AC自动机学习笔记
AC自动机学习笔记
AC自动机就是KMP和Trie树的结合体,KMP用于单模式串的字符串匹配,AC自动机用于多模式串字符串匹配,比如说我们在一个文章中寻找一个单词可以用KMP,然后找多个单词的话,就得使用AC自动机来解决了。
实现AC自动机
具体思路
首先用模式串构造Trie树,我们这里放she,he,say,shr,her来当示例
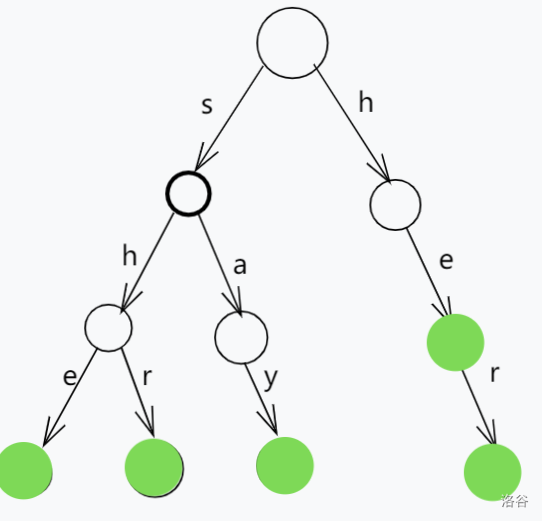
我们在kmp算法中还定义了一个失配指针
那么我们也可以在AC自动机里面也弄一个是失配指针
然后由于每次向下更新
橙色的就表示
kmp
AC自动机
匹配过程通过类比KMP算法也很容易解决:
这段代码匹配的是以
优化为trie图
消耗时间最多的语句是:
由于我们不断的往上跳
那么我们的优化思路是这样的,更改 trie ,使得我们一次性就可以达到我们想要的位置
我们知道,在匹配的时候,如果当前匹配的字符是
所以我们得到的策略就是,当
当存在这个儿子的时候仍然只需要将这个儿子的
代码如下:
匹配过程也可以去掉 while 循环了。
https://blog.csdn.net/weixin_53360179/article/details/119718426
__EOF__

本文链接:https://www.cnblogs.com/ljfyyds/p/16567635.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!
· .NET10 - 预览版1新功能体验(一)