DAX :【翻译】数据沿袭(Data Lineage )
数据沿袭实际上存在DAX中的每个角落,它的设计如此好,以至于很多开发人员在不知情的情况使用。
DAX使用数据沿袭来维护关于列值来源的信息。数据沿袭实际上是一个标签(Tag),分配给表中的每一列,此Tag用于标识数据模型中的原始列,即列的值源自于该列。通过数据沿袭,DAX可以利用现有的关系来过滤数据模型。
对列的简单引用会保留数据沿袭,对列执行运算会破坏数据沿袭。
1,对列的简单引用会保留数据沿袭
例如,以下查询返回 Product 表中的不同类别:
EVALUATE VALUES ( 'Product'[Category] )
VALUES 返回的表包含 8 个字符串,然而,它们不仅仅是字符串,DAX还知道这些字符串源自 Product[Category] 列。作为 Product 表的沿袭,它们继承了Product可以通过关系传播来过滤数据模型中其他表的能力,这就是在迭代函数中迭代VALUES ( Product[Category] ) ,创建的行上下文能够转换为过滤 Sales 表的原因。
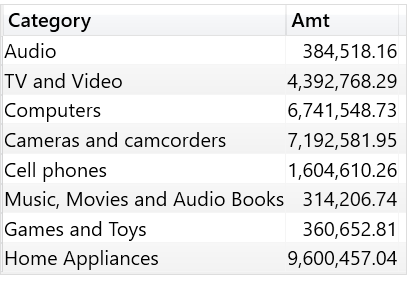
考虑以下查询,通过把行上下文转换为筛选上下文,计算每个Categoyr的销售额。VALUES函数返回的表之所以能够和Sales表进行关联,原因就是VALUES函数会保持数据沿袭,这使得Product和Sales之间的关系不变。
EVALUATE ADDCOLUMNS ( VALUES ( 'Product'[Category] ), "Amt", [Sales Amount] )
2,数据沿袭跟列名和内容无关,仅跟原始列有关系
举个例子,使用DATATABLE创建一个静态表Category,该表和Sales之间没有任何关系,这使得列值“Audio”本身无法过滤 Sales,可以通过运行以下查询轻松检查这一点:
EVALUATE VAR Categories = DATATABLE ( "Category", STRING, { { "Category" }, { "Audio" }, { "TV and Video" }, { "Computers" }, { "Cameras and camcorders" }, { "Cell phones" }, { "Music, Movies and Audio Books" }, { "Games and Toys" }, { "Home Appliances" } } ) RETURN ADDCOLUMNS ( Categories, "Amt", [Sales Amount] )
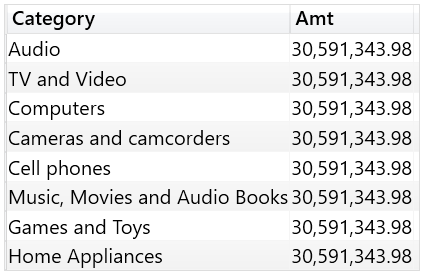
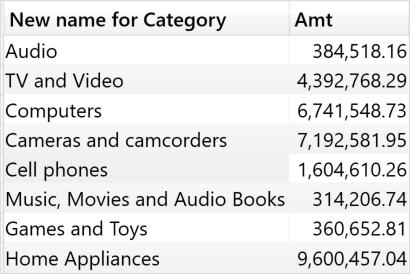
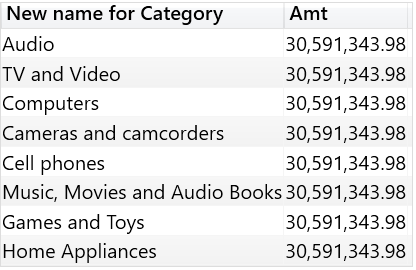
列名和列内容都不重要,真正重要的只是列的数据沿袭,换句话说,值源自于的那个原始列是重要的。如果重命名列,仍会保留数据沿袭。 实际上,以下查询为每一行返回不同的值:
EVALUATE ADDCOLUMNS ( SELECTCOLUMNS ( VALUES ( 'Product'[Category] ), "New name for Category", 'Product'[Category] ), "Amt", [Sales Amount] )
由于列“New name for Category”保留了列Product[Category]的数据沿袭,因此,输出的结果按照Product[Caegory]统计销售额,尽管结果中的列名与原始列名不同。
3,对列执行运算会破坏数据沿袭
只要表达式仅由一个列引用组成,就会保持数据沿袭。例如,在前面的表达式中向 Product[Category] 添加一个空字符串不会更改列内容,但会破坏数据沿袭。
在下面的代码中,列“New name for Category”的来源是一个表达式,而不仅仅是一个列引用,因此,新列的数据沿袭与数据模型的任何列都不相关。
EVALUATE ADDCOLUMNS ( SELECTCOLUMNS ( VALUES ( 'Product'[Category] ), "New name for Category", 'Product'[Category] & "" ), "Amt", [Sales Amount] )
4,每列都有自己的数据沿袭
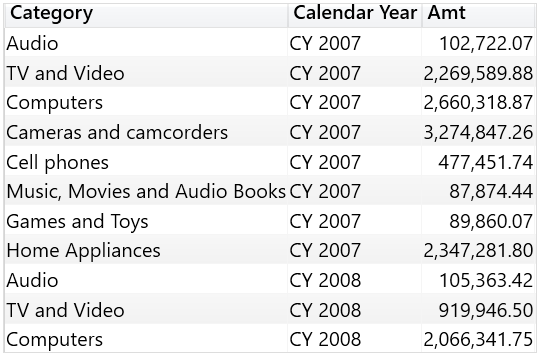
每列都有自己的数据沿袭,即使一个表包含来自不同表的列。因此,表表达式的结果可以一次把过滤器应用于多个表。 这在以下查询中清晰可见,表中包含 Product[Category] 和 Date[Calendar Year],这两列都通过上下文转换产生的筛选上下文把它们的筛选器应用于度量[Sales Amount]。
EVALUATE FILTER ( ADDCOLUMNS ( CROSSJOIN ( VALUES ( 'Product'[Category] ), VALUES ( 'Date'[Calendar Year] ) ), "Amt", [Sales Amount] ), [Amt] > 0 )
结果显示给定的类别和年份的销售额。Category 和 Calendar Year 列都在主动过滤 Sales Amount 度量。
5,使用TREATS函数修改数据沿袭
即使DAX引擎以完全自动的方式保存和维护数据沿袭,开发人员也可以选择更改表的数据沿袭,这就是 TREATAS函数的用途。TREATAS 接受一个表作为它的第一个参数,然后是一个列引用列表。
TREATAS(table_expression, <column>[, <column>[, <column>[,…]]]} )
TREATS函数用于操作数据沿袭,把列和原始列之间建立映射关系,在使用TREATS函数时,注意:
- TREATAS返回一个表,该表包含<column>参数中的所有行,这些行也在 table_expression 中。
- 返回的表中的列和<coloumn>参数指定的列建立数据沿袭映射。如果table_expression 中的某些值与用于应用数据沿袭的<column>参数中的有效值不匹配,那么TREATAS 会从table_expression 中删除这些值。
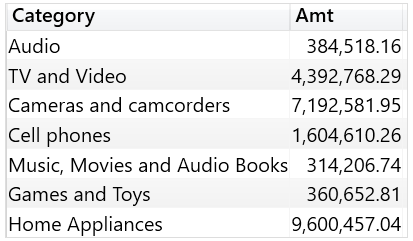
例如,以下查询构建了一个包含字符串列表的表,其中“Computers and geeky stuff”不对应于模型中的任何类别,当使用 TREATAS 把表的数据沿袭强制为 Product[Category]时:
EVALUATE VAR Categories = DATATABLE ( "Category", STRING, { { "Category" }, { "Audio" }, { "TV and Video" }, { "Computers and geeky stuff" }, { "Cameras and camcorders" }, { "Cell phones" }, { "Music, Movies and Audio Books" }, { "Games and Toys" }, { "Home Appliances" } } ) RETURN ADDCOLUMNS ( TREATAS ( Categories, 'Product'[Category] ), "Amt", [Sales Amount] )
由于数据模型没有名为“Computers and geeky stuff”的类别,因此 TREATAS 必须从输出中删除该行以完成数据沿袭转换。
6,操作数据沿袭
现在我们已经了解了数据沿袭是什么以及如何使用 TREATAS 对其进行操作,现在是时候来看一个示例,其中 TREATAS 和数据沿袭操作生成了非常优雅的 DAX 代码。
考虑计算销售额的要求,只过滤每个产品的第一天的销售额。相同的计算逻辑对客户、商店或任何其他维度都有意义,但我们仅考虑此示例中的产品。
每种产品都有不同的首次销售日期,一种选择是按照产品计算每个产品的第一个销售日期,然后计算该日期的销售额,最后汇总所有产品的结果。 以下代码可以正常工作:
FirstDaySales v1 := SUMX ( 'Product', VAR FirstSale = CALCULATE ( MIN ( Sales[Order Date] ) ) RETURN CALCULATE ( [Sales Amount], 'Date'[Date] = FirstSale ) )
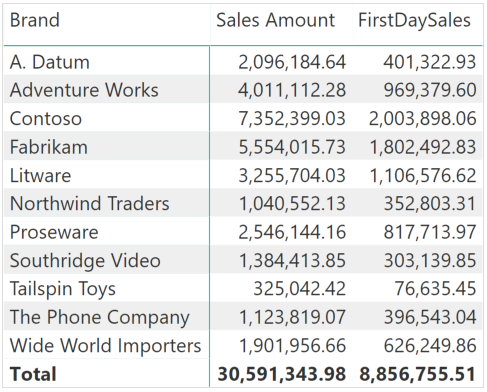
结果是正确的,但上面的代码不是最优的。实际上,它迭代 Product 表,为每个产品生成上下文转换,还在 Date 上应用过滤器,而不是利用任何关系。并不是说这是糟糕的代码,它只是没有它应该的那么优雅。 我们现在将看到该度量的替代版本以更有效的方式返回相同的结果。
朝着正确方向迈出的第一步是构建一个包含产品名称和相应产品的首次销售日期的表ProductsAndFirstDate,然后使用这个表ProductsAndFirstDate对Sales表应用过滤器。下面的代码与之前的代码相比是一个改进,但它仍然不是最优的,因为 SUMX 仍然为每个产品生成一个上下文转换:
FirstDaySales v2 := VAR ProductsWithSales = SUMMARIZE ( Sales, 'Product'[Product Name] ) VAR ProductsAndFirstDate = ADDCOLUMNS ( ProductsWithSales, "Date First Sale", CALCULATE ( MIN ( Sales[Order Date] ) ) ) VAR Result = SUMX ( ProductsAndFirstDate, VAR DateFirstSale = [Date First Sale] RETURN CALCULATE ( [Sales Amount], 'Date'[Date] = DateFirstSale ) ) RETURN Result
但是,请将注意力集中在 ProductsAndFirstDate 变量上,这是ADDCOLUMNS函数的结果,它包含产品名称和日期。如果把这个表用作 CALCULATE 的过滤器参数,它将过滤产品和日期。 因此,这个版本(不幸的是,这是错误的)会更好:
FirstDaySales v3 (wrong) := VAR ProductsWithSales = SUMMARIZE ( Sales, 'Product'[Product Name] ) VAR ProductsAndFirstDate = ADDCOLUMNS ( ProductsWithSales, "Date First Sale", CALCULATE ( MIN ( Sales[Order Date] ) ) ) VAR Result = CALCULATE ( [Sales Amount], ProductsAndFirstDate ) RETURN Result
如您所见,SUMX 迭代从算法中消失了。 然而,这个版本的代码是有缺陷的,因为它返回与销售金额相同的值,而没有应用任何过滤器。实际上,虽然ProductsAndFirstDate包含两列 Product Name和First Date,但从数据沿袭的角度来看,Product Name是 Product[Product Name]的数据沿袭,而 First Sale 列中的日期不是Date[Date]列的数据沿袭,这是 MIN 表达式的结果。 First Sale 列有自己的数据沿袭,与数据模型中的其他表无关。
解决方案是更改 First Sale 列的数据沿袭,使其强制为 Date[Date]。TREATAS 正是为此而存在的。 正确的优化措施如下:
FirstDaySales v4 := VAR ProductsWithSales = SUMMARIZE ( Sales, 'Product'[Product Name] ) VAR ProductsAndFirstDate = ADDCOLUMNS ( ProductsWithSales, "First Sale", CALCULATE ( MIN ( Sales[Order Date] ) ) ) VAR ProductsAndFirstDateWithCorrectLineage = TREATAS ( ProductsAndFirstDate, 'Product'[Product Name], 'Date'[Date] ) VAR Result = CALCULATE ( [Sales Amount], ProductsAndFirstDateWithCorrectLineage ) RETURN Result
虽然最后一个解决方案不是该模式的主要解决方案,但是,在性能方面,这段代码几乎是最佳的。在熟悉数据沿袭之后,请开始考虑在DAX开发中使用上述解决方案,利用数据沿袭使过滤器从一个表移动到另一个表,以写出更高效的代码。
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号