Mahout实战---编写自己的相似度计算方法
Mahout本身提供了很多的相似度计算方法,如PCC,COS等。但是当需要验证自己想出来的相似度计算公式是否是好的,这时候需要自己实现相似度类。研究了Mahout-core-0.9.jar的源码后,自己实现了一篇论文上面的相似度公式。:
论文题目:An effective collaborative filtering algorithm based on user preference clustering
具体公式如下:
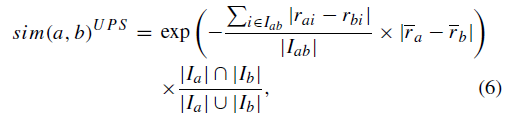
实现过程:具体实现参考了LogLikeHoodSimilarity类的实现
1,实现org.apache.mahout.cf.taste.similarity.UserSimilarity接口
该接口有三个方法:
public interface UserSimilarity extends Refreshable { double userSimilarity(long userID1, long userID2) throws TasteException; void setPreferenceInferrer(PreferenceInferrer inferrer); void refresh(Collection<Refreshable> alreadyRefreshed);//是Refreshable的方法 }
2,void refresh(Collection<Refreshable> alreadyRefreshed);
该方法用于刷新组件(Mahout对于数据改变的时候做出的应对方法。《Mahout实战》中3.2.3节可刷新组件中提到);具体实现如下:
public void refresh(Collection<Refreshable> alreadyRefreshed) { // TODO Auto-generated method stub alreadyRefreshed = RefreshHelper.buildRefreshed(alreadyRefreshed); RefreshHelper.maybeRefresh(alreadyRefreshed, getDataModel()); }
3,void setPreferenceInferrer(PreferenceInferrer inferrer);
这个方法我没有实现,它的作用:可以通过PreferenceInferrer 得到对未打分项的预测评分。
4,double userSimilarity(long userID1, long userID2) throws TasteException;
该方法需要根据公式实现:计算user1和user2的相似度。
在这之前需要传递一个DataModel进来(定义成类的成员变量,由构造函数传递进来)。
具体实现如下:
/** * 实现该方法即实现了相似度计算方法 */ public double userSimilarity(long userID1, long userID2) throws TasteException { // TODO Auto-generated method stub DataModel dataModel = getDataModel(); //获取用户打分项的id集合 FastIDSet prefs1 = dataModel.getItemIDsFromUser(userID1); FastIDSet prefs2 = dataModel.getItemIDsFromUser(userID2); long prefs1Size = prefs1.size(); long prefs2Size = prefs2.size(); /* * long intersectionSize = prefs1Size < prefs2Size ? * prefs2.intersectionSize(prefs1) : prefs1.intersectionSize(prefs2); */ // 计算交集的大小和产生新的FastIDSet作为交集 FastIDSet pre_a, pre_b;// a为大的集合 FastIDSet pre_com = new FastIDSet(); if (prefs1Size < prefs2Size) { pre_a = prefs2; pre_b = prefs1; } else { pre_a = prefs1; pre_b = prefs2; } int intersectionSize = 0; Iterator<Long> iterator = pre_b.iterator(); while (iterator.hasNext()) { long type = (long) iterator.next(); if (pre_a.contains(type)) { pre_com.add(type); } } intersectionSize = pre_com.size(); // 如果交集为0,则相似度为0 if (intersectionSize == 0) { return 0; } // 计算并集的大小 long unionSize = unionSize(pre_a, pre_b); // 计算userID1的平均打分 float avg_1 = avgPreferences(userID1, prefs1); // 计算userID2的平均打分 float avg_2 = avgPreferences(userID2, prefs2); // 计算共同打分项的打分差的和 double sum = 0.0; iterator = pre_com.iterator(); while (iterator.hasNext()) { long itemID = iterator.next(); sum += Math .abs(dataModel.getPreferenceValue(userID1, itemID) - dataModel.getPreferenceValue(userID2, itemID)); } return Math.exp(-((sum * 1.0) / intersectionSize) * Math.abs(avg_1 - avg_2)) * ((intersectionSize * 1.0) / unionSize); } /** * FastIDSet只实现了intersectionSize(求交集), 现实现求并 */ private int unionSize(FastIDSet a, FastIDSet b) { int count = a.size(); Iterator<Long> iterator = b.iterator(); while (iterator.hasNext()) { long type = (long) iterator.next(); if (!a.contains(type)) { count++; } } return count; } /** * 计算用户的打分平均值 * * @throws TasteException */ private float avgPreferences(long userID, FastIDSet set) throws TasteException { float score = (float) 0.0; Iterator<Long> iterator = set.iterator(); while (iterator.hasNext()) { long type = (long) iterator.next(); score += dataModel.getPreferenceValue(userID, type); } return score / set.size(); }
5,测试实现的正确性
根据论文的测试数据对实现的正确性进行测试
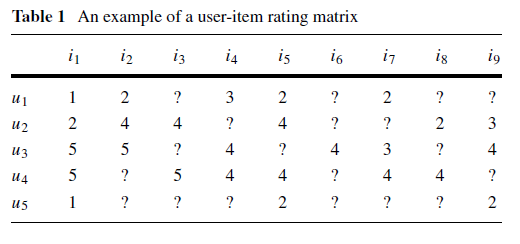
生成ups.csv


1,101,1.0 1,102,2.0 1,104,3.0 1,105,2.0 1,107,2.0 2,101,2.0 2,102,4.0 2,103,4.0 2,105,4.0 2,108,2.0 2,109,3.0 3,101,5.0 3,102,5.0 3,104,4.0 3,106,4.0 3,107,3.0 3,109,4.0 4,101,5.0 4,103,5.0 4,104,4.0 4,105,4.0 4,107,4.0 4,108,4.0 5,101,1.0 5,105,2.0 5,109,2.0
测试程序如下:
public class UPSTest { public static void main(String[] args) throws IOException, TasteException { String projectDir = System.getProperty("user.dir"); DataModel model = new FileDataModel(new File(projectDir + "/src/main/ups.csv")); UserSimilarity similarity = new UPSSimiliarity(model); DecimalFormat df = new DecimalFormat("#,##0.0000");// 保留4位小数 System.out.println(df.format(similarity.userSimilarity(1, 2))); System.out.println(df.format(similarity.userSimilarity(1, 3))); System.out.println(df.format(similarity.userSimilarity(1, 4))); System.out.println(df.format(similarity.userSimilarity(1, 5))); System.out.println(df.format(similarity.userSimilarity(2, 3))); System.out.println(df.format(similarity.userSimilarity(2, 4))); System.out.println(df.format(similarity.userSimilarity(2, 5))); System.out.println(df.format(similarity.userSimilarity(3, 4))); System.out.println(df.format(similarity.userSimilarity(3, 5))); System.out.println(df.format(similarity.userSimilarity(4, 5))); } }
运行结果如下:
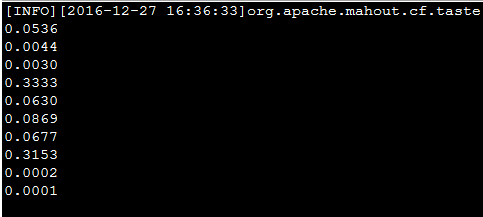
与论文中的结果基本相同:

参考 论文:[1] Zhang, Jia, et al. "An effective collaborative filtering algorithm based on user preference clustering." Applied Intelligence (2016): 1-11.
[2] Mahout实战

 浙公网安备 33010602011771号
浙公网安备 33010602011771号