正则表达式 第三篇:分组和捕获
分组是用圆括号“()”括起来的正则表达式,匹配出的内容就表示一个分组。分组有一个例外的情况,分组也可以不使用圆括号,而是使用 | 元字符来表示分组,| 的两侧是两个分组,例如, exp1 | exp2 表示两个分组,在严格意义闪给,不认为由 | 构成的正则表达式是分组。
分组和捕获在正则表达式中有着密切的联系,一般情况下,分组即捕获,都用小括号完成:
- (exp) :分组,并捕获该分组匹配到的文本
- (?:exp) :分组,但不捕获该分组匹配到的文本
什么是捕获呢?使用小括号指定一个子表达式后,子表达式匹配的文本(即匹配的内容)可以在其他子表达式中重复使用。
一,定义分组
定义分组的三种形式:
- (exp) :把括号内的正则作为一个分组,系统自动分配组号,可以通过分组号引用该分组;
- (?P<name>exp) :定义一个命名分组,分组的正则是exp,系统为该分组分配分组号,可以通过分组名或分组号引用该分组;
- (?:exp) :定义一个不捕获分组,该分组只在当前位置匹配文本,在该分组之后,无法引用该分组,因为该分组没有分组名,没有分组号,也不会占用分组编号;
1,分组编号
在正则表达式中,分组编号是自动进行的。当使用圆括号表示分组时,从正则表达式的左边开始看,看到的第一个左括号 “(” 表示第一个分组,第二个 "(" 表示第二个分组,依次类推,需要注意的是,有一个隐含的全局分组(分组编号是0),就是整个正则表达式。默认情况下,正则表达式为每个分组自动分配一个组号,规则是:组号从1开始,从左向右,组号依次加1(base+1),例如,第一个分组的组号为1,第二个分组的组号为2,以此类推。
2,分组命名
分组不仅有编号,还能为分组设置名称,在Python中,使用(?P<name>exp)为正则表达式exp设置别名。
3,无捕获分组
无捕获分组没有名称,也没有编号,因此,无法引用无捕获分组,无捕获分组不会占用分组编号。
二,引用分组
引用分组的目的是对重复出现的文本进行匹配,注意,不是出现重复的模式,而是出现重复的文本。由于分组有编号和名称,因此,可以通过名称和编号来引用前面已经出现的分组。
注意,由于正则表达式的解析是有顺序的,从正则表达式的开头向后解析,引用分组的编号和名称,必须是前面已经存在的;如果在当前位置引用的编号和名称不存在,那么模式解析就会报错。
正则表达式中,可以通过分组名或分组号来引用:
- (?P=name):引用名称为name的分组
- \n:使用分组的编号来引用分组,分组按照正则表达式中出现的顺序编号1、2、3、...
1,通过组号引用分组
在正则表达式前面定义一个分组(exp),在表达式的后面,能够通过组号引用该分组的表达式,引用分组的语法是:\group_number;
例如,定义正则表达式,该正则表达式表示两个相同的单词顺序出现:
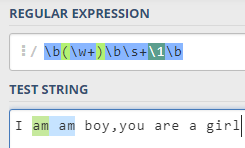
\b(\w+)\b\s+\1\b
在该正则表达式中,只存在一个分组(\w+),组号是1,在该分组的后面,使用\1来引用该分组,将\1替换为分组的子表达式:
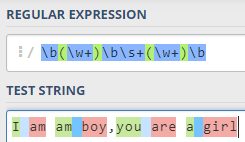
注意,该正则表达式并不等价于:\b(\w+)\b\s+(\w+)\b,该表达式表示两个单词是相邻的:
2,通过分组名引用分组
在正则表达式中,可以对分组命名,命名分组的语法是:(?P<name>exp),分组名是name,通过name来引用该分组的格式是:(?p=group_name),通过分组名和组号引用分组,其引用分组的行为是一样的,例如,定义一个命名分组:\b(?P<word>\w+)\b\s+(?P=word)\b,在该分组的后面中,使用(?P=word)引用该分组,表示文本中出现完全重复的文本。
3,无法引用的分组
(?:exp):使用这种语法定义的分组,不能引用,只能在当前的位置匹配文本,正则表达式不为该分组自动分配组号。
例如,正则表达式:\b(?:\w+)\b\s+\1\b 是错误的,因为无捕获分组不占用组号, 而正则表达式 \b(?:\w+)?(\w+)\b\s+\1\b 是正确的,第二个分组的组号是1,\1引用的是第二个分组。
三,匹配分组的示例
下面使用Python的re模块来演示如何使用分组。
1,匹配任意分组
>>> out=re.match('[0-9]?\d$|100','08') >>> out <re.Match object; span=(0, 2), match='08'>
2,使用()定义分组
>>> out=re.match('\w{4,20}@(163|qq|126)\.com','test@qq.com') >>> out <re.Match object; span=(0, 11), match='test@qq.com'>
3,为分组命名,并通过别名来引用分组
>>> out=re.match(r"<(?P<name1>\w*)><(?P<name2>h[1-5])>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.baidu.com</h1></html>") >>> out <re.Match object; span=(0, 35), match='<html><h1>www.baidu.com</h1></html>'>
4,捕获分组和不捕获分组
对于捕获分组,findall有一个特性,就是如果结果中有捕获的分组,则将捕获的分组组成tuple返回,tuple的元素是每个分组捕获的文本。
>>> re.findall(r'(\d{3,4}-)?(\d{7,8})','020-82228888\n0357-4227865') [('020-', '82228888'), ('0357-', '4227865')]
对于不捕获分组,findall直接返回整个匹配的结果:
>>> re.findall(r'(?:\d{3,4}-)?\d{7,8}','020-82228888\n4227865') ['020-82228888', '4227865']
5,Python对分组引用的支持
引用分组在findall和search中是无效的,但是可以使用在sub函数中。
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号