数据预处理 第6篇:数据预处理(标准化、归一化、分类数据编码和离散化)
sklearn.preprocessing包提供了几个常用的转换函数,用于把原始特征向量转换为更适合估计器的表示。
转化器(Transformer)用于对数据的处理,例如标准化、降维以及特征选择等,提供的函数大致是:
- fit(x,y):该方法接受输入和标签,计算出数据变换的方式。
- transform(x):根据已经计算出的变换方式,返回对输入数据x变换后的结果(不改变x)
- fit_transform(x,y) :该方法在计算出数据变换方式之后对输入x就地转换。
在转化器中,fit_transform()函数等价于先执行fit()函数,后执行transform()函数。有如下的数据,使用preprocessing包对数据进行标准化和归一化处理:
from sklearn import preprocessing import numpy as np X_train = np.array([[ 1., -1., 2.], [ 2., 0., 0.], [ 0., 1., -1.]])
一,数据标准化
数据标准化是指对数据经过处理后,使每个特征中的数值的均值变为0,标准差变为1。
1,标准正态分布
scale()是数据标准化的快捷方式:
X_scaled = preprocessing.scale(X_train)
对应的fit-transform组合是:
scaler = preprocessing.StandardScaler().fit(X_train)
scaler.transform(X_train)
2,把数据缩放到范围
把数据缩放到给定的范围内,通常在0和1之间,或者使用每个特征的最大绝对值按比例缩放到单位大小。
MinMaxScaler(feature_range=(0, 1), copy=True)
MaxAbsScaler(copy=True)
举个例子,MinMaxScaler() 用于把数据按照max和min缩放到0和1之间,其中max和min是缩放区间的最大值和最小值,缩放的公式如下:
X_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
X_scaled = X_std * (max - min) + min
使用MinMaxScaler()函数进行缩放:
scaler = preprocessing.MinMaxScaler(feature_range=(0, 1))
X_scaled=scaler.fit_transform(X_train)
二,数据归一化
通过对原始数据进行线性变换把数据映射到[0,1]或[-1,1]之间,常用的变换函数为:
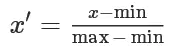
sklearn提供函数normalize或者fit-transform组合来实现数据的归一化。参数norm是用于标准化每个非0数据的范式,可用的值是 l1和l2 范式,默认值是l2范式。
#X_normalized = preprocessing.normalize(X, norm='l2') normalizer = preprocessing.Normalizer( norm='l2').fit(X) normalizer.transform(X) #out array([[ 0.40..., -0.40..., 0.81...], [ 1. ..., 0. ..., 0. ...], [ 0. ..., 0.70..., -0.70...]])
三,对分类属性进行编码
对于文本属性,如果是标称属性,那么该属性用于对数据对象进行分类,可能只有有限多个取值,每个值代表一个类别。机器学习算法无法直接处理文本属性,通常把文本属性转换为数值来处理,这就需要把文本编码为数值。
把分类数据(标称数据)转换为数值编码,以整数的方式表示,对分类数据编码,Scikit-Learn有两种方式:顺序编码 和 OneHot编码。
1,顺序编码
顺序编码把每一个categorical 特征变换成有序的整数数字特征 (0 到 n_categories - 1),然而,这种整数表示不能直接用于所有scikit-learn估计器,因为估计器期望连续输入,并且把类别解释为有序的,但是,集合通常是无序的,无法实现顺序。
使用Scikit-Learn 的 OrdinalEncoder类把属性编码为有序的:
from sklearn.preprocessing import OrdinalEncoder
enc = preprocessing.OrdinalEncoder() X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']] enc.fit(X) enc.transform([['female', 'from US', 'uses Safari']])
#array([[0., 1., 1.]])
有序编码对象中包含 categories_ 属性,用于查看分类数据:
>>> enc.categories_ [array(['female', 'male'], dtype=object), array(['from Europe', 'from US'], dtype=object), array(['uses Firefox', 'uses Safari'], dtype=object)]
把转换的结果 [0., 1., 1.],代入到categories_ 属性中,数组的第一个元素是0,对应categories_ 属性中female类别;数组的第二个元素是1,对应categories_ 属性中from US类别,以此类推。
2,OneHot编码
另外一种将标称型特征转换为能够被scikit-learn中模型使用的编码是OneHot(独热码)、one-out-of-N(N取一编码)或dummy encoding(虚拟编码),这种编码类型已经在类OneHotEncoder中实现,该类把每一个具有n个可能取值的categorical特征变换为长度为n的特征向量,里面只有一个地方是1,其余位置都是0。
>>> from sklearn import preprocessing >>> enc = preprocessing.OneHotEncoder() >>> X = [['male', 'from US', 'uses Safari'], ['female', 'from Europe', 'uses Firefox']] >>> enc.fit(X) >>> enc.transform([['female', 'from US', 'uses Safari']]).toarray() [[1., 0., 0., 1., 0., 1.]] >>> enc.categories_ [array(['female', 'male'], dtype=object), array(['from Europe', 'from US'], dtype=object), array(['uses Firefox', 'uses Safari'], dtype=object)]
如何理解OneHot编码的结果?原始数据中,有三个特征,分别是Gender、From 和 Browser,每个特征有2个取值,OneHot编码在原始数据中新增6个特征,分别是female、male、from Europe、from US、uses Firefox和uses Safari。
对于数据点 ['female', 'from US', 'uses Safari']的取值,对分类数据的编码结果是:[1., 0., 0., 1., 0., 1.],这对应着新增特征(female, male, from Europe, from US, uses Firefox, uses Safari)的取值:

属性categories_ 是长度为n的特征向量,代表新增特征(female, male, from Europe, from US, uses Firefox, uses Safari)。
三,离散化
离散化 (Discretization) 也叫 分箱(binning),用于把连续特征划分为离散特征值。
sklearn.preprocessing.KBinsDiscretizer(n_bins=5, encode=’onehot’, strategy=’quantile’)
参数注释:
n_bins:分箱的数量,默认值是5,也可以是列表,指定各个特征的分箱数量,例如,[feature1_bins,feature2_bins,...]
encode:编码方式,{‘onehot’, ‘onehot-dense’, ‘ordinal’}, (default=’onehot’)
- onehot:以onehot方式编码,返回稀疏矩阵
- onehot-dense:以onehot方式编码,返回密集矩阵
- ordinal:以ordinal方式编码,返回分箱的序号
strategy:定义分箱宽度的策略,{‘uniform’, ‘quantile’, ‘kmeans’}, (default=’quantile’)
- uniform:每个分箱等宽
- quantile:每个分箱中拥有相同数量的数据点
- kmeans:每个箱中的值具有与1D k均值簇最近的中心
举个例子,对于以下二维数组,有三个特征,可以创建分箱数组,为每个维度指定分箱的数量:
from sklearn import preprocessing X = np.array([[ -3., 5., 15 ], [ 0., 6., 14 ], [ 6., 3., 11 ]]) est = preprocessing.KBinsDiscretizer(n_bins=[3, 2, 2], encode='ordinal').fit(X) est.transform(X) #out array([[ 0., 1., 1.], [ 1., 1., 1.], [ 2., 0., 0.]])
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号