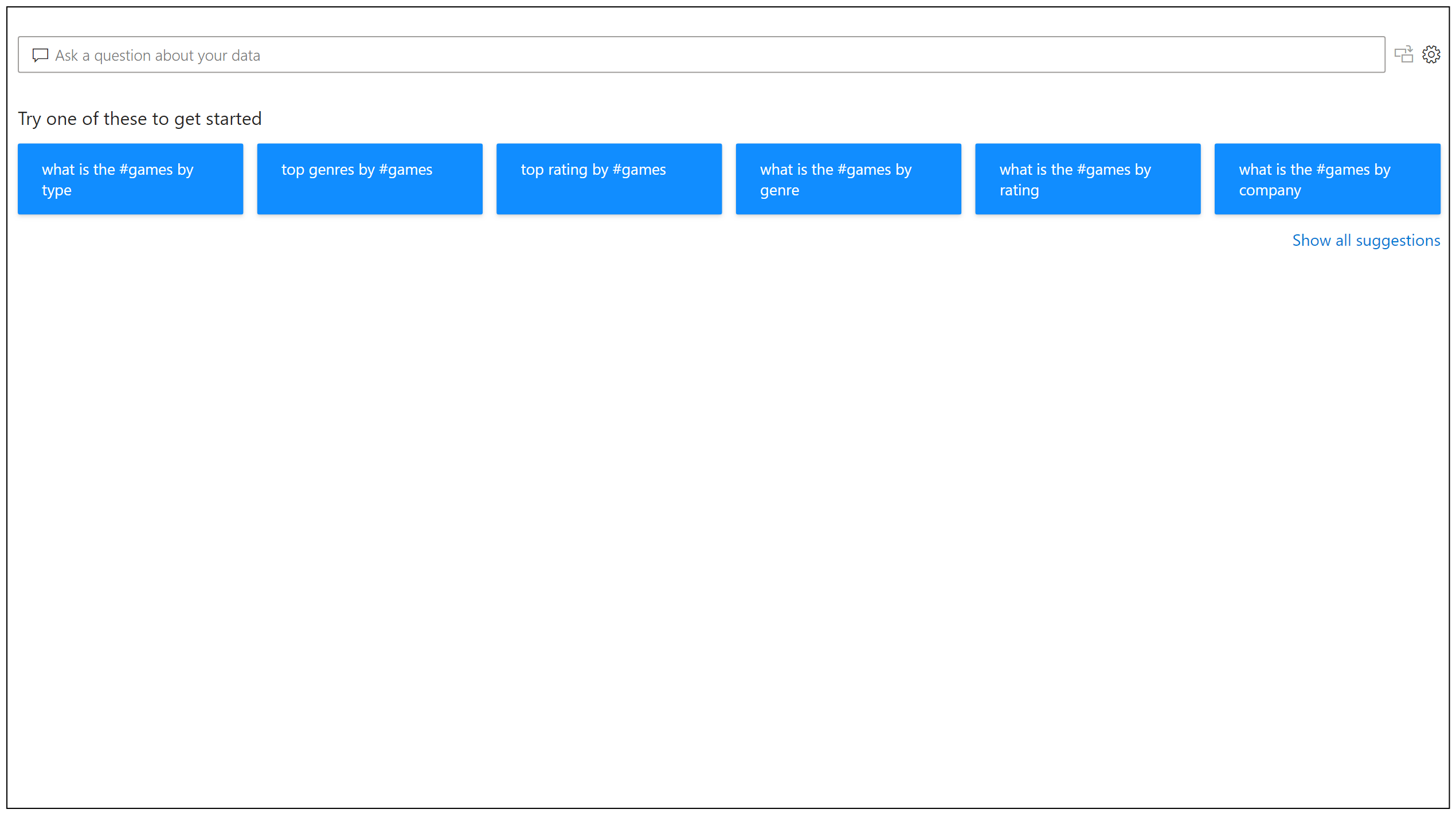
在用户开始输入问题之前,Q&A会显示一些建议问题,如下图所示:
用户也可以输入自己的问题,Q&A支持广泛的问题类型,包括但不限于以下:
- 问极值问题:Which sales has the highest revenue?
- 使用相对日期过滤:Show me sales in the last year
- 仅返回前 N 个:Top 10 products by sales
- 使用过滤条件:Show me sales in the USA
- 使用复杂条件:Show me sales where product category is Category 1 or Category 2
- 使用特定的Visual来显示结果:Show me sales by product as pie chart
- 使用复杂的聚合:Show me median sales by product
- 对结果排序:Show me top 10 countries by sales ordered by country code
- 比较数据:Show me date by total sales vs total cost
- 查看趋势:Show me sales over time
一,Q&A的自动补全和颜色标识
当用户输入问题时,Q&A会显示相关的上下文建议,以帮助用户快速的使用自然语言。同时,在输入问题的同时,用户会立即获得反馈和结果,这种体验类似于在搜索引擎中输入文本:
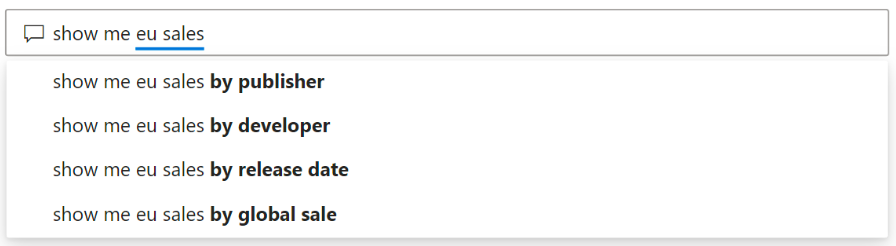
Q&A使用下划线的颜色和类型来帮助用户查看系统理解或不识别的单词。
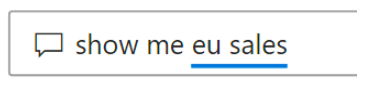
蓝色实心下划线表示表示系统成功地将单词与数据模型中的字段或值匹配,下面的示例显示 Q&A 识别了 EU Sales 这个词。
橙色圆点下划线(下划虚线)表示用户输入的单词被归类为低置信度,如果您键入一个含糊或模棱两可的词,该字段将带有橙色圆点下划线。 举个例子,对于“销售”这个词,数据集中的多个字段可能都包含“销售”一词,因此系统使用橙色虚线下划线提示您选择您想要的字段。 低置信度的另一个例子是,如果您键入单词“area”,但它匹配的列是“region”。 Power BI Q&A 可以识别具有相同含义的单词,这要归功于与 Bing 和 Office 的集成,并且还将报告中的重命名解释为潜在的建议。 Q&A 用橙色圆点在这个词下划线,这样你就知道它不是直接匹配的。
红色实心下划线表示 Q&A 根本识别不了这个词,如果用户输入数据集中不包含的术语,或者数据字段的名称不正确,那么系统会显示红色下划线。 举个例子,如果数据集中不存在“Cost”,Q&A 会用红色下划线标记该词,以表明它没有找到与数据相关的该词。

二,可视化结果
当您输入问题时,Q&A会尝试立即解释问题和可视化答案,并尝试把字段自动绘制到正确的轴上。 例如,如果您键入“Sales by year”,Q&A 会检测到该Year是一个日期字段,并始终优先将此字段放在 X 轴上。
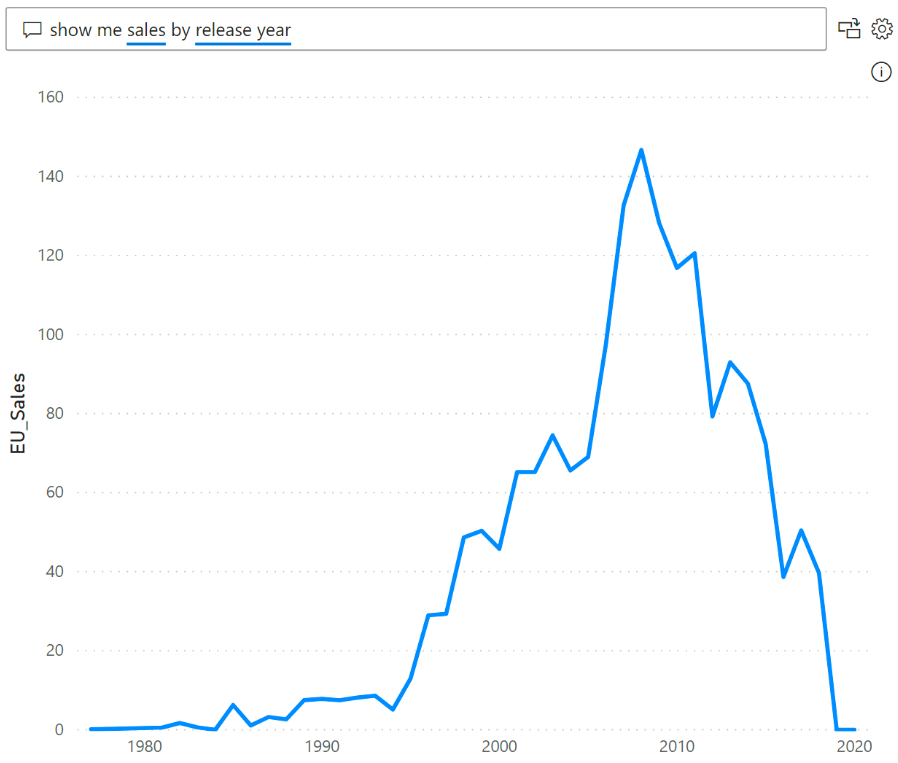
Q&A 目前支持以下的可视化类型:
- Line chart
- Bar chart
- Matrix
- Table
- Card
- Area
- Pie chart
- Scatter/Bubble chart
- Map
三,数据的索引和缓存
Q&A的问答是非常快速的,一旦用户输入问题,立马就可以获得结果,之所以有这么快速的反应,是由于Q&A对数据集做了索引和缓存处理。
1,索引是如何工作的?
当启用Q&A功能时,Q&A会建立一个索引,以便快速向用户提供实时反馈并帮助解释用户的问题。 Q&A需要一些时间来构建索引,并且具有以下特征:
- 所有的列名和表都将插入到索引中,除非明确从Q&A工具中关闭。
- 所有少于 100 个字符的文本值都将被编入索引,超过 100 个字符的文本值不会被编入索引。
- Q&A 将在其索引中存储最多 500 万个唯一值。如果您超过此阈值,索引将不会保留所有可能的值,这可能会降低您从Q&A中获得的结果的准确性。
- 如果在构建索引期间发生错误,索引将保持在部分状态,并将在下一次刷新时重新创建。
在PowerBI Desktop的Options,在CURRENT FILE的Data Load中启用Q&A功能
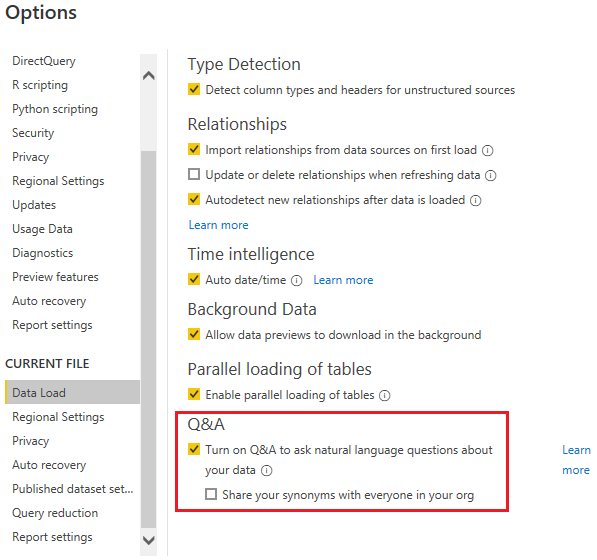
Q&A构建的索引会缓存到系统中,索引需要占用存储空间,用户可以在Data Load的 Q&A Cache Options 中设置缓存的大小,默认是4GB。
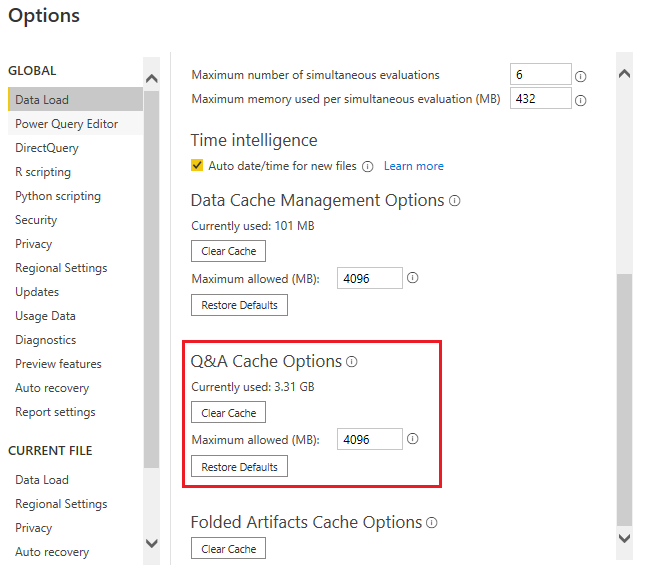
2,多久刷新一次缓存?
在Power BI Desktop中,索引是在使用Q&A时被创建;在Power BI Service中,索引是在发布(publish)或刷新数据集(refresh)时被创建。
在索引创建的时间内,Q&A 会自动生成一些建议的问题,开发人员也可以训练Q&A,来生成更加准确的问题。
四,使用Q&A工具训练Q&A
借助 Power BI Q&A工具,开发人员可以改善Q&A的自然语言体验,开发人员可以在四个方面改进:
- 检查(Review)用户提出的问题;
- 训练(Tech)Q&A理解问题和术语,并管理Q&A在进行训练时理解的术语
- 建议的问题
- 字段的同义词
1,检查(Review)用户提出的问题
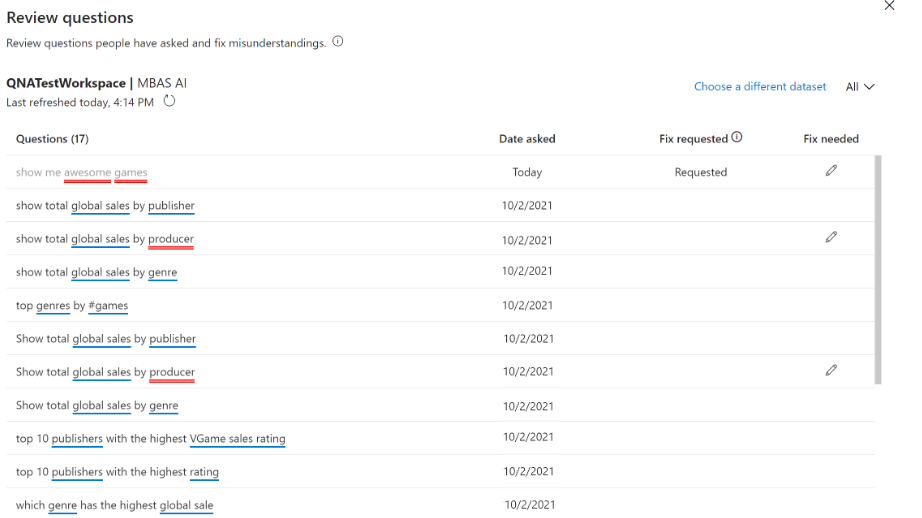
选择Review questions选项卡,可以查看数据集,用户提出的问题。注意,默认情况下,Review questions只会保存过去 28 天的历史数据。
在该对话框中会显示数据集、工作区和上次刷新日期,开发者可以选择一个数据集并查看用户提出的问题,该对话框使用红色下划线显示了未被识别的单词。
2,训练Q&A
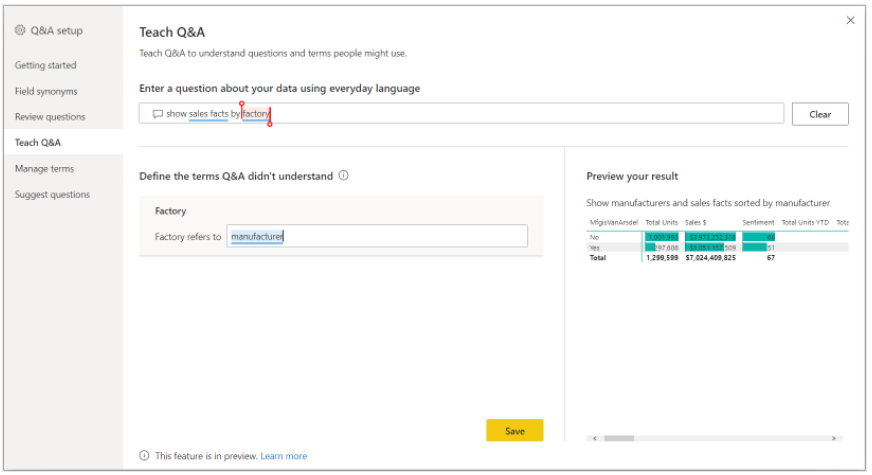
Tech Q&A 用于训练Q&A理解和识别单词。首先,键入一个问题,其中包含 Q&A 无法识别的一个或多个单词,然后,Q&A 会提示您输入该陌生术语的定义,你需要输入与该陌生单词所代表的内容相对应的过滤器或字段名称。
Q&A根据定义重新解释原始问题,如果您对结果感到满意,则可以保存您的输入。
详细的操作是:选择红色下划线标记的单词,Q&A会提供建议,并提示开发人员提供正确的定义。在“Define the terms Q&A didn't understand”中输入正确的定义,点击“Save”,预览结果。
开发者可以训练Q&A理解或记忆两种类型的术语(即同义词):名词和带有条件的名词。
定义一个名词的同义词:在处理数据时,可能会遇到一个字段名称可以用替代name引用的情况,举个例子,“Sales”在某些情况下,可以使用“Revenue”来指代。在这种情况下,可以告诉 Q&A,'Sales' 和 'Revenue' 是相同的。
Q&A 在遇到一个无法识别的单词时,使用来自 Microsoft Office 的知识自动检测单词的词性,如果 Q&A 检测到名词,可能会通过“refers to”方式来提示:

定义带有一个条件的名词:有时您可能想要定义adj+noun,举个例子,'Awesome Publishers'是指:已发布 X 件产品的发布商。 如果Q&A 检测形容词,可能会通过“that have”方式来提示:

如果Products是一个列名,或者是一个Measure,那么可以为Products定义的条件可能是:
- Products > 100
- Products greater than 100
- Products = 100
- Products is 100
- Products < 100
- Products smaller than 100
也可以使用带有聚合函数的表达式来定义:

开发者只能在该"Tech Q&A"中定义一个条件,要定义更复杂的条件,请首先使用 DAX 创建计算列或Measure,然后使用该工具为该列或度量创建带有单个条件的名词。
3,定义字段的同义词
选择“Field synonyms”,可以查看模型中所有的表和列,并添加列名的同义词(替代名称),还可以选择是否从Q&A中隐藏列或表。

该对话框显示报表用户在针对数据集提出问题时可以使用的所有列、表和相应的术语(即同义词)。您可以在该对话框中快速查看Q&A会用到的所有术语,还可以为列添加或删除同义词。
- Add terms:如果有一个字段“Sales”,那么你可能添加“Revenue”的术语,这样用户就可以使用Revenue,而不是必须使用Sales这个词来表示收入。
- Include in Q&A:表示列或表是否包含在Q&A中,如果列或表不包含在Q&A中,那么该表或列会被Q&A忽略,并不会包含在Q&A的索引中。
- Suggested Terms:建议术语(或建议的同义词),这实际上是Q&A推荐的同义词,Q&A利用建议引擎为开发者检索出可能的术语,以帮助开发者快速添加术语(即同义词)。即使Suggested Term未被添加,它们仍然有效,但Q&A会给用户一条橙色虚线的提示,表示 Q&A 认为它有答案但不确定。如果建议的同义词正确,请选择加号图标 (+),以便将其用作同义词。如果建议不正确,请选择 x 以删除该术语,这样它就不会用作术语/同义词,也不会在问答中起作用。最初的建议由 Office 词典提供支持,也可以来自报表中的重命名。获得更多建议术语的另一种方法是通过组织内的synonym sharing(同义词共享)。
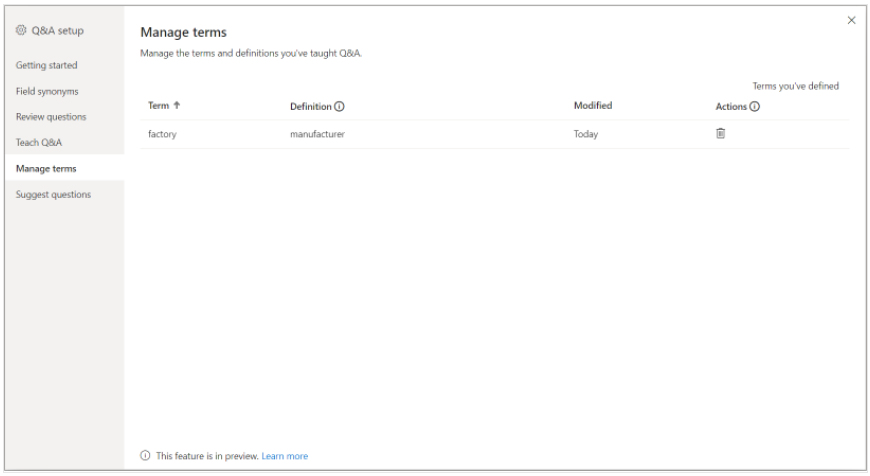
4,管理术语
从“Tech Q&A”和“Field synonyms”中保存的所有内容都会显示在此处,在该窗口中可以查看或删除术语或同义词。
当数据模型逐渐复杂时,“Tech Q&A”和“Field synonyms”保存的术语就会逐渐增多,管理术语成为一个仅凭记忆很难完成的任务,通过使用该该选项卡,很够方便管理在“Tech Q&A”和“Field synonyms”中保存的同义词。
5,建议问题
Q&A不仅可以建议术语,还可以建议问题。在不进行任何设置的情况下,Q&A visual会提示几个开始使用的问题,这些问题是根据您的数据模型自动生成的。在建议问题中,您可以用自己的问题覆盖自动生成的问题。

参考文档:
Introduction: Use natural language to explore data with Power BI Q&A
