pandas 数据分组——groupby
对DataFrame 和 Series 进行分组之后,会返回一个数据类型为GroupBy的对象。对数据进行分组之后,能够得到一个分组键和一个分组数据,一个分组对应的分组键是唯一的,分组是具有相同分组键的行或列的列表。
分组运算分为三个过程:
- 分组:根据一个或多个字段把数据集(DataFrame或Series)拆分成多个分组
- 应用函数:把一个函数应用到各个分组上产生一个聚合值
- 合并结果:把各个分组产生的聚合值合并到结果
一,数据分组
数据分组是通过groupby()函数实现的,这一节的内容引用于《Pandas教程 | 超好用的Groupby用法详解》,我强烈建议阅读原文,原文写的真棒。
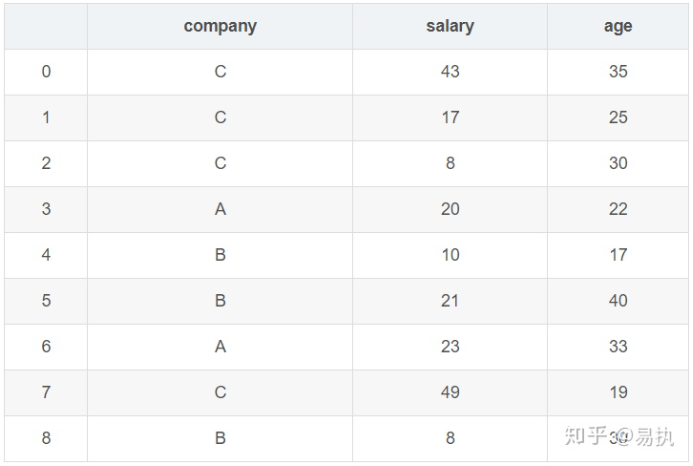
为了后续图解的方便,采用模拟生成的10个样本数据,代码和数据如下:
company=["A","B","C"] df=pd.DataFrame({ "company":[company[x] for x in np.random.randint(0,len(company),10)], "salary":np.random.randint(5,50,10), "age":np.random.randint(15,50,10)
})
在pandas中,实现分组操作的代码很简单,仅需一行代码,在这里,将上面的数据集按照company字段进行划分:
group = df.groupby("company")
执行上述代码后,得到一个DataFrameGroupBy对象
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000002B7E2650240>
那这个生成的DataFrameGroupBy是啥呢?对data进行了groupby后发生了什么?python所返回的结果是其内存地址,并不利于直观地理解,为了看看group内部究竟是什么,这里把group转换成list的形式来看一看:
In [8]: list(group) Out[8]: [('A', company salary age 3 A 20 22 6 A 23 33), ('B', company salary age 4 B 10 17 5 B 21 40 8 B 8 30), ('C', company salary age 0 C 43 35 1 C 17 25 2 C 8 30 7 C 49 19)]
转换成列表的形式后,可以看到,列表由三个元组组成,每个元组中,第一个元素是组别(这里是按照company进行分组,所以最后分为了A,B,C),第二个元素的是对应组别下的DataFrame,整个过程可以图解如下:
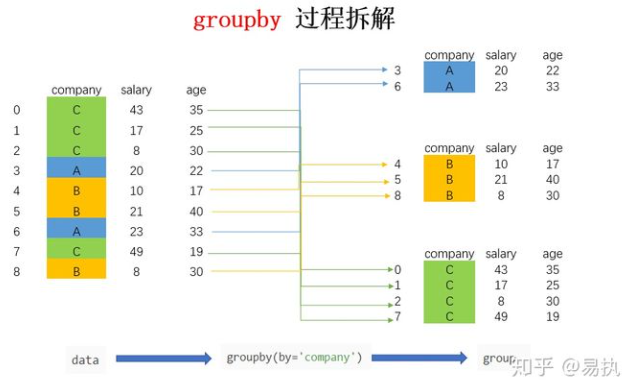
总结来说,groupby的过程就是将原有的DataFrame按照groupby的字段(这里是company),划分为若干个分组DataFrame,被分为多少个组就有多少个分组DataFrame。所以说,在groupby之后的一系列操作(如agg、apply等),均是基于子DataFrame的操作。理解了这点,也就基本摸清了Pandas中groupby操作的主要原理。下面来讲讲groupby之后的常见操作。
二,groupby 函数
对序列或DataFrame对象进行分组,返回分组之后的对象,并可以调用聚合函数获得每个分组的聚合值:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, dropna=True)
Series.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, dropna=True)
参数注释:
- by:用于对序列或DataFrame进行分组,参数by最常用的值是列名或列名列表
- axis:0表示index,1表示columns,默认值是0,按照行(0)或列(1)进行拆分
- level:对于多维索引,按照索引的级别来分组,默认值是0
- as_index:对于聚合输出,返回的GroupBy对象把分组标签作为索引
- group_keys:当调用apply函数时,把分组键(group keys)作为索引来区分分组
- dropna:如果设置为True,当分组键包含NA时,把包含NA的分组键以及对应的值删除掉。
如果by是标签列表,通常是按照列值来对数据进行分组,通常用于数据框(DataFrame)中,按照分组列,对每个列的值进行聚合运算:
>>> df = pd.DataFrame({'Animal': ['Falcon', 'Falcon', 'Parrot', 'Parrot'],
... 'Max Speed': [380., 370., 24., 26.],
... 'Max Age': [38, 30, 20, 16]})
>>> df.groupby(['Animal']).mean()
Max Speed Max Age
Animal
Falcon 375.0 34
Parrot 25.0 18
by参数除了列名和列名列表之外,还可以是mapping和function。
1,当by=函数时,函数作用于对象的索引值上,返回的结果作为分组键。如果索引列包含数据的信息,那么可以使用这种方式来做数据的聚合。
2,当by=mapping时,通过映射的值来对数据进行分组,mapping通常是Series或Dict结构。Series值的数量等同于分组对象的轴的数量,通常是行数。
举个例子,对age按照company进行分组
g=df['age'].groupby(df['company'])
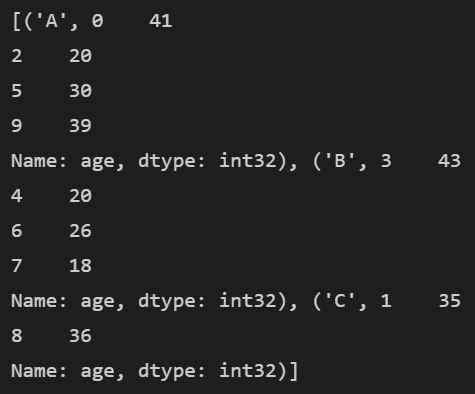
这个结果其实等价于,按照company进行分组,从DataFrameGroupBy结构中选取age列
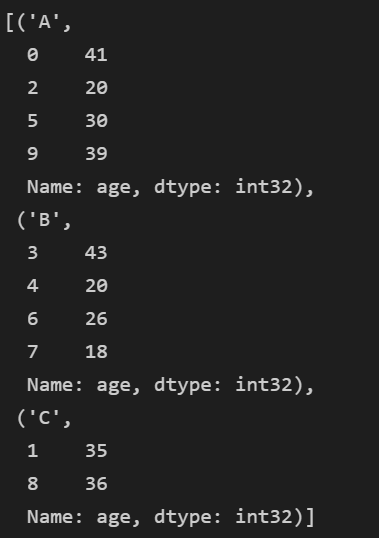
三,GroupBy对象
GroupBy对象是由函数Series.groupby() 或 DataFrame.groupby()返回的对象,GroupBy对象有两个熟悉:groups和indices。
groups是字典结构,表示所有的分组:Dict {group name -> group labels}
indices是字典结构,表示分组的索引键:Dict {group name -> group indices},也就是groupby函数中by参数设置的字段的值。
举个例子,按照Animal字段对fd进行分组,得到GroupBy对象gb:
>>> gb = df.groupby(['Animal'])
gb的属性groups是一个字典结构,key是分组键,值是分组键对应行的索引构成的列表。
>>> gb.groups {'Falcon': Int64Index([0, 1], dtype='int64'), 'Parrot': Int64Index([2, 3], dtype='int64')}
对每个分组,可以计算聚合值,计算相关性等操作,详细操作,可以阅读官方手册 GroupBy。
1,对分组进行迭代
GroupBy对象支持迭代,可以产生一组二元元组,由分组名和分组数据构成。name是由分组键构成,分组数据是按照分组键拆分成的小分组,由分组名称(group name)可以索引GroupBy对象。
for name, group in df.groupby('company'): #print(name) print(group)
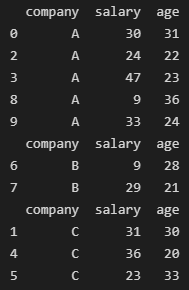
2,获得分组的数据
name是每个分组的名称,可以通过分组name来获得每个分组的数据:
gb=df.groupby('company') gb.get_group('A')
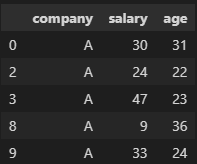
3,groups属性和indices属性
GroupBy的groups和indices属性,返回的结果都是字典类型,key是group name,value是行索引构成的数组或列表。
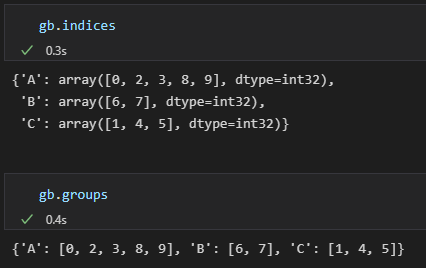
通过这两个属性,可以获得小组的数据:
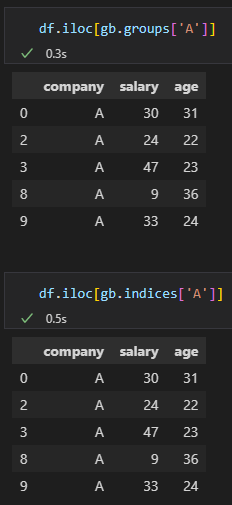
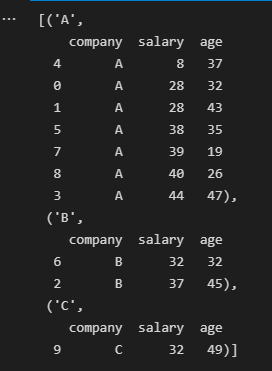
四,分组内数据的排序
由于字典结构没有sort_values()函数,因此不能在分组之后进行排序,但是可以首先对DataFrame进行排序,然后再对DataFrame进行分组。
group=df.sort_values('salary').groupby('company') list(group)
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号