正则表达式 第二篇:环视
正则表达式在匹配文本时,一般都是按照从左到右的顺序进行的,并且会消耗匹配的字符,环视(look around)能够实现在特定位置向左或向右查看(匹配)。环视结构不占用(消耗)任何字符,只匹配文本中的特定位置,这一点与单词分界符”\b”,锚点”^”和”$”相似,但是环视更加通用。
环视常见的用途是匹配前缀,匹配后缀和寻找重复的单词。
一,环视结构
环视是正则表达式中的特殊结构,环视的正则表达式格式是以 "(?" 开头,以")"结尾,如下所示:
- (?=exp) :肯定顺序环视,向右
- (?!exp) :否定顺序环视,向右
- (?<=exp):肯定逆序环视,向左
- (?<!exp):否定逆序环视,向左
注释:!表示否定,=表示肯定,<表示向左,exp表示环视的正则。
环视查找中的前(左)、后(右)是指位置和与被查找文本的相对位置而言,如果被查找文本在位置之后,称作向右;如果被查找文本在位置之前,称作向左。
1,顺序环视
顺序环视是从左到右查看文本,尝试匹配正则。如果能够匹配,就返回匹配成功信息。顺序环视又分肯定型和否定型,对于肯定性顺序环视(positive look ahead)用特殊的序列”(?=…)”来表示,例如,”(?=\d)” 表示如果当前位置右边的字符是数字,则匹配成功。
2,逆序环视
逆序环视是从右向左查看文本,使用特殊的序列(?<=…)表示,例如,”(?<=\d)” 表示如果当前位置的左边是一位数字,则匹配成功,也就是说,紧跟在数字后面的位置。
二,环视匹配的是位置
环视匹配的是位置,不会消耗字符,也就是说,在检查环视表达式能否匹配的过程中,环视本身不会消耗任何文本。举例说明,对于普通正则表达式”Jeffrey”,在匹配文本”… by Jeffrey Friedl.”时,匹配到的结果是, 
如果使用用环视“(?=Jeffery)” 匹配到的位置如下: 
顺序环视会检查表达式能否匹配,但它只寻找匹配的位置,而不会消耗这些字符。用环视和普通正则表达式结合起来,可以得到更精确的匹配,如“(?=Jeffery)Jeff”表示只能匹配”Jeffery”这个单词中的”Jeff”。
我们还会发现”Jeff(?=ery)”与它是等价的,该例子摘自《<基础-2>入门实例, 顺序环视,逆序环视》。
三,环视用法
环视是一个用于匹配位置的正则表达式,当匹配成功时,返回位置,环视用于查找在特定“位置”之前或之后的文本。
1,后缀匹配
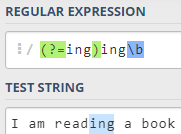
使用(?=exp)来匹配位置,位置的后面匹配表达式exp,返回exp位置之前的表达式。后缀匹配,和TSQL的 "%ing"类似,例如,正则表达式:\b\w+(?=ing\b)

分析:环视的后缀是ing,并且是单词的结尾(\b),匹配以ing结尾的单词,但返回单词的前面部分,ing之前的部分;
例如,查找“I'm reading a book”,它会匹配“read”,因为reanding字符以ing结尾,该正则表达式返回read,环视匹配的是位置。
2,前缀匹配
使用(?<=exp)来匹配位置,位置的前面匹配表达式exp,返回exp位置之后的表达式。前缀匹配,和TSQL的 "re%"类似,例如组,正则表达式:(?<=\bre)\w+\b
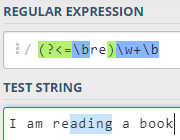
分析:单词的打头(\b),并且前缀是re,匹配以re开头的单词,返回单词的后半部分,即re之后的部分;
例如,查找“I am reading a book”,它会匹配“reading”,因为该字符前面以re打头,该正则表达式返回ading,断言返回的文本不包含前缀。
3,查找文本中重复出现的单词
单词使用\b\w+\b来标识,重复出现通过引用分组来实现:
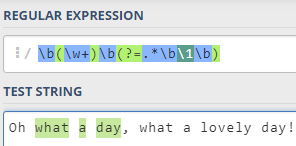
在Python中,通过findall函数来实现:
>>> re.findall(r'\b(\w+)\b(?=.*\b\1\b)', "Oh what a day, what a lovely day!") ['what', 'a', 'day']
4,查找前缀或后缀不是特定文本的文本
下面两个环视,跟前面的环视相反,简单了解一下:
- (?!exp) :文本的后缀不是exp,返回后缀不是exp的表达式
- (?<!exp) :文本的前缀不是exp,返回前缀不是exp的表达式
4.1,后缀不是特定的文本
正则表达式:\b\w+(?!ing\b)
分析:不匹配以ing结尾的单词,查找“I am reading a book”,返回的文本:I,am,a,book
4.2,前缀不是特定的文本
正则表达式:(?<!\bre)\w+\b
分析:不匹配以re打头的单词,查找“I am reading a book”,返回的文本:I,am,a,book
参考文档:

