
//后台代码
@RequestMapping(value="/fileDownMeth",produces = "application/octet-stream;charset=UTF-8")
public ResponseEntity<byte[]> download(HttpServletRequest request,
@RequestParam(required=false) String url,
@RequestParam(required=false) String filename,
Model model)throws Exception {//下载文件路径
String paths=SystemPath.getUploadPath();
url = paths +"/"+ url;
File file = new File(url);
//下载显示的文件名,解决中文名称乱码问题
String downloadFielName = new String(filename.getBytes("UTF-8"),"iso-8859-1");
String agent = request.getHeader("User-Agent").toUpperCase();
boolean isMSIE = ((agent != null && agent.indexOf("MSIE") != -1 ) || ( null != agent && -1 != agent.indexOf("LIKE GECKO")));
HttpHeaders headers = new HttpHeaders();
//application/octet-stream : 二进制流数据(最常见的文件下载)。
headers.setContentType(MediaType.APPLICATION_OCTET_STREAM);
if(isMSIE) {//IE
//解决IE浏览器 下载会出现文件名中文乱码
downloadFielName = new String(filename.getBytes("GBK"), "iso-8859-1");
headers.setContentDispositionFormData("attachment", downloadFielName);
return new ResponseEntity<byte[]>(FileUtils.readFileToByteArray(file),
headers, HttpStatus.OK);
}
headers.setContentDispositionFormData("attachment", downloadFielName);
return new ResponseEntity<byte[]>(FileUtils.readFileToByteArray(file),
headers, HttpStatus.CREATED);
}
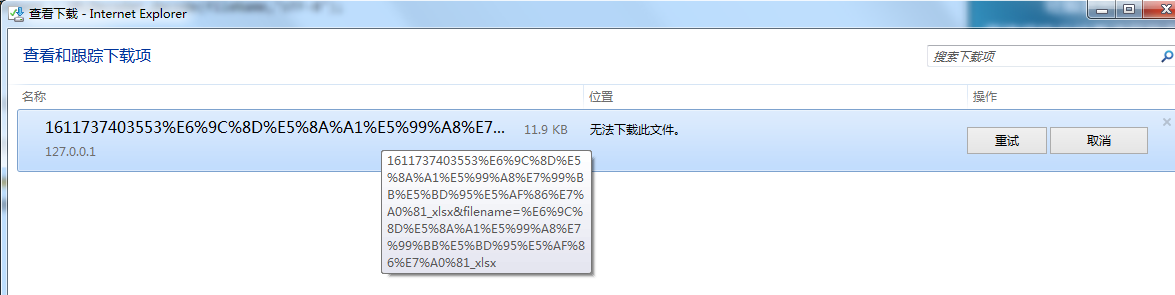
下图是因为IE不支持201状态,所以判断浏览器类型 为IE浏览器走if(isMSIE)中的返回
//前台方法
//下载上传的文件 urls:文件路径;fName:文件名称
var downFiles = function (urls,fName){
var fURI= decodeURI(urls);
fName=decodeURI(fName);
window.location.href=ctx+"/sys/filedownblock/fileDownMeth?url="+encodeURI(encodeURI(fURI))+"&filename="+encodeURI(encodeURI(fName));
}



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律