1. Hive 表关联查询,如何解决数据倾斜的问题
1) 倾斜原因:
map 输出数据按key Hash 的分配到reduce 中,由于key 分布不均匀、业务数据本身的特、建表时考虑不周、等原因造成的reduce 上的数据量差异过大。
(1) key 分布不均匀;
(2) 业务数据本身的特性;
(3) 建表时考虑不周;
(4) 某些SQL 语句本身就有数据倾斜;
如何避免:对于key 为空产生的数据倾斜,可以对其赋予一个随机值。
2) 解决方案
(1) 参数调节:
hive.map.aggr = true
hive.groupby.skewindata=true
有数据倾斜的时候进行负载均衡,当选项设定位true,生成的查询计划会有两个MR Job。第一个MR Job 中,Map 的输出结果集合会随机分布到Reduce 中,
每个Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key 有可能被分发到不同的Reduce 中,从而达到负载均衡的目的;
第二个MR Job 再根据预处理的数据结果按照Group By Key 分布到Reduce 中(这个过程可以保证相同的Group By Key 被分布到同一个Reduce 中), 最后完成最终的聚合操作。
(2) SQL 语句调节:
① 选用join key 分布最均匀的表作为驱动表。做好列裁剪和filter 操作,以达到两表做join 的时候,数据量相对变小的效果。
② 大小表Join:使用map join 让小的维度表(1000 条以下的记录条数)先进内存。在map 端完成reduce.
③ 大表Join 大表:把空值的key 变成一个字符串加上随机数,把倾斜的数据分到不同的reduce 上,由于null 值关联不上,处理后并不影响最终结果。
④ count distinct 大量相同特殊值:count distinct 时,将值为空的情况单独处理,如果是计算count distinct,可以不用处理, 直接过滤,在最后结果中加1。
如果还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union。
2. Hive与传统数据库的区别
Hive和数据库除了拥有类型的查询语言外,无其他相似
存储位置:Hive数据存储在HDFS上。数据库保存在块设备或本地文件系统
数据更新:Hive不建议对数据改写。数据库通常需要经常修改
执行引擎:Hive通过MapReduce来实现。数据库用自己的执行引擎
执行速度:Hive执行延迟高,但它数据规模远超过数据库处理能力时,Hive的并行计算能力就体现优势了。数据库执行延迟较低
数据规模:hive大规模的数据计算。数据库能支持的数据规模较小
扩展性:Hive建立在Hadoop上,随Hadoop的扩展性。数据库由于ACID语义[wh1] 的严格限制,扩展有限
3. Hive内部表和外部表的区别
存储:外部表数据由HDFS管理;内部表数据由hive自身管理
存储:外部表数据存储位置由自己指定(没有指定location则在默认地址下新建);内部表数据存储在hive.metastore.warehouse.dir(默认在/uer/hive/warehouse)
创建:被external修饰的就是外部表;没被修饰是内部表
删除:删除外部表仅仅删除元数据;删除内部表会删除元数据和存储数据
4. Hive中order by,sort by,distribute by和cluster by的区别
order by: 会对输入做全局排序,因此只有一个reducer(多个reducer 无法保证全局有序)。只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
sort by:不是全局排序,其在数据进入reducer 前完成排序。每个mapreduce中进行排序,一般和distribute by使用,且distribute by写在sort by前面。
当mapred.reduce.tasks=1时,效果和order by一样
distribute by:类似MR的Partition,对key进行分区,结合sort by实现分区排序
cluster by:当distribute by和sort by的字段相同时,可以使用cluster by代替,但cluster by只能是升序,不能指定排序规则
5. Hive 有哪些方式保存元数据,各有哪些特点
Hive 支持三种不同的元存储服务器,分别为:内嵌式元存储服务器、本地元存储服务器、远程元存储服务器,每种存储方式使用不同的配置参数。
内嵌式元存储主要用于单元测试,在该模式下每次只有一个进程可以连接到元存储,Derby 是内嵌式元存储的默认数据库。
在本地模式下,每个Hive 客户端都会打开到数据存储的连接并在该连接上请求SQL 查询。
在远程模式下,所有的Hive 客户端都将打开一个到元数据服务器的连接,该服务器依次查询元数据,元数据服务器和客户端之间使用Thrift 协议通信。
6. row_number(),rank()和dense_rank()的区别
都有对数据进行排序的功能
row_number():根据查询结果的顺序计算排序,多用于分页查询
rank():排序相同时序号重复,总序数不变
dense_rank():排序相同时序号重复时,总序数减少
7. Hive如何实现分区
静态分区:
建表:create table demo_tab(id string,name string)
partitioned by(year string,month string) -- 指定分区字段为 year month
row format delimited fields terminated by ',';
插入数据:load data local inpath '/export/data/info.txt' -- 指定加载目录为Linux下;hive目录:load data inpath '/demo/data...'
into table demo_tab partition (year='2022';month='01') --指定分区字段值
动态分区:(分区字段只有demo_tab中data_val和后期可能添加的值,对应分区表demo中的dataVal...,如有多个字段后边拼接)
建普通表:create table demo_tab(id string,name string,data_val string,...) row format delimited fields terminated by ',';
插入数据到普通表:load data path '/hiveDiv/demo/info.txt' into table demo_tab;
创建最终分区表:create table demo(id string,name string)
partitioned by (dataVal string,...)
row format delimited fields terminated by ',';
查询普通表数据插入分区表:insert overwrite table demo partition(dataVal,...)
select id,name,data_val,... from demo_tab;
添加分区:alter table tablename add partition(col2=’202101’);
删除分区:alter table tablename drop partition(col2=’202101’);
8.Hive实现分桶表
设置属性:set hive.enforce.bucketing=ture;
创建临时普通表:create temporary table ls_tab(id string,name string,tid string) -- temporary创建临时表用
row format delimited fields terminated by ',';
给临时表插入数据:load data inpath '/hiveDiv/demo/test.txt' into table ls_tab;
创建分桶表:create table ft_tab(id string,name string,tid string)
clustered by(id) into 3 buckets -- 分桶表的关键字 分桶规则id.hash() % 3
row format delimited fields terminated by '\t';
将临时表数据查询插入分桶表:
insert overwrite table ft_tab select * from ls_tab cluster by(id);
9.Hive分区表和分桶表区别
1). 表现形式上:
分区表是一个文件夹(针对数据的存储路径)
分桶表是文件(针对数据文件,将数据集分解成更容易管理的若干部分)
2). 建表语句上区别:
分区表使用partitioned by 子句指定,以指定字段为伪列,需要指定字段类型
分桶表由clustered by 子句指定,指定字段为真实字段,需要指定桶的个数
3). 从数量上:分区表的分区个数可以增长;分桶表一旦指定,则不能增长
4). 从作用上:
分区避免全表扫描,根据分区列查询指定目录提高查询速度
分桶保存分桶查询结果的分桶结构(数据按照分桶指定的字段进行了hash() 取余)
分桶表数据进行抽样和join时可以提高MR程序效率
5). 在插入数据时:
分区表中插入数据时,静态分区插入数据可使用load data local inpath命令
分桶表中插入数据时只能使用insert overwrite table...若使用load data local inpath这种方式,则分桶不起作用!
10.什么是谓词下推
将过滤条件表达式尽量靠近要过滤的数据源,达到尽早过滤无用数据的目的
11.grouping set、grouping、cube、rollup
grouping sets的执行结果与使用多个分组查询,然后union合并结果集一样;
grouping sets的查询速度吊打union all;
使用grouping sets只会对表进行一次扫描;
在hive和presto中,grouping sets的用法略有差异
hive:
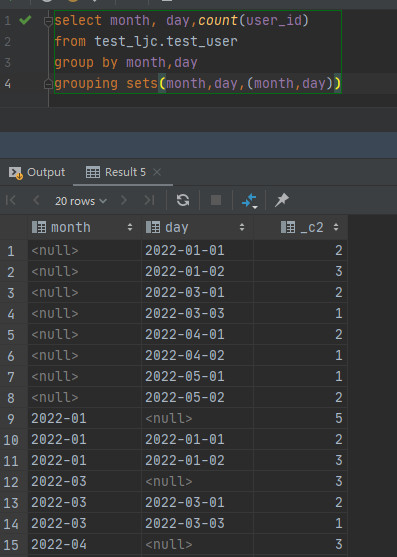
presto: group by后边没有参数
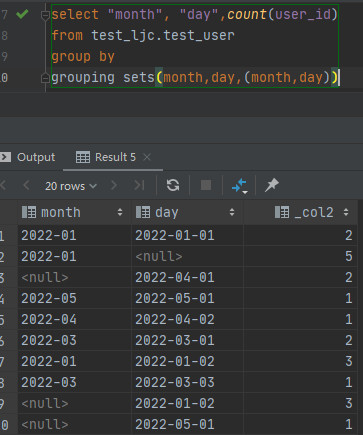
区别:在presto中,group by后边不要添加字段
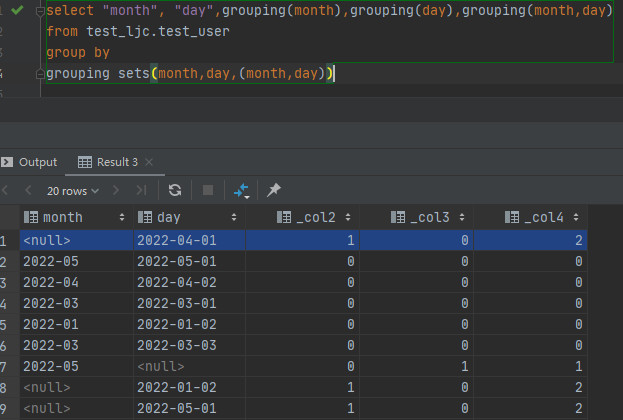
grouping:判断当前数据是按照那个字段来分组的
presto:如果分组中包含相应的列则为0,不包含为1;
其中计算方式如下(二进制计算):
grouping(month) 如果month不为null 则grouping(month)=1 (1*2^0 = 1) 否则为0(0*2^0 = 1)
grouping(month,day) month,day都为null 则grouping(month,dat)=11 (1*2^1 + 1*2^0 = 3)
month为null,day不为null 则grouping(month,day)=10 (1*2^1 + 0*2^0 = 2)
month不为null,day为null 则grouping(month,dat)=01 (0*2^1 + 1*2^0 = 1)
month,day都不为null 则grouping(month,day)=00 (0*2^1 + 0*2^0 = 0)
cube、rollup在hive和presto中通用
cube:实现多个任意维度的查询,也可理解为所有维度组合,n个维度 组合就有2^n个
cube(month,day) 等价于grouping sets((),month,day,(month,day))
select month,day from test group by cube(month,day);
rollup:实现从右到左递减的统计
即:rollup(month,day)等价于grouping sets((month,dat),(month),())
12.Hive和presto的常见区别
1.本质区别:Hive是把查询转化成多个MR任务,然后一个接一个执行,执行结果通过对磁盘的读写来同步
presto是通过一个定制的查询和执行引擎来完成的,他的所有查询处理是在内存中,这也是它性能高的一个主要原因
2.执行速度:presto由于是基于内存的,而hive是在磁盘上读写的,
因此presto比hive快很多,但是多张大表关联查询时,容易引起内存溢出
3.插入数据:
hive: insert into table demo_tab select ... 或者 insert overwrite table demo_tab ...
presto: insert into demo_tab select ...
13.Hive常用设置
--并行执行 如果资源不足,即是可以并行也没有用
set hive.exec.parallel=true; --是否开启并行执行
set hive.exec.parallel.thread.number=16; --最大运行并行多少个阶段
--一旦开启,hive执行引擎在读取数据时,会采用批量化读取 表的存储格式必须为ORC
set hive.vectorized.execution.enabled=true; --矢量化查询(批量化)
--在读取数据的时候,能少读一点尽量少读一点(没用的数据尽量不读) 存储格式为ORC
set hive.exec.orc.zerocopy=true; --读取零拷贝
--数据倾斜的优化:判定是否有倾斜进行开启,如果没有倾斜,此操作会导致执行效率更差
set hive.optimize.skewjoin.compiletime=true; --开启编译期优化
set hive.optimize.skewjoin=true; --开启运行期数据倾斜的处理 默认值为false
set hive skewjoin.key=100000;
set hive.optimize.union.remove=true; --union优化
set hive.groupby.skewindata=true; --开启负载均衡优化
set hive.optimize.correlation=true; --开启关联优化器
--并行编译
set hvie.driver.parallel.compilation=true; --开启并行编译
set hvie.driver.parallel.compilation.global.limit=15; --设置最大同时编辑多少个会话的sql
set hive.merge.mapfiles=true; --小文件合并 map输出合并
set hive.merge.mapredfiles=true; --小文件合并 reduce输出合并
set hive.merge.size,per.task=128M; --设置文件的大小,合并后的文件最大值
--当输出文件的平均大小小于此设置值时,启动一个独立的map-reduce任务进行文件的merge,默认值为16M
set hive.merge.smallfiles.avgsize=16M;
