pandas Index 对象 -(创建、转换、排序、设置索引)
Index对象负责管理轴标签、轴名称等元数据,是一个不可修改的、有序的、可以索引的ndarry对象。在构建Sereis或DataFrame时,所用到的任何数据或者array-like的标签,都会转换为一个Index对象。Index对象是一个从索引到数据值的映射,在pandas中,axis=0 表示行索引,用于唯一标识行的位置;axis=1 表示列索引,用于唯一标识列的位置。对于序列,只需要一个索引就可以唯一标识一个cell;对于DataFrame,就需要至少两个索引才可以唯一标识一个cell。
一,索引的构造函数
用于创建索引的最基础的构造函数:
pandas.Index(data,dtype=object,name)
参数注释:
- data:类似于一维数组的对象
- dtype:用于设置索引元素的类型,默认值是object
- name:索引的名称,默认值是Index
举个例子,创建一个整数索引:
>>> pd.Index([1, 2, 3]) Int64Index([1, 2, 3], dtype='int64')
索引是一个ndarray对象,元素的类型相同,每一个Index对象,常用的属性有:
- values:索引的值
- array:以数组形式返回索引元素的值
- dtype:索引元素的数据类型
- name:索引的名称属性
- shape:索引的形状
二,索引的重要作用是数据对齐
Series和DataFrame可以按照索引值进行算术运算。在将对象相加时,相同的索引映射的值进行加法运算,缺失的索引映射的值默认是NA。
举个例子,有两个序列s1 和 s2,计算s1+s2,pandas会按照索引进行加法运算,对于没有对齐的索引,默认值是NaN。
s1=Series([1,2,3,4],index=['a','b','c','d']) s2=Series([10,12,13,14],index=['a','b','c','e']) print(s1+s2)
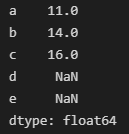
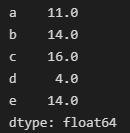
也可以通过Series和DataFrame的函数来设置默认的填充值。下面的例子中,我们设置默认的填充值是0。
print(s1.add(s2,fill_value=0))
三,索引的转换
索引是一个ndarray对象,不仅元素类型可以转换,其对象本身也可以强转为其他like-array类型,比如list、Series和DataFrame。
1,强转索引值的类型
显式把索引元素的类型强制转换成其他数据类型:
Index.astype(self, dtype, copy=True)
2,把索引转换成list
list是由索引的值构成的:
Index.to_list(self)
3,把索引转换成Series
Series的索引值和数据值相同,是由原索引的数据值构成的:
Index.to_series(self, index=None, name=None)
参数index 表示新建Sereis的索引,默认值是None,表示新建Sereis的索引就是原索引。
>>> idx = pd.Index(['Ant', 'Bear', 'Cow'], name='animal') >>> idx.to_series() animal Ant Ant Bear Bear Cow Cow Name: animal, dtype: object
4,把索引转换成DataFrame
创建一个新的DataFrame对象,列的值是由索引值构成的,默认情况下,新DataFrame的索引就是原索引:
Index.to_frame(self, index=True, name=None)
参数index表示是否把原索引作为新创建的DataFrame对象的索引,默认值是True。
>>> idx = pd.Index(['Ant', 'Bear', 'Cow'], name='animal') >>> idx.to_frame() animal animal Ant Ant Bear Bear Cow Cow
5,把索引展开为ndarray对象
该方法和numpy.ravel() 相同,把Index对象展开为一维的ndarray对象:
Index.ravel(self, order='C')
四,索引的排序
按照索引的值进行排序,但是返回索引值的下标,参数 *args和 **kwargs都是传递给numpy.ndarray.argsort函数的参数。
Index.argsort(self, *args, **kwargs)
按照索引的值进行排序,返回排序的副本,参数return_indexer 表示是否返回索引值的下标:
Index.sort_values(self, return_indexer=False, ascending=True)
举个例子,有如下索引:
>>> idx = pd.Index(['b', 'a', 'd', 'c']) Index(['b', 'a', 'd', 'c'], dtype='object')
按照索引值进行排序,返回排序索引的下标:
>>> order = idx.argsort() >>> order array([1, 0, 3, 2])
通过下标来查看索引的排序值:
>>> idx[order] Index(['a', 'b', 'c', 'd'], dtype='object')
当然,也可以直接返回已排序的索引:
>>> idx.sort_values() Index(['a', 'b', 'c', 'd'], dtype='object')
如果要返回已排序的索引和对应的下标,需要设置参数return_indexer=True:
>>> idx.sort_values(return_indexer=True) (Index(['a', 'b', 'c', 'd'], dtype='object'), array([1, 0, 3, 2], dtype=int64))
五,设置索引
数据框有一个函数set_idex() 用于把数据框中的列设置为行索引,对于单级索引来说,函数的参数设置为数据框的一个列名:
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
参数注释:
- keys:对于单级别索引而言,keys是数据框的一个列名
- drop:是否把原始列给删除
- inplace:是否原地替换
- verify_integrity:是否检查新索引值是否重复
举个例子,下面的代码把索引替换为列c:
In [323]: data Out[323]: a b c d 0 bar one z 1.0 1 bar two y 2.0 2 foo one x 3.0 3 foo two w 4.0 In [324]: indexed1 = data.set_index('c') In [325]: indexed1 Out[325]: a b d c z bar one 1.0 y bar two 2.0 x foo one 3.0 w foo two 4.0
数据框还有一个函数reset_index(),用于移除数据框的索引,并把移除的索引作为数据框的新列,然后使用默认的整数范围索引来代替:
DataFrame.reset_index(level=None, drop=False, inplace=False)
参数注释:
- level:索引的级别,默认情况下,移除所有的索引,
- drop:删除的索引是否删除,默认情况下,把移除的索引插入到数据框中作为新列
- inplace:数据库是否原地替换
参考文档:
