大数据数据仓库建设
作者:原上野
一,数据仓库的数据模型
1. 数据源
数据源,顾名思义就是数据的来源,互联网公司的数据来源随着公司的规模扩张而呈递增趋势,同时自不同的业务源,比如埋点采集,客户上报等。
2. ODS层
数据仓库源头系统的数据表通常会原封不动地存储一份,这称为ODS(Operation Data Store)层, ODS层也经常会被称为准备区(Staging area),它们是后续数据仓库层(即基于Kimball维度建模生成的事实表和维度表层,以及基于这些事实表和明细表加工的汇总层数据)加工数据的来源,同时ODS层也存储着历史的增量数据或全量数据。
3. DW层
据仓库明细层(Data Warehouse Detail , DWD)和数据仓库汇总层(Data Warehouse Summary, DWS)是数据仓库的主题内容。DWD和DWS层的数据是ODS层经过ETL清洗、转换、加载生成的,而且它们通常都是基于Kimball的维度建模理论来构建的,并通过一致性维度和数据总线来保证各个子主题的维度一致性。
4. DWS层
应用层汇总层主要是将DWD和DWS的明细数据在hadoop平台进行汇总,然后将产生的结果同步到DWS数据库,提供给各个应用。
二,数据采集
数据采集的任务就是把数据从各种数据源中采集和存储到数据存储上,期间有可能会做一些简单的清洗。
比较常见的就是用户行为数据的采集
先做sdk埋点,通过kafka实时采集到用户的访问数据,再用spark做简单的清洗,存入hdfs作为数据仓库的数据源之一。
三,数据存储
随着公司的规模不断扩张,产生的数据也越来越到,像一些大公司每天产生的数据量都在PB级别,传统的数据库已经不能满足存储要求,目前hdfs是大数据环境下数据仓库/数据平台最完美的数据存储解决方案。
在离线计算方面,也就是对实时性要求不高的部分,Hive还是首当其冲的选择,丰富的数据类型、内置函数;压缩比非常高的ORC/PARQUET文件存储格式;非常方便的SQL支持,使得Hive在基于结构化数据上的统计分析远远比MapReduce要高效的多,一句SQL可以完成的需求,开发MR可能需要上百行代码;而在实时计算方面,flink是最优的选择,不过目前仅支持java跟scala开发。
四,数据同步
数据同步是指不同数据存储系统之间要进行数据迁移,比如在hdfs上,大多业务和应用因为效率的原因不可以直接从HDFS上获取数据,因此需要将hdfs上汇总后的数据同步至其他的存储系统,比如mysql;sqoop可以做到这一点,但是Sqoop太过繁重,而且不管数据量大小,都需要启动MapReduce来执行,而且需要Hadoop集群的每台机器都能访问业务数据库;阿里开源的dataX是一个很好的解决方案。
五,维度建模
维度建模的基本概念
维度建模(dimensional modeling)是专门用于分析型数据库、数据仓库、数据集市建模的方法。这里牵扯到两个基本的名词:维度,事实。
1、维度
维度是维度建模的基础和灵魂,在维度建模中,将度量成为事实,将环境描述为维度,维度是用于分析事实所需的多样环境。例如,在分析交易过程中,可以通过买家、卖家、商品和时间等维度描述交易发生的环境。
2、事实
事实表作为数据仓库维度建模的核心,紧紧围绕着业务过程来设计,通过获取描述业务过程的度量来表达业务过程,包含了引用的维度和与业务过程有关的度量。事实表中一条记录所表达的业务细节被称之为粒度。通常粒度可以通过两种方式来表述:一种是维度属性组合所表示的细节程度;一种是所表示的具体业务含义。
六,维度建模用到的专业术语
1、 数据域
指面向业务分析,将业务过程活动维度进行抽象的集合。其中,业务过程可以概括为一个个不可分割的行为事件,在业务过程里可以定义指标;维度是指度量的环境,如买家下单事件,买件是维度。为保障整个体系的生命力,数据域是需要抽象提炼并且长期维护更新的,但不轻易变动。在划分数据域时,既要能涵盖所有业务需求,又能在新业务进入时无影响的包含已有的数据还要扩展新的数据域。
2、 业务过程
值企业活动事件,如下单、支付、退款都是业务过程。业务过程是一个不可分割的行为事件。
3、 时间周期
用来名明确数据统计的时间周期或者时间点,如自然月、最近30天,自然周等。
4、 修饰类型
是对抽象词的一种抽象划分。修饰类型从属某个数据域,
如日志域的访问终端涵盖无线端,PC端等修饰词。
5、 修饰词
指除了统计维度以外指标的业务场景限定抽象。修饰词隶属于某一个修饰类型。
6、 度量/原子指标
基于某一业务事件行为下的度量,是业务定义中不可在分割的指标,具有明确的业务含义名词,如支付金额。
7、维度
上述已经做了介绍,不必重述
8、 维度属性
维度属性隶属于某一个维度,如地理维度里面的国家名称,国建id,省份名称等。
9、 事实
上述已经做了介绍,不必重述
10、派生指标
派生指标=一个原子指标+多个修饰词+时间周期。可以理解为对原子指标业务统计范围的圈定。如原子指标:支付金额,最近一天海外买家支付金额为派生指标(最近一天为时间周期,海外为修饰词,买家为维度)。
11、钻取
钻取是改变维的层次,变换分析的粒度。它包括向上钻取(roll up)和向下钻取(drill down)。roll up是在某一维上将低层次的细节数据概括到高层次的汇总数据,或者减少维数;是指自动生成汇总行的分析方法。通过向导的方式,用户可以定义分析因素的汇总行,例如对于各地区各年度的销售情况,可以生成地区与年度的合计行,也可以生成地区或者年度的合计行。
而drill down则相反,它从汇总数据深入到细节数据进行观察或增加新维。例如,用户分析“各地区、城市的销售情况”时,可以对某一个城市的销售额细分为各个年度的销售额,对某一年度的销售额,可以继续细分为各个季度的销售额。通过钻取的功能,使用户对数据能更深入了解,更容易发现问题,做出正确的决策。
七,维度建模的三种模式
1、 星形模式
星形模式(Star Schema)是最常用的维度建模方式,下图展示了使用星形模式进行维度建模的关系结构:
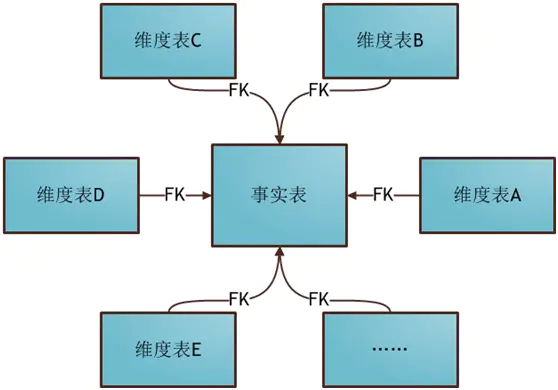
可以看出,星形模式的维度建模由一个事实表和一组维表成,且具有以下特点:
a. 维表只和事实表关联,维表之间没有关联;
b. 每个维表的主码为单列,且该主码放置在事实表中,作为两边连接的外码;
c. 以事实表为核心,维表围绕核心呈星形分布;
2、雪花模式
雪花模式(Snowflake Schema)是对星形模式的扩展,每个维表可继续向外连接多个子维表。下图为使用雪花模式进行维度建模的关系结构:
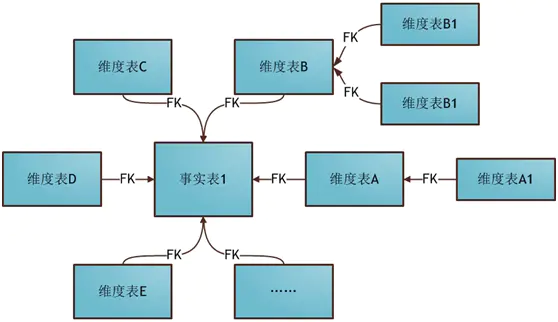
星形模式中的维表相对雪花模式来说要大,而且不满足规范化设计。雪花模型相当于将星形模式的大维表拆分成小维表,满足了规范化设计。然而这种模式在实际应用中很少见,因为这样做会导致开发难度增大,而数据冗余问题在数据仓库里并不严重。
3、星座模式
星座模式(Fact Constellations Schema)也是星型模式的扩展。基于这种思想就有了星座模式:
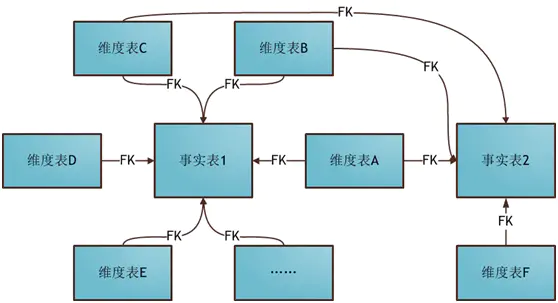
前面介绍的两种维度建模方法都是多维表对应单事实表,但在很多时候维度空间内的事实表不止一个,而一个维表也可能被多个事实表用到。在业务发展后期,绝大部分维度建模都采用的是星座模式。
4、三种模式对比
归纳一下,星形模式/雪花模式/星座模式的关系如下图所示:
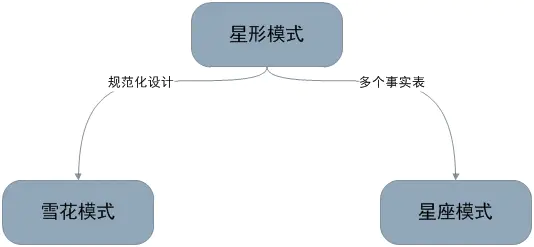
雪花模式是将星型模式的维表进一步划分,使各维表均满足规范化设计。而星座模式则是允许星形模式中出现多个事实表。
参考文档:

