
Django值聚合,分组,事物,cookie,session
1,聚合(aggregate):是queryset的一个 终止语句,它返回一个包含键值对的字典,键是的名称是聚合值的标识符,值是计算出来的聚合值,键的名称是按照字段和聚合函数自动生成出来的.用到的内置函数是看下代码↓
from django.db.models import Avg, Max, Min, Count, Sum
聚合代码
import os
if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day_67.settings")
import django
django.setup()
from app01.models import Student, Classroom, Teacher,Person
from django.db.models import Max, Min, Sum, Avg, Count
# data = Student.objects.aggregate(Max("id"))
# print(data)
# 1,聚合的单表查询:
# 查找人类女性对象中年龄的平均值?
# data1 = Person.objects.aggregate(Avg("age"), Max("gender"))
# print(data1)
# 因为在性别中只有2个有效数据"1","2",所有查找app01_teacher的时候自app01_teacher动会把数据库中不合法的数据过滤掉
# 1.1,聚合查询的重命名(当有多个重命名按位置参数,关键字参数排列)
# data6 = Person.objects.aggregate(avg=Avg("age"))
# print(data6)
# 2.1,外键的查询
# 查询学生关联表的最大id值
# data2 = Student.objects.aggregate(Max("classroom__id"))
# print(data2)
# 2.2,外键的反向查询
# 查询学生表平均id值(通过班级表的聚合)
# data3 = Classroom.objects.aggregate(Avg("student__id"))
# 3.1,多对多聚合正向查询
# data4 = Teacher.objects.aggregate(Min("students__name"))
# print(data4)
# 3.2,多对多的反向聚合查询
# data5 =
# 查出来的是一个一个数据汇总,返回一个字典
# 1,分组
# 1.1,单表的分组查询
# obj7 = Person.objects.annotate(Min("age")).values()
# for el in obj7:
# print(el) # 默认按id值分组
# 2,外键的分组查询
# 2.1,外键的正向查询
# obj8 = Student.objects.annotate(Max("classroom")).values()
# for el in obj8:
# print(el) # 默认以id分组,故每一个id是一个组
# obj9 = Classroom.objects.annotate(Max("student__id")).values()
# for el in obj9:
# print(el) # 查找班级里边关联学生的最大id值
# 查找学生表中以班级id分组最大的id值
# obj10 = Student.objects.values("classroom__id").annotate(Max("id"))
# for el in obj10:
# print(el)
# 查找第三张表中教师名字出现的次数
# obj11 = Teacher.objects.values("students__teacher__name").annotate(Count("name"))
# for el in obj11:
# print(el)
# 查找每个教师带的学生数
# obj12 = Student.objects.values("teacher__name").annotate(Count("name"))
# for el in obj12:
# print(el)
小结:在聚合查询中不指定分组,就默认指定id值分组,指定分组就要用到value("指定分组字段")
前边指定了分组,此时再查询,就会得到一个字典,在不指定分组的情况下的到的是一个queryset对象,需要value取到里边的详细值
2,F()查询和Q查询
2.1>Django会帮我们提供F()来做跨字段之间的比较,F()实例化的对象可以引用字段,来比较同一个model中不同字段的值
import os
if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day_67.settings")
import django
django.setup()
from app01.models import Person, Classroom, Teacher, Student
from django.db.models import F, Q
# filter帅选出来的是queryset对象列表
# obj = Person.objects.filter(age__gt=18).values()
# print(obj)
# for el in obj:
# print(el)
# F()实例化的对象能够获取到某字段的所有数据,并能动态的作比较
# obj1 = Person.objects.filter(id__gt=F("gender")).values()
# for el in obj1:
# print(el)
# 把帅选到的对象的年两更新到指定的值,不能批量操作
# obj2 = Person.objects.filter(id=3).update(age=30)
# print(obj2)
# 用F()可以批量操作,条件时表中的字段或数据具有相同的操作
# obj3 = Person.objects.all().update(age=F("age")*2)
# 现获取到该表的所有对象,再进行指定更新表中的字段
# Q查询是查询是符合多个条件的查询
# 筛选id值大于2且小于4的对象
# obj4 = Person.objects.filter(id__gt=2,id__lt=4).values()
# for el in obj4:
# print(el)
# obj5 = Person.objects.filter(Q(id__lte=2) | Q(id__gte=5)).values()
# for el in obj5:
# print(el)
# 只有queryset对象列表才会有values()方法
# 查询教师是"eva_j"或者"sylar"ed所有学生
# obj6 = Student.objects.filter(Q(teacher__name="eva_j") | Q(teacher__name="sylar")).values()
# for el in obj6:
# print(el)
# 查询教师是"eva_j"和"sylar"的学生(多表的Q查询跨表查询)
# obj7 = Student.objects.filter(Q(teacher__id__gt=3) & Q(teacher__name="娜扎")).values()
# for el in obj7:
# print(el)
# 查询人类中年级大于18,id值大于5的人(单标的查询)
# obj8 = Person.objects.filter(Q(age__gt=18) & Q(id__lt=5)).values()
# for el in obj8:
# print(el)
小结:F()是F类实例化对象查询,括号里放表的字段,在进行批量改操作,或者某一对象进行操作,F(字段)能动态的获取到该字段列的所有数据,从而进行操作
Q()是Q累实例化对象的查询,适用于多个条件的范围查询有not > & > | 逻辑查询
3,事务:就是在一些实际事物中事情的发展是一系列的,加入由于某些原因,系统突然瘫痪,之前的一些操作就会陷入极大地不安全和不合理的情况,所以需要把之前的操作还原(好比计算机的后退键)引申出事物(也可以举例银行赚钱A转钱给B)
事物的特点:当所有的事情发展的步骤都有效的完成,这件事才算完成,否则重新来.
具体Django代码如下↓
import os
if __name__ == '__main__':
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "day_67.settings")
import django
django.setup()
from app01.models import Person, Classroom, Student, Teacher
try:
from django.db import transaction
with transaction.atomic():
new1_classroom = Classroom.objects.create(name="阿西吧")
new2_classroom = Classroom.objects.create(name="阿尼玛")
new3_classroom = Classroom.objects.create(name="啊哈西")
xue = 10
for i in xue:
print(i)
new4_classroom = Classroom.objects.create(name="阿拉斯加")
except Exception as e:
print(str(e))
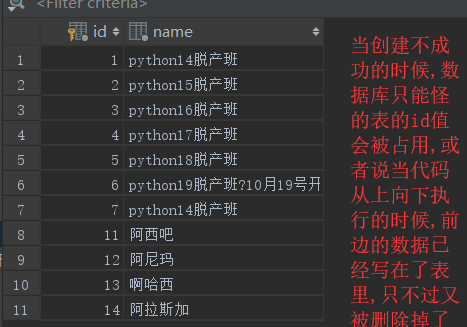
4.cookies:cookies具体是指的一段小信息,它是服务器发送出来存储在浏览器上的一组组键值对,下次访问服务器时会自动袖带这些键值对,以便服务器提取有效信息
4.1>cookies的原理:由服务器产生内容,浏览器收到请求后保存在本地,当浏览器再次访问时,浏览器会自动带上cookie,这样服务器就能通过cookie的内容判断这个是"谁"了.
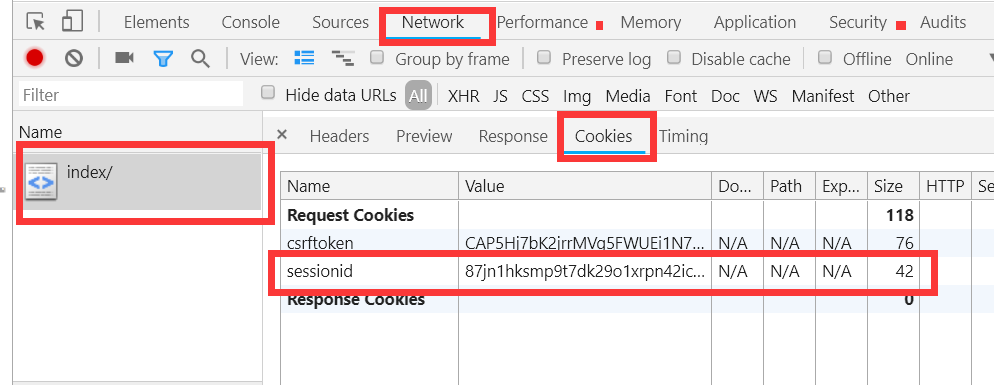
查看cookies,必须先得有cookies(服务器生成了cookies)
4.2>获取cookies的语句
request.COOKIES.get("key")
request.get_signed_cookie(key, default=RAISE_ERROR, salt=" ",max_age = None)
参数说明:
1>default:默认值
2>salt:加盐
3>max_age:后台控制过期时间
4.3>设置cookie
设置Cookie rep = HttpResponse(...) rep = render(request, ...) rep.set_cookie(key,value,...) rep.set_signed_cookie(key,value,salt='加密盐',...)
参数说明:
key, 键 value='', 值 max_age=None, 超时时间 expires=None, 超时时间(IE requires expires, so set it if hasn't been already.) path='/', Cookie生效的路径,/ 表示根路径,特殊的:根路径的cookie可以被任何url的页面访问 domain=None, Cookie生效的域名 secure=False, https传输 httponly=False 只能http协议传输,无法被JavaScript获取(不是绝对,底层抓包可以获取到也可以被覆盖)
4.4>删除cookie
def logout(request):
rep = redirect("/login/")
rep.delete_cookie("user") # 删除用户浏览器上之前设置的usercookie值
return rep
4.5>cookie代码
from django.shortcuts import render, redirect, HttpResponse
# Create your views here.
# 为了在每个函数中都能够增加cookies要用到装饰器
def login_request(fn):
def inner(request, *args, **kwargs):
# 判断在跳转页面的时候cookies设置的值
if not request.COOKIES.get("is_login") == "miss":
# 如果cookies的键值对不成立则要先返回登录页面,登陆成功以后,再返回用户之前要登录的页面
# 先获取到用户开始想要登录的页面路径
path = request.path_info
return redirect("/login/?path={}".format(path))
# 先跳转login页面,再跳转到原来要登录的页面
ret = fn(request, *args, **kwargs)
return ret
return inner
def login(request):
# 用户第二次进来是提交数据,此时是POST请求
if request.method == "POST":
# 获取用户输入的内容
user = request.POST.get("user")
pwd = request.POST.get("pwd")
print(user,pwd,type(pwd))
# 从数据库中提取数据
if user == "雪雪" and pwd == "321":
# 这是判断如果已经登录成功再次登录此时就不会再让他进入登录页面了
# 从request中获取键是path的值
path = request.GET.get("path")
print(path)
# 第一次获取到的是空走下边的if语句
if path:
web_page = redirect(path)
# 当path对应有了值就会直接跳转这个页面
else:
# 把跳转页面保存到一个变量中
web_page = redirect("/home/")
# 在返回页面前设置cookies值
web_page.set_cookie("is_login", "miss", max_age=300)
# 在返回的页面中设置cookies,前两个是字符串组成key,value,后边
# max_age是这一对键值对保存的时间是秒
return web_page
# 用户第一次进来是一个get请求,返回给用户一个html登录页面
return render(request, "login.html")
@login_request # 装饰index函数判断次时用户的状态是登录状态还是为登录状态
def index(request):
return HttpResponse("这是index页面")
@login_request # 装饰home函数,用来在返回这个页面之前判断是否在登录状态
def home(request):
return render(request, "home.html")
def logout(reqyest):
# 删除cookies以后跳转登录的页面
web_page = redirect("/login/")
# 在返回登录页面前把request里边带的cookies删除掉
web_page.delete_cookie("is_login") # 指定要珊瑚粗的cookies的键
return web_page
5,session
cookie虽然在一定程度上解决了"保持状态的需求",但是由于cookie本身最大支持4096字节,以及cookie本身保存在客户端,可能被拦截或窃取,因此就需要一种新的东西,他能支持更多的字节,并且它保存在服务器有较高的安全性,这就是session,HTTP协议是无状态特征,所以服务器就不知道访问者是谁,namecookie就起到桥接的作用
我们可以给每个客户端cookie分配一个唯一的id,这样用户在访问时,通过cookie,服务器就是知道来的人是"谁",我们根据不同cookie的id值,在服务器上保存一端时间的 私密资料
总而言之:cookie弥补了HTTP无状态的不足,让服务器知道来的人是谁,但是cookie以文本的方式保存在本地,它自身安全较差:所以我们就通过cookie识别 不同的用户对应的私密信息就保存超过4096字节(我总结的:把保存在浏览器值的你明文变成暗文,且经过算法字节变长了)
5.1>Django中session的相关方法
# 获取、设置、删除Session中数据
request.session['k1']
request.session.get('k1',None)
request.session['k1'] = 123
request.session.setdefault('k1',123) # 存在则不设置
del request.session['k1']
# 所有 键、值、键值对
request.session.keys()
request.session.values()
request.session.items()
request.session.iterkeys()
request.session.itervalues()
request.session.iteritems()
# 会话session的key
request.session.session_key
# 将所有Session失效日期小于当前日期的数据删除
request.session.clear_expired()
# 检查会话session的key在数据库中是否存在
request.session.exists("session_key")
# 删除当前会话的所有Session数据
request.session.delete()
# 删除当前的会话数据并删除会话的Cookie。
request.session.flush()
这用于确保前面的会话数据不可以再次被用户的浏览器访问
例如,django.contrib.auth.logout() 函数中就会调用它。
# 设置会话Session和Cookie的超时时间
request.session.set_expiry(value)
* 如果value是个整数,session会在些秒数后失效。
* 如果value是个datatime或timedelta,session就会在这个时间后失效。
* 如果value是0,用户关闭浏览器session就会失效。
* 如果value是None,session会依赖全局session失效策略。
5.2>session的相关代码
from django.shortcuts import render, redirect, HttpResponse
# Create your views here.
def login_reuqire(fn):
def inner(request, *args, **kwargs):
if not request.session.get("is_login") == "1":
path = request.path_info
return redirect("/login/?path={}".format(path))
ret = fn(request,*args, **kwargs)
return ret
return inner
def login(request):
# 第二次进来是提交页面,提交用户登录的账号和密码
# 此时是POST请求,判断是第二次进来的请求的方法
if request.method == "POST":
# 获取到用户提交过来的数据
user = request.POST.get("user")
pwd = request.POST.get("pwd")
# 从数据库中读取数据,判断用户输入的是否正确
if user == "雪雪" and pwd == "321":
# 获取其你去网址的地址
path = request.GET.get("path")
# 如果path存在,登录成功后,跳转到要查看的页面
if path:
web_page = redirect(path)
# 如果不存在path,就直接跳转到登录页面
else:
web_page = redirect("/home/")
# 返回一个网站的页面
# 把要返回的主页面保存的一个变量中
# web_page = redirect("/home/")
# 设置session值
request.session["is_login"] = "1"
# request.session.set_expire(0) # session的sheng,ing周期
return web_page
# 第一次登陆是get请求返回给用户一个登录的页面
return render(request, "login.html")
@login_reuqire
def home(request):
return render(request, "home.html")
@login_reuqire
def index(request):
return HttpResponse("这是index页面")
def logout(request):
request.flush()
web_page = redirect("/login/")
return web_page
在打印终端打印sql语句
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
把这段代码复制到settings中即可,重启一下项目

