SQL Server 内存优化表的索引设计
测试的版本:SQL Server 2017
内存优化表上可以创建哈希索引(Hash Index)和内存优化非聚集(NONCLUSTERED)索引,这两种类型的索引也是内存优化的,称作内存优化索引,和基于硬盘的传统索引有很大的区别:
- 索引结构存储在内存中,没有索引碎片和填充因子
- 对索引所作的更新不会写入事务日志文件,这导致索引的更新操作性能非常高
一,创建内存优化索引
在创建内存优化表的索引时,第一种方式是在创建表时定义索引,第二种方式是先创建内存优化表,然后通过alter table命令修改表结构,向表中添加索引,而表级别的索引语法如下所示:
<table_index> ::= INDEX index_name { [ NONCLUSTERED ] HASH (column [ ,... n ] ) WITH (BUCKET_COUNT = bucket_count) | [ NONCLUSTERED ] (column [ ASC | DESC ] [ ,... n ] ) [ ON filegroup_name | default ] }
举个例子,修改表结构,向表中添加哈希索引,在定义索引时必须设置bucket_count的数量:
ALTER TABLE table_name ADD INDEX idx_hash_index_name HASH (index_key) WITH (BUCKET_COUNT = 64);
二,内存优化索引的性能优化
内存优化索引适用的场景是:
- 非聚集索引 如果查询中包含order by子句、或者包含 where index_column > value等范围扫描操作 ,推荐使用非聚集索引。
- 哈希索引 如果查询中包含点查找(point lookup),例如 where index_column = value,而不是范围扫描,推荐使用哈希索引。
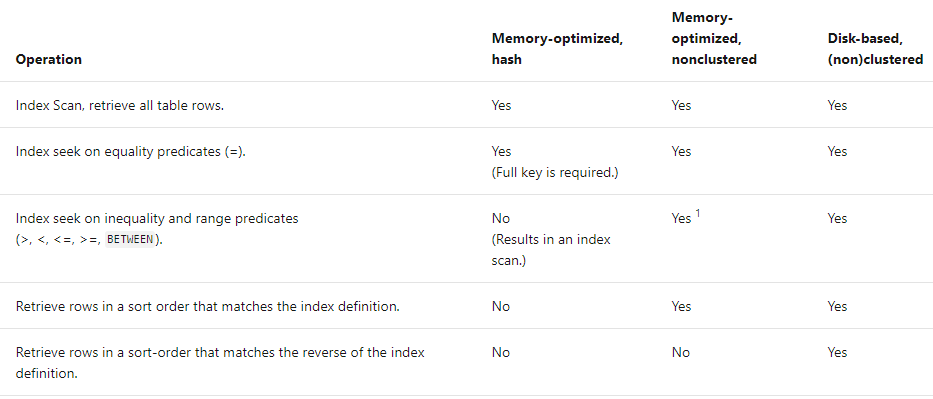
1,哈希索引性能优化
哈希索引是指SQL Server引擎应用哈希函数F(x),把索引键值(Index Key)转换为哈希表(哈希索引)。当哈希值相同,而索引键不同时,称作产生一个哈希冲突。把哈希值相同的索引键链接在一起,组成一个链式结构(chain),也称作冲突链。在查找时,需要遍历冲突链来查找数据,因此,冲突链变长,会降低哈希查找的性能。
哈希冲突是不可避免的,以下两种情况,会产生较多的哈希冲突:
- 如果索引键存在大量的重复值,
- 当hashbucket的数量较少时
这两种情况导致哈希冲突链变长,降低哈希查找的性能,用户可以通过降低索引键的重复值、增加hashbucket的数量来减少哈希冲突。
哈希索引只能点查找(point lookup),并且要求在where子句中应用index key的所有字段、等值条件和与逻辑,例如,哈希索引键是colA和colB,在where子句中必须满足:同时出现所有索引键、等值条件和与逻辑,也就是:where colA= value1 and colB=value2,只有这样,才能使用哈希索引进行点查找,否则无法应用哈希索引。
2,内存优化非聚集索引的优化
内存优化非聚集索引的结构是Bw-Tree,在结构上类似于B-Tree结构,具有树形结构、键值是有序的等特点。
从性能上来看,Bw-Tree索引有三个主要特点:
- 通过无锁(Lock-Free)的方式来操作Bw-Tree树,提升了随机读和范围读的性能。
- 索引按照前序字段进行排序,在查找时,索引键的前序字段非常重要,前序字段必须出现在where/on 子句的条件断言中。
- 适合范围查找,只适用于按照索引定义的排序方向的查找,而不能用于逆向排序的查找
- 通过Log-Structed Storage方式写数据,传统的checkpoint写数据的方式是随机写,而Log-Structed Storage是顺序写,提高写操作的性能。
- 对数据的更新采用Delta Update方式,提高了缓存的命中率。
Bw-Tree结构的索引,和普通的B-Tree结构相比,读写性能提高,解决了高性能读和写不能兼得的问题。
三,内存优化的非聚集索引的结构特点
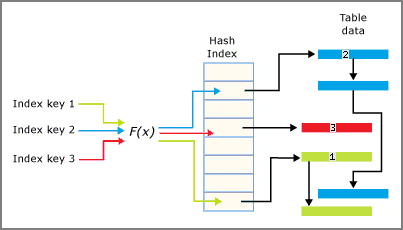
内存非聚集索引类似于B-Tree结构,称作Bw-Tree。从整体上看,Bw-Tree是按照Page ID组织的页面映射。
在Bw-Tree结构中,每个索引Page具有一组有序键值(该结构类似于普通的B树),键值是按照大小顺序排列的,并且索引中包含层次结构,父级别指向子级别,叶级别指向数据行。
差异是Bw-Tree可以把多个数据行连接在一起,索引结构中的页面指针是逻辑页面的ID,这个逻辑页面的ID实际上是页面映射表的偏移量,该映射表具有每个页面的物理地址,通过偏移量找到每个页面在内存中实际的物理地址。
在非叶子级别中,父级别的页面中存储的键值是它指向的子级页面中的键值的最大值,并且每一行还包含该页面逻辑页ID(偏移量)。叶级数据页不仅包含键值,还包含页面的物理地址。
Bw-Tree结构大致如下图所示:有类似B-Tree的树形结构(存储的数据和索引)和Mapping Table(存储逻辑页面ID和物理地址的映射)。
在内存非聚集索引中,没有索引页的就地更新(in-place update),为了实现该目的,引入了新的更新机制:
- 在更新页时,不需要latch 和lock
- 索引页不是固定的大小
Bw-Tree结构解决了B-tree高性能读和写不能兼得的问题,可能会存在性能抖动。
四,哈希索引的结构特点
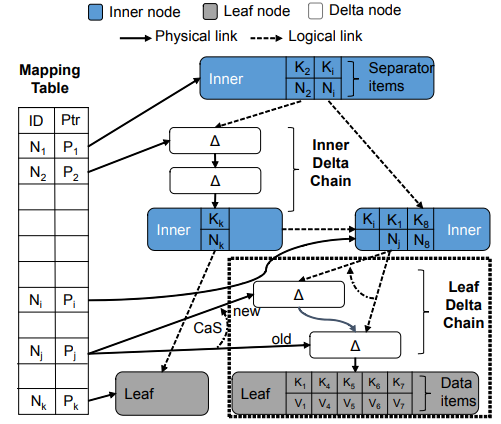
哈希索引包含一个由指针构成的数组,数组中的每个元组叫做一个hash bucket:
- 每个hash bucket占用8Bytes,用于指向key entry构成的链式列表
- 每个entry主要由索引键的值、对应的数据行的地址和指向下一个entry的指针构成
- 每个entry有一个指针,用于指向链中下一个entry,通过这种方式,entry构成链式结构
哈希索引的结构,如下图所示,左侧是哈希表,右侧上一是表数据(Name、City)+时间戳+索引指针,右侧中下的两行是表数据,中间通过Index prt链接为一个chain。
hash bucket的数量必须在索引定义时指定:
- 哈希索引的hash bucket的最大数量是 1,073,741,824
- 较短的链式列表比较长的链式列表性能更好
- hash bucket的数量与表中唯一值的数量的比值越低,每个hash bucket指向的链式列表的长度越长,性能越差。因此,应该适当增加hash bucket的数量。
- 理想情况下,hash bucket最好是表中唯一值数量的1到2倍。
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号