

python多进程
进程概念:
1、是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,是操作系统结构的基础。在早期面向进程设计的计算机结构中,进程是程序的基本执行实体;在当代面向线程设计的计算机结构中,进程是线程的容器。程序是指令、数据及其组织形式的描述,进程是程序的实体。
2、对于操作系统来说,一个任务就是一个进程,比方说打开浏览器就是启动一个浏览器的进程
3、进程是操作系统中最基本、重要的概念。是多道程序系统出现后,为了刻画系统内部出现的动态情况,描述系统内部各道程序的活动规律引进的一个概念,所有多道程序设计操作系统都建立在进程的基础上
进程和程序的区别
程序是指令和数据的有序集合,其本身没有任何运行的含义,是一个静态的概念
而进程是程序在处理机上的一次执行过程,它是一个动态的概念
程序可以作为一种软件资料长期存在,而进程是有一定生命期的。
程序是永久的,进程是暂时的
进程并发和并行
并发:如果系统只有一个CPU,实际就是交替执行任务,之后交替比较快
是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机上运行,但任一个时刻点上只有一个程序在处理机上运行,是指系统具有处理多个任务的能力。黑线代表同一个cpu,红块代表处理任务

并行:多核cpu.当系统有一个以上CPU时,则线程的操作有可能非并发。当一个CPU执行一个线程时,另一个CPU可以执行另一个线程,两个线程互不抢占CPU资源,可以同时进行,这种方式我们称之为并行(Parallel)。简言之,是指系统具有同时处理多个任务的能力。 黑线表CPU,红色代表cpu

进程优点
稳定性高,一个进程山崩溃了,不会影响其他进程
进程缺点
开销比较大
windows查看进程--任务管理
启动进程的步骤
1、引入进程包 multiprocessing
2、编写函数
3、创建启用进程
linux 下可以使用fork函数创建进程。在windows系统multiprocessing模块
linux是多任务系统
Process 功能介绍
Process([group [, target [, name [, args [, kwargs]]]]]),由该类实例化得到的对象,表示一个子进程中的任务(尚未启动)
强调:
1. 需要使用关键字的方式来指定参数
2. args指定的为传给target函数的位置参数,是一个元组形式,必须有逗号
参数介绍:
1 group参数未使用,值始终为None
2 target表示调用对象,即子进程要执行的任务
3 args表示调用对象的位置参数元组,args=(1,2,'egon',)
4 kwargs表示调用对象的字典,kwargs={'name':'egon','age':18}
5 name为子进程的名称
Process 方法介绍
1 p.start():启动进程,并调用该子进程中的p.run()即启动进程并且执行进程 2 p.run():执行这个任务,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法。没有启动进程 3 p.terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁 4 p.is_alive():如果p仍然运行,返回True 5 p.join([timeout]):主线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间,需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
Process 属性介绍
1 p.daemon:默认值为False,如果设为True,代表p为后台运行的守护进程,当p的父进程终止时,p也随之终止,并且设定为True后,p不能创建自己的新进程,必须在p.start()之前设置 2 p.name:进程的名称 3 p.pid:进程的pid 4 p.exitcode:进程在运行时为None、如果为–N,表示被信号N结束(了解即可) 5 p.authkey:进程的身份验证键,默认是由os.urandom()随机生成的32字符的字符串。这个键的用途是为涉及网络连接的底层进程间通信提供安全性,这类连接只有在具有相同的身份验证键时才能成功(了解即可)
#启一个进程
from multiprocessing import Process
def func(n):
print(n)
if __name__ == '__main__':
p1 = Process(target=func,args=("1",))
p1.start()
#启多个进程
from multiprocessing import Process
def func(n):
print(n)
if __name__ == '__main__':
plist=["p1","p2"]
for p in plist:
p = Process(target=func,args=("2",))
p.start()
#继承进程 from multiprocessing import Process def func(n): print(n) class MyProcess(Process): def run(self): print("进程") if __name__ == '__main__': myprocess = MyProcess() myprocess.start()
#启动多个进程 import multiprocessing import time def func_a(): print("进程func_a") time.sleep(0.5) def func_b(): print("进程func_b") time.sleep(0.5) if __name__ == '__main__': p1 = multiprocessing.Process(target=func_a) p2 = multiprocessing.Process(target=func_b) p1.start() p2.start()
#不加进程,会一直进行func_a 函数,不执行func_b()函数
import multiprocessing
import time
def func_a():
while True:
print("进程func_a")
time.sleep(0.5)
def func_b():
while True:
print("进程func_b")
time.sleep(0.5)
if __name__ == '__main__':
func_a()
func_b()
# 这样多进程就是打2次任务2,1次任务1 import multiprocessing import time def func_a(): while True: print("进程func_a") time.sleep(0.5) def func_b(): while True: print("进程func_b") time.sleep(1) if __name__ == '__main__': p1=multiprocessing.Process(target=func_a) p2=multiprocessing.Process(target=func_b) p1.start() p2.start()
区别主进程和子进程
1、通过进程号判断主进程还是子进程
2、debug的时候断点要加在子进程,如果在主进程是无法看到的子进程的代码
os.getpid() 获取当前进程号 os.getppid() 获取当前父进程号
import multiprocessing import time,os def func_a(): while True: print("进程func_a",os.getpid(),'^^^^^^^^^^^^^^^^^^^^^^^',os.getppid()) time.sleep(0.5) def func_b(): while True: print("进程func_b",os.getpid(),'^^^^^^^^^^^^^^^^^^^^^^^',os.getppid()) time.sleep(1) if __name__ == '__main__': print(os.getpid()) p1=multiprocessing.Process(target=func_a,name='任务1') #开始子进程 p2=multiprocessing.Process(target=func_b,name='任务2') #开始子进程 p1.start() #主进程启动子进程 print(p1.name) #主进程 p2.start() #主进程启动子进程 print(p2.name)#主进程

进程参数
import multiprocessing import time,os def func_a(s,name): while True: print("进程func_a",os.getpid(),s,'^^^^^^^^^^^^^^^^^^^^^^^',os.getppid(),name) time.sleep(0.5) def func_b(s,name): while True: print("进程func_b",os.getpid(),s,'^^^^^^^^^^^^^^^^^^^^^^^',os.getppid(),name) time.sleep(1) if __name__ == '__main__': print(os.getpid()) p1=multiprocessing.Process(target=func_a,name='任务1',args=(1,"aa")) #开始子进程 p2=multiprocessing.Process(target=func_b,name='任务2',args=(2,"bb")) #开始子进程 p1.start() #主进程启动子进程 print(p1.name) #主进程 p2.start() #主进程启动子进程 print(p2.name)#主进程
1 #终止进程 2 import multiprocessing 3 import time,os 4 def func_a(s,name): 5 n=1 6 while True: 7 print("进程func_a",os.getpid(),s,'^^^^^^^^^^^^^^^^^^^^^^^',os.getppid(),name) 8 time.sleep(0.5) 9 10 def func_b(s,name): 11 n=2 12 while True: 13 print("进程func_b",os.getpid(),s,'^^^^^^^^^^^^^^^^^^^^^^^',os.getppid(),name) 14 time.sleep(1) 15 16 number = 1 17 if __name__ == '__main__': 18 print(os.getpid()) 19 p1=multiprocessing.Process(target=func_a,name='任务1',args=(1,"aa")) #开始子进程 20 p2=multiprocessing.Process(target=func_b,name='任务2',args=(2,"bb")) #开始子进程 21 p1.start() #主进程启动子进程 22 print(p1.name) #主进程 23 p2.start() #主进程启动子进程 24 print(p2.name)#主进程 25 # func_a() 26 # func_b() 27 while True: 28 number +=1 29 if number == 10: 30 time.sleep(0.5) 31 p1.terminate() # 终止P1进程 32 p2.terminate() # 终止p2进程 33 break 34 else: 35 print("number:",number) 36 print("…………………………………………………………………………")
#不加休眠,进程和顺序是无法控制 #进程对全局变量操作是 子进程和主进程都可以拿到全局变量的值,做各个的更改。
#m=2,全局变量与可变类型和不可变类型没有关系 import multiprocessing import time,os m=2 def func_a(s,name): global m while True: time.sleep(0.5) m+=1 print("进程func_a",m) def func_b(s,name): global m while True: time.sleep(1) m += 1 print("进程func_b",m) if __name__ == '__main__': p1=multiprocessing.Process(target=func_a,name='任务1',args=(1,"aa")) #开始子进程 p2=multiprocessing.Process(target=func_b,name='任务2',args=(2,"bb")) #开始子进程 p1.start() #主进程启动子进程 p2.start() #主进程启动子进程 while True: time.sleep(0.5) m+=1 print("主进程",m)

进程共享变量value
multiprocessing.Value(typecode_or_type, *args[, lock])

字符串
from ctypes import c_char_p
ss = Value(c_char_p, 'ss')
ctype类型可从下表查阅
#共享数字
def func_a(name): name.value=10.88 print("进程func_b",name) if __name__ == '__main__': name=multiprocessing.Value("d",4.5) print("主线程",name.value) p1=multiprocessing.Process(target=func_a,args=(name,)) #开始子进程 p1.start() #主进程启动子进程 p1.join() print("主线程",name.value)

#共享数组
def func_a(name):
name[2]=999
print("进程func_b",name)
if __name__ == '__main__':
name=multiprocessing.Array("i",[1,2,3,4])
print("主线程:在子进程之前",name[:])
p1=multiprocessing.Process(target=func_a,args=(name,)) #开始子进程
p1.start() #主进程启动子进程
p1.join()
print("主线程:在子进程之后",name[:])
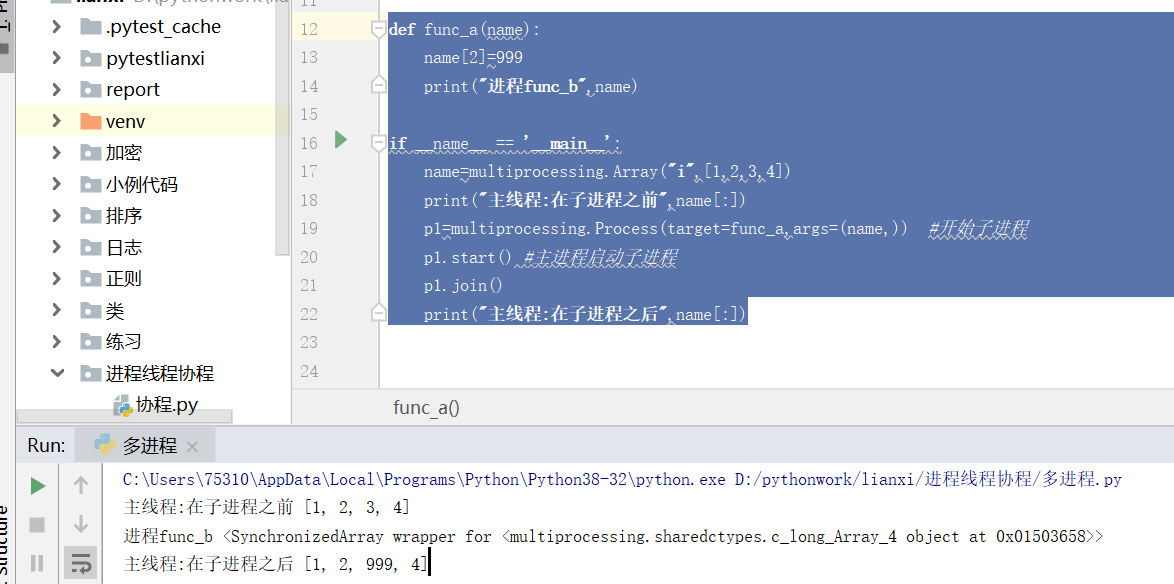
进程数据共享
进程池Pool(5),所谓进程池,就是控制进程的数量
- close() 关闭pool,使其不在接受新的任务。
- terminate() 结束工作进程,不在处理未完成的任务。
- join() 主进程阻塞,等待子进程的退出, join方法要在close或terminate之后使用。
阻塞式和非阻塞式
-- 阻塞式 apply apply(func[, args[, kwds]])是阻塞的
-- 阻塞进程 p = Pool(5) 进程池一共起5个进程,一个进程一个进程做任务。阻塞进程是进程1的任务1完成了,再做进程2的任务
-- 非阻塞进程 p = Pool(5) 进程池一共起5个进程,5个进程共同做任务。进程1任务完成,会再进一个新任务。
def func(n): print(n) time.sleep(2) print('end') return "done"+n if __name__ == '__main__': #阻塞进程 p = Pool(5) for i in range(4): msg = "阻塞进程hello %d" %(i) p.apply(func,(msg,)) p.close() #添加任务结束 p.join() #阻塞主进程,继续子进程任务。如果不阻塞的话,主进程结束,子进程就结束
运行结果
阻塞进程hello 0
end
阻塞进程hello 1
end
阻塞进程hello 2
end
阻塞进程hello 3
end
-- 非阻塞式 apply_async apply_async(func[, args[, kwds[, callback]]]) 它是非阻塞
def func(n): print(n) time.sleep(2) print('end') return "done"+n if __name__ == '__main__': #非阻塞进程 p = Pool(5) result = [] for i in range(4): msg = "非阻塞进程hello %d" %(i) result.append(p.apply_async(func,(msg,)))
p.close()
p.join()
for res in result:
print("::::",res.get())
非阻塞进程hello 0
非阻塞进程hello 1
非阻塞进程hello 2
非阻塞进程hello 3
end
end
end
end
:::: done非阻塞进程hello 0
:::: done非阻塞进程hello 1
:::: done非阻塞进程hello 2
:::: done非阻塞进程hello 3
阻塞进程的回调函数,回调函数在爬虫中最常用。
回调函数的场景:进程池中任何一个任务一旦处理完了,就立即告知主进程:我好了额,你可以处理我的结果了。主进程则调用一个函数去处理该结果,该函数即回调函数
我们可以把耗时间(阻塞)的任务放到进程池中,然后指定回调函数(主进程负责执行),这样主进程在执行回调函数时就省去了I/O的过程,直接拿到的是任务的结果。
from multiprocessing import Pool
import time,random,os
def func_a(task_name):
print("开始做任务",task_name)
start_time = time.time()
time.sleep(random.uniform(1,3))
end_time = time.time()
print(end_time-start_time)
m="任务名称",task_name,"任务用时",(end_time-start_time),"进程id",os.getpid()
print(m)
return m
#回调函数
container=[]
def callback_fun(m):
container.append(m)
if __name__ == '__main__':
pool=Pool(4)
task_names=["吃饭","睡觉","挣钱","哄孩子","看电视","听音乐","写代码"]
for task_name in task_names:
pool.apply_async(func_a,args=(task_name,),callback=callback_fun)
pool.close()
pool.join()
for i in container:
print(i)
进程通信
from multiprocessing import Process,Queue
#不加join,边写边读。加join,写完再读
def write_pro(q):
print("开始写入线程…………")
for i in range(1,20):
#判断队列是否满,加while是不断放
while not q.full():
q.put(i,timeout=2)
time.sleep(0.1)
print("队列的长度write:", q.qsize())
def read_pro(q):
print("开始读取线程…………")
# 判断队列是否为空,加while是不断取
while not q.empty():
# 获取没有timeout参数 block=False 与timeout一样
try:
time.sleep(0.1)
print("从队列取出的值",q.get(timeout=5))
print("队列的长度read:", q.qsize())
except:
print("全部保存完毕")
if __name__ == '__main__':
#定义进程的长度,队列只能放长度为4
q = Queue(3)
p1 = Process(target=write_pro,args=(q,))
p2 = Process(target=read_pro, args=(q,))
p1.start()
# p1.join() #插队,优先写入
p2.start()
# p2.join() #插队,优先写入
队列
#定义队列的长度
q = Queue(3)
print("定义队列的长度",q.qsize())
#放入数据
q.put("a")
print("放入数据之后队列的长度", q.qsize())
#取出数据
q.get()
print("取出数据队列的长度", q.qsize())
#如果队列为空,返回True, 反之False
print(q.empty())
#如果队列满了,返回True, 反之False
print(q.full())
进程同步和异步
join是等待进程结束,那么我像下面这样写,进程不就又变成串行的了吗
不是,p.join()是让谁等。
进程守护:主进程创建子进程,然后将该进程设置成守护自己的进程,守护进程就好比崇祯皇帝身边的老太监,崇祯皇帝已死老太监就跟着殉葬了;
关于守护进程需要强调两点:
其一:守护进程会在主进程代码执行结束后就终止
其二:守护进程内无法再开启子进程,否则抛出异常:AssertionError: daemonic processes are not allowed to have children
如果我们有两个任务需要并发执行,那么开一个主进程和一个子进程分别去执行就ok了,如果子进程的任务在主进程任务结束后就没有存在的必要了,那么该子进程应该在开启前就被设置 成守护进程。主进程代码运行结束,守护进程随即终止;
from multiprocessing import Process
import time
import random
def task(name):
print('%s is piaoing' %name)
time.sleep(random.randrange(1,3))
print('%s is piao end' %name)
if __name__ == '__main__':
p=Process(target=task,args=('egon',))
p.daemon=True #一定要在p.start()前设置,设置p为守护进程,禁止p创建子进程,并且父进程代码执行结束,p即终止运行
p.start()
print('主') #只要终端打印出这一行内容,那么守护进程p也就跟着结束掉了

