

mapredce测试
剖析美国平均气温项目,掌握MapReduce编程
MapReduce 是一种可用于数据处理的编程模型。该模型比较简单,但要想写出有用的程序却不太容易。Hadoop 可以运行各种语言版本的 MapReduce 程序, 比如Java、Ruby、Python和C++语言版本。最重要的是,MapReduce 程序本质上是并行运行的,因此可以将大规模的数据分析任务分发给任何一个拥有足够多机器的数据中心。 MapReduce 的优势在于处理大规模数据集,所以这里我们先来看一个数据集。
气象数据集
在本课程中,我们要写一个挖掘气象数据的程序。气象数据是通过分布在美国全国各地区的很多气象传感器每隔一小时进行收集,这些数据是半结构化数据且是按照记录方式存储的,因此非常适合使用 MapReduce 程序来统计分析。
数据格式
我们使用的数据来自美国国家气候数据中心、美国国家海洋和大气管理局(简称 NCDC NOAA),这些数据按行并以 ASCII 格式存储,其中每一行是一条记录。 下面我们展示一行采样数据,其中重要的字段被突出显示。该行数据被分割成很多行以突出每个字段,但在实际文件中,这些字段被整合成一行且没有任何分隔符。

1998 #year 03 #month 09 #day 17 #hour 11 #temperature -100 #dew 10237 #pressure 60 #wind_direction 72 #wind_speed 0 #sky_condition 0 #rain_1h -9999 #rain_6h
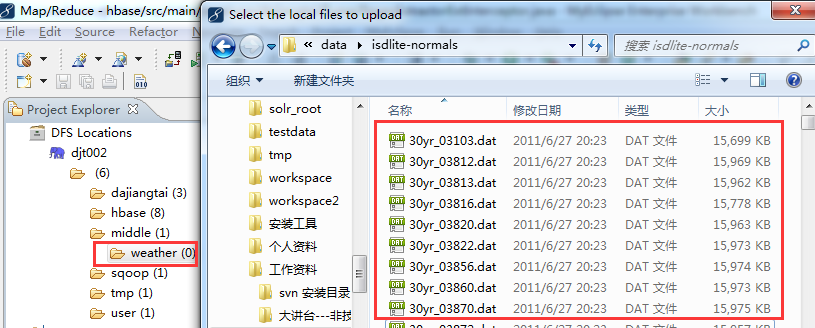
数据文件按照气象站和日期进行组织,每个气象站都是一个总目录,而且每个气象站下面从 1980 年到 2010 年,每一年又都作为一个子目录。 因为美国有成千上万个气象站,所以整个数据集由大量的小文件组成。通常情况下,处理少量的大型文件更容易、更有效,因此,这些数据需要经过预处理(小文件合并),将每个气象站的数据文件拼接成一个单独的文件。 预处理过的数据文件示例如下所示:
30yr_03103.dat 30yr_03812.dat 30yr_03813.dat 30yr_03816.dat 30yr_03820.dat 30yr_03822.dat 30yr_03856.dat 30yr_03860.dat 30yr_03870.dat 30yr_03872.dat
请点击下载数据集。
数据集导入HDFS
一旦数据下载并解压到本地目录之后,我们通过已经安装好hadoop-eclipse-plugin-xxx.jar插件,很容易将气象站数据导入HDFS。首先通过插件连接 HDFS(连接地址:hdfs://djt002:9000):
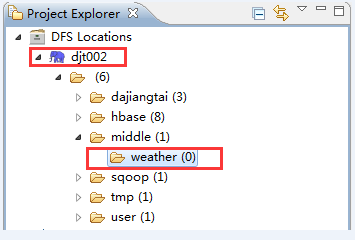
规划好气象站数据集在HDFS中的目录结构(hdfs://djt002:9000/middle/weather),然后右键点击weather目录选择Upload files to DFS,最后选中需要上传的气象站数据集。
当所有数据集上传至HDFS,我们就可以使用MapReduce jobs来统计分析气象站数据集。
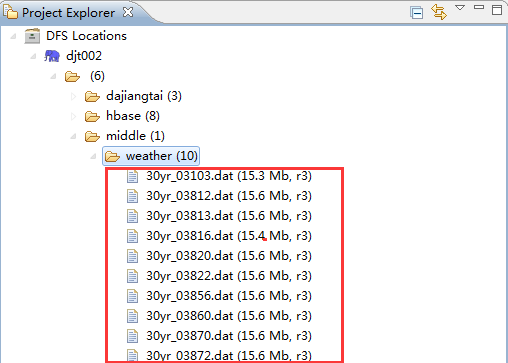
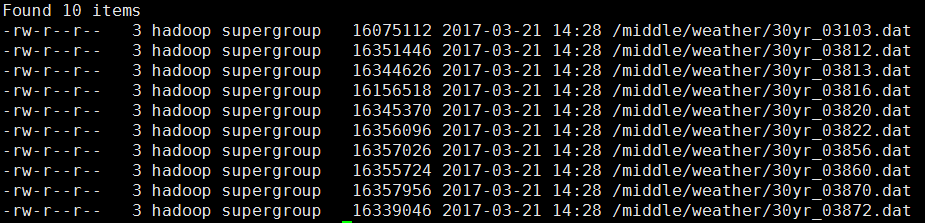
我们也可以通过命令行访问刚刚上传至HDFS的数据集。
[hadoop@djt002 hadoop]$ bin/hdfs dfs -ls /middle/weather/
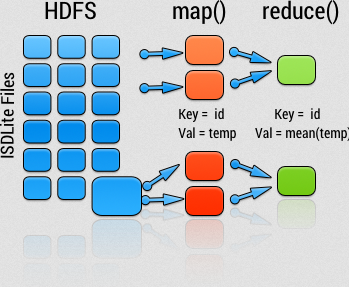
使用 Hadoop 来分析数据
为了充分利用 Hadoop 提供的并行处理优势,我们需要将查询表示成 MapReduce 作业。完成本地小规模测试之后,就可以把作业部署到集群上面运行。 那么 MapReduce 作业到底由哪几个部分组成的呢?接下来我们详细介绍。
map 和 reduce
MapReduce 任务过程分为两个处理阶段:map 阶段和reduce阶段 。每个阶段都以键值对作为输入和输出,其类型由程序员自己来选择。程序员还需要写两个函数:map 函数和 reduce 函数。
在这里,map 阶段的输入是 NCDC NOAA 原始数据。我们选择文本格式作为输入格式,将数据集的每一行作为文本输入。键是某一行起始位置相对于文件起始位置的偏移量,不过我们不需要这个信息,所以将其忽略。
我们的 map 函数很简单。由于我们只对气象站和气温感兴趣,所以只需要取出这两个字段数据。在本课程中,map 函数只是一个数据准备阶段, 通过这种方式来准备数据,使 reducer 函数能够继续对它进行处理:即统计出每个气象站 30 年来的平均气温。map 函数还是一个比较合适去除已损记录的地方,在 map 函数里面,我们可以筛掉缺失的或者错误的气温数据。
为了全面了解 map 的工作方式,我们考虑以下输入数据的示例数据。
1985 07 31 02 200 94 10137 220 26 1 0 -9999 1985 07 31 03 172 94 10142 240 0 0 0 -9999 1985 07 31 04 156 83 10148 260 10 0 0 -9999 1985 07 31 05 133 78 -9999 250 0 -9999 0 -9999 1985 07 31 06 122 72 -9999 90 0 -9999 0 0 1985 07 31 07 117 67 -9999 60 0 -9999 0 -9999 1985 07 31 08 111 61 -9999 90 0 -9999 0 -9999 1985 07 31 09 111 61 -9999 60 5 -9999 0 -9999 1985 07 31 10 106 67 -9999 80 0 -9999 0 -9999 1985 07 31 11 100 56 -9999 50 5 -9999 0 -9999
这些行以键/值对的方式作为 map 函数的输入:
(0,1985 07 31 02 200 94 10137 220 26 1 0 -9999) (62,1985 07 31 03 172 94 10142 240 0 0 0 -9999) (124,1985 07 31 04 156 83 10148 260 10 0 0 -9999) (186,1985 07 31 05 133 78 -9999 250 0 -9999 0 -9999) (248,1985 07 31 06 122 72 -9999 90 0 -9999 0 0) (310,1985 07 31 07 117 67 -9999 60 0 -9999 0 -9999) (371,1985 07 31 08 111 61 -9999 90 0 -9999 0 -9999) (434,1985 07 31 09 111 61 -9999 60 5 -9999 0 -9999) (497,1985 07 31 10 106 67 -9999 80 0 -9999 0 -9999) (560,1985 07 31 11 100 56 -9999 50 5 -9999 0 -9999)
键(key)是文件中的偏移量,map 函数并不需要这个信息,所以将其忽略。map 函数的功能仅限于提取气象站和气温信息,并将它们作为输出。
map 函数的输出经由 MapReduce 框架处理后,最后发送到 reduce 函数。这个处理过程基于键来对键值对进行排序和分组。因此在这个示例中,reduce 函数看到的是如下输入:
(03103,[200,172,156,133,122,117,111,111,106,100])
每个气象站后面紧跟着一系列气温数据,reduce 函数现在要做的是遍历整个列表并统计出平均气温:
03103 132
这是最终输出结果即每一个气象站历年的平均气温。
下图代表了 MapReduce 高层设计。
Java MapReduce
我们明白 MapReduce 程序的工作原理之后,下一步就是写代码实现它。我们需要编写三块代码内容:一个 map 函数、一个 reduce 函数和一些用来运行作业的代码。
map 函数由 Mapper 类实现来表示,Mapper 声明一个 map() 虚方法,其内容由我们自己来实现。
下面我们来编写 Mapper 类,实现 map() 方法,提取气象站和气温数据。
这个 Mapper 类是一个泛型类型,它有四个形参类型,分别指定 map 函数的输入键、输入值、输出键和输出值的类型。 就本示例来说,输入键是一个长整数偏移量,输入值是一行文本,输出键是气象站id,输出值是气温(整数)。Hadoop 本身提供了一套可优化网络序列化传输的基本类型,而不是使用 java 内嵌的类型。这些类型都在 org.apache.hadoop.io 包中。 这里使用 LongWritable 类型(相当于 Java 的 Long 类型)、Text 类型(相当于 Java 中的 String 类型)和 IntWritable 类型(相当于 Java 的 Integer 类型)。
map() 方法的输入是一个键(key)和一个值(value),我们首先将 Text 类型的 value 转换成 Java 的 String 类型, 之后使用 substring()方法截取我们业务需要的值。map() 方法还提供了 Context 实例用于输出内容的写入。 在这种情况下,我们将气象站id按 Text 对象进行读/写(因为我们把气象站id当作键),将气温值封装在 IntWritale 类型中。只有气温数据不缺失,这些数据才会被写入输出记录中。
我们以上面类似的方法用 Reducer 来定义 reduce 函数,统计每个气象站的平均气温。
同样,reduce 函数也有四个形式参数类型用于指定输入和输出类型。reduce 函数的输入类型必须匹配 map 函数的输出类型:即 Text 类型和 IntWritable 类型。
在这种情况下,reduce 函数的输出类型也必须是 Text 和 IntWritable 类型,分别是气象站id和平均气温。在 map 的输出结果中,所有相同的气象站(key)被分配到同一个reduce执行,这个平均气温就是针对同一个气象站(key),通过循环所有气温值(values)求和并求平均数所得到的。
第三部分代码负责运行 MapReduce 作业。
Configuration 类读取 Hadoop 的配置文件,如 site-core.xml、mapred-site.xml、hdfs-site.xml 等。
Job 对象指定作业执行规范,我们可以用它来控制整个作业的运行。我们在 Hadoop 集群上运行这个作业时,要把代码打包成一个 JAR 文件(Hadoop 在集群上发布这个文件)。 不必明确指定 JAR 文件的名称,在 Job 对象的 setJarByClass 方法中传递一个类即可,Hadoop 利用这个类来查找包含它的 JAR 文件,进而找到相关的 JAR 文件。
构造 Job 对象之后,需要指定输入和输出数据的路径。调用 FileInputFormat 类的静态方法 addInputPath() 来定义输入数据的路径,这个路径可以是单个的文件、一个目录(此时,将目录下所有文件当作输入)或符合特定文件模式的一系列文件。由函数名可知,可以多次调用 addInputPath() 来实现多路径的输入。 调用 FileOutputFormat 类中的静态方法 setOutputPath() 来指定输出路径(只能有一个输出路径)。这个方法指定的是 reduce 函数输出文件的写入目录。 在运行作业前该目录是不应该存在的,否则 Hadoop 会报错并拒绝运行作业。这种预防措施的目的是防止数据丢失(长时间运行的作业如果结果被意外覆盖,肯定是件可怕的事情)。
接着,通过 setMapperClass() 和 setReducerClass() 指定 map 类型和reduce 类型。
setOutputKeyClass() 和 setOutputValueClass() 控制 map 和 reduce 函数的输出类型,正如本例所示,这两个输出类型一般都是相同的。如果不同,则通过 setMapOutputKeyClass()和setMapOutputValueClass()来设置 map 函数的输出类型。
输入的类型通过 InputFormat 类来控制,我们的例子中没有设置,因为使用的是默认的 TextInputFormat(文本输入格式)。
在设置定义 map 和 reduce 函数的类之后,可以开始运行作业。Job 中的 waitForCompletion() 方法提交作业并等待执行完成。该方法中的布尔参数是个详细标识,所以作业会把进度写到控制台。 waitForCompletion() 方法返回一个布尔值,表示执行的成(true)败(false),这个布尔值被转换成程序的退出代码 0 或者 1。
源代码如下:
1 /** 2 * 3 */ 4 package com.dajiangtai.hadoop; 5 6 import java.io.IOException; 7 8 import org.apache.hadoop.conf.Configuration; 9 import org.apache.hadoop.fs.FileSystem; 10 import org.apache.hadoop.fs.Path; 11 import org.apache.hadoop.io.IntWritable; 12 import org.apache.hadoop.io.LongWritable; 13 import org.apache.hadoop.io.Text; 14 import org.apache.hadoop.mapreduce.Job; 15 import org.apache.hadoop.mapreduce.Mapper; 16 import org.apache.hadoop.mapreduce.Reducer; 17 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 18 import org.apache.hadoop.mapreduce.lib.input.FileSplit; 19 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 20 21 import com.dajiangtai.hadoop.WordCountTest.Map; 22 import com.dajiangtai.hadoop.WordCountTest.Reduce; 23 import com.sun.tools.jdi.EventSetImpl.Itr; 24 25 /** 26 * @author yizhijing 27 * 28 */ 29 public class Temperature { 30 31 public static class Map extends Mapper<LongWritable, Text,Text ,IntWritable>{ 32 public void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{ 33 String line = value.toString(); 34 //string.trim()此字符串移除了前导和尾部空白的副本;如果没有前导和尾部空白,则返回此字符串 35 ////substring(int beginIndex, int endIndex)---eg:"hamburger".substring(4, 8) returns "urge" 36 //Integer.parseInt(string a)将字符串参数作为有符号的十进制整数进行解析 37 int temperature = Integer.parseInt(line.substring(14,19).trim()); 38 //过滤无效数据 39 if(temperature != -9999){ 40 //获取当前split的文件名 41 FileSplit fileSplit = (FileSplit) context.getInputSplit(); 42 String weatherStationId = fileSplit.getPath().getName().substring(5, 10);//通过文件名称提取气象站id 43 context.write(new Text(weatherStationId), new IntWritable(temperature)); 44 } 45 } 46 } 47 48 public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable>{ 49 50 /**Iterable<IntWritable> values;------------ 51 *声明了values是一个聚集元素集:set of elements of type T,可以不太准确的将其理解为一数组。 52 *使用迭代器之后对IntWritable类型的数组或集合values进行遍历,用jdk1.5的for each,写法如下: 53 *for(IntWritable val : values) {System.out.println(val);} 54 *Iterable达到了解耦效果的意思是:使用传统的for循环时,访问代码和集合本身是紧耦合,无法将访问逻辑 55 *从集合类和客户端代码中分离出来,每一种集合对应一种遍历方法,客户端代码无法复用。 56 */ 57 private IntWritable result = new IntWritable(); 58 public void reduce(Text key,Iterable<IntWritable> value,Context context) throws IOException, InterruptedException{ 59 int sum = 0; 60 int count = 0; 61 for(IntWritable val : value){ 62 sum += val.get(); 63 count++; 64 } 65 result.set(sum/count); 66 context.write(key, result); 67 } 68 69 } 70 71 public static void main(String[] args) throws IllegalArgumentException, IOException, InterruptedException, ClassNotFoundException { 72 Configuration conf = new Configuration(); 73 74 // conf.addResource("") 75 76 Path myPath = new Path("hdfs://slave1:9000/weather/weather-out");//输出路径 77 FileSystem hdfs = myPath.getFileSystem(conf);//获取文件系统 78 if(hdfs.isDirectory(myPath)){ 79 hdfs.delete(myPath, true); 80 } 81 82 Job job = Job.getInstance(); 83 job.setJarByClass(WordCountTest.class); 84 85 job.setMapperClass(Map.class); 86 job.setReducerClass(Reduce.class); 87 88 job.setOutputKeyClass(Text.class); 89 job.setOutputValueClass(IntWritable.class); 90 91 //注意导入正确的包 92 //导入有多个 文件的路径时 93 FileInputFormat.addInputPath(job , new Path("hdfs://slave1:9000/weather/")); 94 FileOutputFormat.setOutputPath(job, new Path("hdfs://slave1:9000/weather/weather-out")); 95 96 System.exit(job.waitForCompletion(true) ? 0 : 1); 97 98 } 99 }
运行测试
编写好 MapReduce 作业之后,通常要拿一个小型数据集进行测试以排除代码问题。程序测试成功之后,我们通过 eclipse 工具将 MapReduce作业打成jar包即temperature.jar,然后然后上传至/home/hadoop/djt/ 目录下,由 hadoop 脚本来执行。
[hadoop@djt002 hadoop-2.2.0-x64]$ export HADOOP_CLASSPATH=/home/hadoop/djt/temperature.jar [hadoop@djt002 hadoop-2.2.0-x64]$ hadoop com.dajiangtai.hadoop.advance.Temperature
MapReduce 作业的运行日志如下所示。
2018-03-22 21:33:29,528 INFO [org.apache.hadoop.conf.Configuration.deprecation] - session.id is deprecated. Instead, use dfs.metrics.session-id
2018-03-22 21:33:29,534 INFO [org.apache.hadoop.metrics.jvm.JvmMetrics] - Initializing JVM Metrics with processName=JobTracker, sessionId=
2018-03-22 21:33:31,061 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2018-03-22 21:33:31,065 WARN [org.apache.hadoop.mapreduce.JobSubmitter] - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2018-03-22 21:33:31,288 INFO [org.apache.hadoop.mapreduce.lib.input.FileInputFormat] - Total input paths to process : 10
2018-03-22 21:33:31,410 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - number of splits:10
2018-03-22 21:33:31,767 INFO [org.apache.hadoop.mapreduce.JobSubmitter] - Submitting tokens for job: job_local1415234794_0001
2018-03-22 21:33:32,399 INFO [org.apache.hadoop.mapreduce.Job] - The url to track the job: http://localhost:8080/
2018-03-22 21:33:32,401 INFO [org.apache.hadoop.mapreduce.Job] - Running job: job_local1415234794_0001
2018-03-22 21:33:32,415 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter set in config null
2018-03-22 21:33:32,439 INFO [org.apache.hadoop.mapred.LocalJobRunner] - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2018-03-22 21:33:32,757 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for map tasks
2018-03-22 21:33:32,759 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1415234794_0001_m_000000_0
2018-03-22 21:33:32,830 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2018-03-22 21:33:33,019 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@6295f290
2018-03-22 21:33:33,027 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: hdfs://slave1:9000/weather/30yr_03870.dat:0+16357956
2018-03-22 21:33:33,267 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2018-03-22 21:33:33,268 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2018-03-22 21:33:33,268 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2018-03-22 21:33:33,268 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2018-03-22 21:33:33,268 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2018-03-22 21:33:33,275 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2018-03-22 21:33:33,412 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local1415234794_0001 running in uber mode : false
2018-03-22 21:33:33,418 INFO [org.apache.hadoop.mapreduce.Job] - map 0% reduce 0%
2018-03-22 21:33:35,067 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2018-03-22 21:33:35,073 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2018-03-22 21:33:35,074 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2018-03-22 21:33:35,074 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 2637230; bufvoid = 104857600
2018-03-22 21:33:35,074 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 25159508(100638032); length = 1054889/6553600
2018-03-22 21:33:36,033 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2018-03-22 21:33:36,071 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1415234794_0001_m_000000_0 is done. And is in the process of committing
2018-03-22 21:33:36,108 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2018-03-22 21:33:36,109 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1415234794_0001_m_000000_0' done.
2018-03-22 21:33:36,109 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1415234794_0001_m_000000_0
2018-03-22 21:33:36,109 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1415234794_0001_m_000001_0
2018-03-22 21:33:36,115 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2018-03-22 21:33:36,357 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@323f265b
2018-03-22 21:33:36,363 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: hdfs://slave1:9000/weather/30yr_03856.dat:0+16357026
2018-03-22 21:33:36,429 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 0%
2018-03-22 21:33:36,610 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2018-03-22 21:33:36,610 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2018-03-22 21:33:36,610 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2018-03-22 21:33:36,611 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2018-03-22 21:33:36,611 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2018-03-22 21:33:36,617 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2018-03-22 21:33:38,776 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2018-03-22 21:33:38,776 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2018-03-22 21:33:38,776 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2018-03-22 21:33:38,777 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 2637780; bufvoid = 104857600
2018-03-22 21:33:38,777 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 25159288(100637152); length = 1055109/6553600
2018-03-22 21:33:39,352 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2018-03-22 21:33:39,380 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1415234794_0001_m_000001_0 is done. And is in the process of committing
2018-03-22 21:33:39,392 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2018-03-22 21:33:39,393 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1415234794_0001_m_000001_0' done.
2018-03-22 21:33:39,393 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1415234794_0001_m_000001_0
2018-03-22 21:33:39,393 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1415234794_0001_m_000002_0
2018-03-22 21:33:39,399 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2018-03-22 21:33:39,635 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@438346a3
2018-03-22 21:33:39,641 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: hdfs://slave1:9000/weather/30yr_03822.dat:0+16356096
2018-03-22 21:33:39,681 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2018-03-22 21:33:39,682 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2018-03-22 21:33:39,682 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2018-03-22 21:33:39,682 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2018-03-22 21:33:39,682 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2018-03-22 21:33:39,685 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2018-03-22 21:33:41,943 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2018-03-22 21:33:41,944 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2018-03-22 21:33:41,944 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2018-03-22 21:33:41,944 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 2637650; bufvoid = 104857600
2018-03-22 21:33:41,944 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 25159340(100637360); length = 1055057/6553600
2018-03-22 21:33:42,400 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2018-03-22 21:33:42,436 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1415234794_0001_m_000002_0 is done. And is in the process of committing
2018-03-22 21:33:42,447 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2018-03-22 21:33:42,447 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1415234794_0001_m_000002_0' done.
2018-03-22 21:33:42,447 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1415234794_0001_m_000002_0
2018-03-22 21:33:42,447 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1415234794_0001_m_000003_0
2018-03-22 21:33:42,452 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2018-03-22 21:33:42,697 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@141ed7ac
2018-03-22 21:33:42,703 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: hdfs://slave1:9000/weather/30yr_03860.dat:0+16355724
2018-03-22 21:33:42,740 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2018-03-22 21:33:42,741 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2018-03-22 21:33:42,742 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2018-03-22 21:33:42,742 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2018-03-22 21:33:42,742 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2018-03-22 21:33:42,745 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2018-03-22 21:33:44,558 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2018-03-22 21:33:44,559 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2018-03-22 21:33:44,559 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2018-03-22 21:33:44,559 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 2630440; bufvoid = 104857600
2018-03-22 21:33:44,559 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 25162224(100648896); length = 1052173/6553600
2018-03-22 21:33:44,692 INFO [org.apache.hadoop.mapreduce.Job] - map 30% reduce 0%
2018-03-22 21:33:44,876 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2018-03-22 21:33:44,896 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1415234794_0001_m_000003_0 is done. And is in the process of committing
2018-03-22 21:33:44,903 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2018-03-22 21:33:44,903 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1415234794_0001_m_000003_0' done.
2018-03-22 21:33:44,903 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1415234794_0001_m_000003_0
2018-03-22 21:33:44,903 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1415234794_0001_m_000004_0
2018-03-22 21:33:44,908 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2018-03-22 21:33:45,118 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@57398cac
2018-03-22 21:33:45,125 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: hdfs://slave1:9000/weather/30yr_03812.dat:0+16351446
2018-03-22 21:33:45,162 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2018-03-22 21:33:45,162 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2018-03-22 21:33:45,163 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2018-03-22 21:33:45,163 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2018-03-22 21:33:45,163 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2018-03-22 21:33:45,167 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2018-03-22 21:33:45,693 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 0%
2018-03-22 21:33:47,840 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2018-03-22 21:33:47,841 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2018-03-22 21:33:47,841 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2018-03-22 21:33:47,841 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 2636340; bufvoid = 104857600
2018-03-22 21:33:47,841 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 25159864(100639456); length = 1054533/6553600
2018-03-22 21:33:48,432 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2018-03-22 21:33:48,463 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1415234794_0001_m_000004_0 is done. And is in the process of committing
2018-03-22 21:33:48,475 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2018-03-22 21:33:48,476 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1415234794_0001_m_000004_0' done.
2018-03-22 21:33:48,476 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1415234794_0001_m_000004_0
2018-03-22 21:33:48,476 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1415234794_0001_m_000005_0
2018-03-22 21:33:48,480 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2018-03-22 21:33:48,737 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@469695f
2018-03-22 21:33:48,752 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: hdfs://slave1:9000/weather/30yr_03820.dat:0+16345370
2018-03-22 21:33:48,788 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2018-03-22 21:33:48,788 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2018-03-22 21:33:48,788 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2018-03-22 21:33:48,788 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2018-03-22 21:33:48,789 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2018-03-22 21:33:48,791 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2018-03-22 21:33:52,487 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2018-03-22 21:33:52,487 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2018-03-22 21:33:52,488 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2018-03-22 21:33:52,488 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 2631340; bufvoid = 104857600
2018-03-22 21:33:52,488 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 25161864(100647456); length = 1052533/6553600
2018-03-22 21:33:52,721 INFO [org.apache.hadoop.mapreduce.Job] - map 50% reduce 0%
2018-03-22 21:33:53,028 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2018-03-22 21:33:53,058 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1415234794_0001_m_000005_0 is done. And is in the process of committing
2018-03-22 21:33:53,091 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2018-03-22 21:33:53,091 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1415234794_0001_m_000005_0' done.
2018-03-22 21:33:53,092 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1415234794_0001_m_000005_0
2018-03-22 21:33:53,092 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1415234794_0001_m_000006_0
2018-03-22 21:33:53,097 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2018-03-22 21:33:53,365 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@74d01311
2018-03-22 21:33:53,371 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: hdfs://slave1:9000/weather/30yr_03813.dat:0+16344626
2018-03-22 21:33:53,424 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2018-03-22 21:33:53,424 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2018-03-22 21:33:53,425 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2018-03-22 21:33:53,425 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2018-03-22 21:33:53,425 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2018-03-22 21:33:53,428 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2018-03-22 21:33:53,726 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 0%
2018-03-22 21:33:54,893 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2018-03-22 21:33:54,894 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2018-03-22 21:33:54,894 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2018-03-22 21:33:54,895 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 2633680; bufvoid = 104857600
2018-03-22 21:33:54,895 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 25160928(100643712); length = 1053469/6553600
2018-03-22 21:33:55,347 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2018-03-22 21:33:55,373 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1415234794_0001_m_000006_0 is done. And is in the process of committing
2018-03-22 21:33:55,391 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2018-03-22 21:33:55,392 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1415234794_0001_m_000006_0' done.
2018-03-22 21:33:55,394 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1415234794_0001_m_000006_0
2018-03-22 21:33:55,395 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1415234794_0001_m_000007_0
2018-03-22 21:33:55,399 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2018-03-22 21:33:55,754 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@465fadce
2018-03-22 21:33:55,760 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: hdfs://slave1:9000/weather/30yr_03872.dat:0+16339046
2018-03-22 21:33:55,898 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2018-03-22 21:33:55,898 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2018-03-22 21:33:55,898 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2018-03-22 21:33:55,899 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2018-03-22 21:33:55,899 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2018-03-22 21:33:55,901 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2018-03-22 21:33:59,361 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2018-03-22 21:33:59,362 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2018-03-22 21:33:59,362 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2018-03-22 21:33:59,362 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 2628120; bufvoid = 104857600
2018-03-22 21:33:59,362 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 25163152(100652608); length = 1051245/6553600
2018-03-22 21:33:59,725 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2018-03-22 21:33:59,739 INFO [org.apache.hadoop.mapreduce.Job] - map 70% reduce 0%
2018-03-22 21:33:59,746 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1415234794_0001_m_000007_0 is done. And is in the process of committing
2018-03-22 21:33:59,756 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2018-03-22 21:33:59,756 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1415234794_0001_m_000007_0' done.
2018-03-22 21:33:59,756 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1415234794_0001_m_000007_0
2018-03-22 21:33:59,756 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1415234794_0001_m_000008_0
2018-03-22 21:33:59,760 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2018-03-22 21:34:00,056 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@4d905742
2018-03-22 21:34:00,061 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: hdfs://slave1:9000/weather/30yr_03816.dat:0+16156518
2018-03-22 21:34:00,093 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2018-03-22 21:34:00,093 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2018-03-22 21:34:00,093 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2018-03-22 21:34:00,094 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2018-03-22 21:34:00,094 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2018-03-22 21:34:00,096 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2018-03-22 21:34:00,741 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 0%
2018-03-22 21:34:04,668 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2018-03-22 21:34:04,668 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2018-03-22 21:34:04,669 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2018-03-22 21:34:04,669 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 2602170; bufvoid = 104857600
2018-03-22 21:34:04,669 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 25173532(100694128); length = 1040865/6553600
2018-03-22 21:34:04,767 INFO [org.apache.hadoop.mapreduce.Job] - map 80% reduce 0%
2018-03-22 21:34:05,031 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2018-03-22 21:34:05,049 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1415234794_0001_m_000008_0 is done. And is in the process of committing
2018-03-22 21:34:05,056 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2018-03-22 21:34:05,056 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1415234794_0001_m_000008_0' done.
2018-03-22 21:34:05,056 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1415234794_0001_m_000008_0
2018-03-22 21:34:05,056 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1415234794_0001_m_000009_0
2018-03-22 21:34:05,059 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2018-03-22 21:34:05,204 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@2857a293
2018-03-22 21:34:05,208 INFO [org.apache.hadoop.mapred.MapTask] - Processing split: hdfs://slave1:9000/weather/30yr_03103.dat:0+16075112
2018-03-22 21:34:05,239 INFO [org.apache.hadoop.mapred.MapTask] - (EQUATOR) 0 kvi 26214396(104857584)
2018-03-22 21:34:05,239 INFO [org.apache.hadoop.mapred.MapTask] - mapreduce.task.io.sort.mb: 100
2018-03-22 21:34:05,240 INFO [org.apache.hadoop.mapred.MapTask] - soft limit at 83886080
2018-03-22 21:34:05,240 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufvoid = 104857600
2018-03-22 21:34:05,240 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396; length = 6553600
2018-03-22 21:34:05,244 INFO [org.apache.hadoop.mapred.MapTask] - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2018-03-22 21:34:05,767 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 0%
2018-03-22 21:34:06,267 INFO [org.apache.hadoop.mapred.LocalJobRunner] -
2018-03-22 21:34:06,268 INFO [org.apache.hadoop.mapred.MapTask] - Starting flush of map output
2018-03-22 21:34:06,268 INFO [org.apache.hadoop.mapred.MapTask] - Spilling map output
2018-03-22 21:34:06,268 INFO [org.apache.hadoop.mapred.MapTask] - bufstart = 0; bufend = 2586160; bufvoid = 104857600
2018-03-22 21:34:06,268 INFO [org.apache.hadoop.mapred.MapTask] - kvstart = 26214396(104857584); kvend = 25179936(100719744); length = 1034461/6553600
2018-03-22 21:34:06,784 INFO [org.apache.hadoop.mapreduce.Job] - map 90% reduce 0%
2018-03-22 21:34:06,962 INFO [org.apache.hadoop.mapred.MapTask] - Finished spill 0
2018-03-22 21:34:07,010 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1415234794_0001_m_000009_0 is done. And is in the process of committing
2018-03-22 21:34:07,021 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map
2018-03-22 21:34:07,022 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1415234794_0001_m_000009_0' done.
2018-03-22 21:34:07,022 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1415234794_0001_m_000009_0
2018-03-22 21:34:07,023 INFO [org.apache.hadoop.mapred.LocalJobRunner] - map task executor complete.
2018-03-22 21:34:07,028 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Waiting for reduce tasks
2018-03-22 21:34:07,040 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Starting task: attempt_local1415234794_0001_r_000000_0
2018-03-22 21:34:07,068 INFO [org.apache.hadoop.yarn.util.ProcfsBasedProcessTree] - ProcfsBasedProcessTree currently is supported only on Linux.
2018-03-22 21:34:07,349 INFO [org.apache.hadoop.mapred.Task] - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@d1a9f20
2018-03-22 21:34:07,356 INFO [org.apache.hadoop.mapred.ReduceTask] - Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@25754daa
2018-03-22 21:34:07,386 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - MergerManager: memoryLimit=1503238528, maxSingleShuffleLimit=375809632, mergeThreshold=992137472, ioSortFactor=10, memToMemMergeOutputsThreshold=10
2018-03-22 21:34:07,391 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - attempt_local1415234794_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
2018-03-22 21:34:07,527 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1415234794_0001_m_000000_0 decomp: 3164678 len: 3164682 to MEMORY
2018-03-22 21:34:07,591 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 3164678 bytes from map-output for attempt_local1415234794_0001_m_000000_0
2018-03-22 21:34:07,606 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 3164678, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->3164678
2018-03-22 21:34:07,621 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1415234794_0001_m_000003_0 decomp: 3156530 len: 3156534 to MEMORY
2018-03-22 21:34:07,642 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 3156530 bytes from map-output for attempt_local1415234794_0001_m_000003_0
2018-03-22 21:34:07,643 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 3156530, inMemoryMapOutputs.size() -> 2, commitMemory -> 3164678, usedMemory ->6321208
2018-03-22 21:34:07,673 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1415234794_0001_m_000006_0 decomp: 3160418 len: 3160422 to MEMORY
2018-03-22 21:34:07,718 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 3160418 bytes from map-output for attempt_local1415234794_0001_m_000006_0
2018-03-22 21:34:07,718 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 3160418, inMemoryMapOutputs.size() -> 3, commitMemory -> 6321208, usedMemory ->9481626
2018-03-22 21:34:07,728 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1415234794_0001_m_000009_0 decomp: 3103394 len: 3103398 to MEMORY
2018-03-22 21:34:07,794 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 3103394 bytes from map-output for attempt_local1415234794_0001_m_000009_0
2018-03-22 21:34:07,794 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 3103394, inMemoryMapOutputs.size() -> 4, commitMemory -> 9481626, usedMemory ->12585020
2018-03-22 21:34:07,804 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 0%
2018-03-22 21:34:07,805 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1415234794_0001_m_000007_0 decomp: 3153746 len: 3153750 to MEMORY
2018-03-22 21:34:07,843 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 3153746 bytes from map-output for attempt_local1415234794_0001_m_000007_0
2018-03-22 21:34:07,843 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 3153746, inMemoryMapOutputs.size() -> 5, commitMemory -> 12585020, usedMemory ->15738766
2018-03-22 21:34:07,855 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1415234794_0001_m_000004_0 decomp: 3163610 len: 3163614 to MEMORY
2018-03-22 21:34:07,884 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 3163610 bytes from map-output for attempt_local1415234794_0001_m_000004_0
2018-03-22 21:34:07,885 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 3163610, inMemoryMapOutputs.size() -> 6, commitMemory -> 15738766, usedMemory ->18902376
2018-03-22 21:34:07,892 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1415234794_0001_m_000008_0 decomp: 3122606 len: 3122610 to MEMORY
2018-03-22 21:34:07,915 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 3122606 bytes from map-output for attempt_local1415234794_0001_m_000008_0
2018-03-22 21:34:07,915 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 3122606, inMemoryMapOutputs.size() -> 7, commitMemory -> 18902376, usedMemory ->22024982
2018-03-22 21:34:07,921 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1415234794_0001_m_000001_0 decomp: 3165338 len: 3165342 to MEMORY
2018-03-22 21:34:07,937 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 3165338 bytes from map-output for attempt_local1415234794_0001_m_000001_0
2018-03-22 21:34:07,937 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 3165338, inMemoryMapOutputs.size() -> 8, commitMemory -> 22024982, usedMemory ->25190320
2018-03-22 21:34:07,943 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1415234794_0001_m_000002_0 decomp: 3165182 len: 3165186 to MEMORY
2018-03-22 21:34:07,962 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 3165182 bytes from map-output for attempt_local1415234794_0001_m_000002_0
2018-03-22 21:34:07,963 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 3165182, inMemoryMapOutputs.size() -> 9, commitMemory -> 25190320, usedMemory ->28355502
2018-03-22 21:34:07,969 INFO [org.apache.hadoop.mapreduce.task.reduce.LocalFetcher] - localfetcher#1 about to shuffle output of map attempt_local1415234794_0001_m_000005_0 decomp: 3157610 len: 3157614 to MEMORY
2018-03-22 21:34:07,983 INFO [org.apache.hadoop.mapreduce.task.reduce.InMemoryMapOutput] - Read 3157610 bytes from map-output for attempt_local1415234794_0001_m_000005_0
2018-03-22 21:34:07,983 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - closeInMemoryFile -> map-output of size: 3157610, inMemoryMapOutputs.size() -> 10, commitMemory -> 28355502, usedMemory ->31513112
2018-03-22 21:34:07,984 INFO [org.apache.hadoop.mapreduce.task.reduce.EventFetcher] - EventFetcher is interrupted.. Returning
2018-03-22 21:34:07,986 INFO [org.apache.hadoop.mapred.LocalJobRunner] - 10 / 10 copied.
2018-03-22 21:34:07,987 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - finalMerge called with 10 in-memory map-outputs and 0 on-disk map-outputs
2018-03-22 21:34:08,006 INFO [org.apache.hadoop.mapred.Merger] - Merging 10 sorted segments
2018-03-22 21:34:08,006 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 10 segments left of total size: 31513032 bytes
2018-03-22 21:34:13,097 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > sort
2018-03-22 21:34:13,816 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 63%
2018-03-22 21:34:13,919 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merged 10 segments, 31513112 bytes to disk to satisfy reduce memory limit
2018-03-22 21:34:13,922 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 1 files, 31513098 bytes from disk
2018-03-22 21:34:13,924 INFO [org.apache.hadoop.mapreduce.task.reduce.MergeManagerImpl] - Merging 0 segments, 0 bytes from memory into reduce
2018-03-22 21:34:13,924 INFO [org.apache.hadoop.mapred.Merger] - Merging 1 sorted segments
2018-03-22 21:34:13,926 INFO [org.apache.hadoop.mapred.Merger] - Down to the last merge-pass, with 1 segments left of total size: 31513086 bytes
2018-03-22 21:34:13,927 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > sort
2018-03-22 21:34:14,099 INFO [org.apache.hadoop.conf.Configuration.deprecation] - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2018-03-22 21:34:16,099 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
2018-03-22 21:34:16,819 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 73%
2018-03-22 21:34:19,103 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
2018-03-22 21:34:19,823 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 89%
2018-03-22 21:34:21,485 INFO [org.apache.hadoop.mapred.Task] - Task:attempt_local1415234794_0001_r_000000_0 is done. And is in the process of committing
2018-03-22 21:34:21,493 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
2018-03-22 21:34:21,493 INFO [org.apache.hadoop.mapred.Task] - Task attempt_local1415234794_0001_r_000000_0 is allowed to commit now
2018-03-22 21:34:21,540 INFO [org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter] - Saved output of task 'attempt_local1415234794_0001_r_000000_0' to hdfs://slave1:9000/weather/weather-out/_temporary/0/task_local1415234794_0001_r_000000
2018-03-22 21:34:21,553 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce > reduce
2018-03-22 21:34:21,554 INFO [org.apache.hadoop.mapred.Task] - Task 'attempt_local1415234794_0001_r_000000_0' done.
2018-03-22 21:34:21,555 INFO [org.apache.hadoop.mapred.LocalJobRunner] - Finishing task: attempt_local1415234794_0001_r_000000_0
2018-03-22 21:34:21,556 INFO [org.apache.hadoop.mapred.LocalJobRunner] - reduce task executor complete.
2018-03-22 21:34:21,826 INFO [org.apache.hadoop.mapreduce.Job] - map 100% reduce 100%
2018-03-22 21:34:21,827 INFO [org.apache.hadoop.mapreduce.Job] - Job job_local1415234794_0001 completed successfully
2018-03-22 21:34:21,924 INFO [org.apache.hadoop.mapreduce.Job] - Counters: 38
File System Counters
FILE: Number of bytes read=63090362
FILE: Number of bytes written=239634726
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=1061789866
HDFS: Number of bytes written=99
HDFS: Number of read operations=177
HDFS: Number of large read operations=0
HDFS: Number of write operations=13
Map-Reduce Framework
Map input records=2629660
Map output records=2626091
Map output bytes=26260910
Map output materialized bytes=31513152
Input split bytes=1060
Combine input records=0
Combine output records=0
Reduce input groups=10
Reduce shuffle bytes=31513152
Reduce input records=2626091
Reduce output records=10
Spilled Records=5252182
Shuffled Maps =10
Failed Shuffles=0
Merged Map outputs=10
GC time elapsed (ms)=1412
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=9857400832
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=163038920
File Output Format Counters
Bytes Written=99
如果调用 hadoop 命令的第一个参数是类名,Hadoop 就会启动一个 JVM 来运行这个类。使用 hadoop 命令运行作业比直接使用 Java 命令来运行更方便,因为前者将 Hadoop 库文件(及其依赖关系)路径加入到类路径参数中, 同时也能获得 Hadoop 的配置文件。需要定义一个 HADOOP_CLASSPATH 环境变量用于添加应用程序类的路径,然后由 Hadoop 脚本来执行相关操作。
运行作业所得到的输出提供了一些有用的信息。例如我们可以看到,这个作业有指定的标识,即job_1432108212572_0001,并且执行了一个 map 任务和一个 reduce 任务。
输出的最后一部分,以 Counter 为标题,显示 Hadoop 上运行的每个作业的一些统计信息。这些信息对检查数据是否按照预期进行处理非常有用。
输出数据写入out 目录,其中每个 reducer 都有一个输出文件。我们的例子中只有一个 reducer,所以只能找到一个名为 part-00000 的文件:
[hadoop@djt002 hadoop-2.2.0-x64]$ hadoop fs -cat /weather/out/part-r-00000 03103 132
这个结果和我们之前手动寻找的结果一样。我们把这个结果解释为编号为03103气象站的平均气温为13.2摄氏度。
注意:上面输出结果的输入数据集是示例中的10条数据,而不是下载的整个数据集。如果大家使用整个数据集跑出的结果不一致,很正常。
监控 Hadoop
Ambari 仪表盘和监视器工具为我们提供了比较直观的Hadoop集群信息。一旦Hadoop 集群启动,Ambari可以监控整个集群的健康状况。
另外我们还可以通过Azkaban 来负责MapReduce的作业调度,同时它能提供MapReduce运行信息和详细的执行日志,包括运行时间。
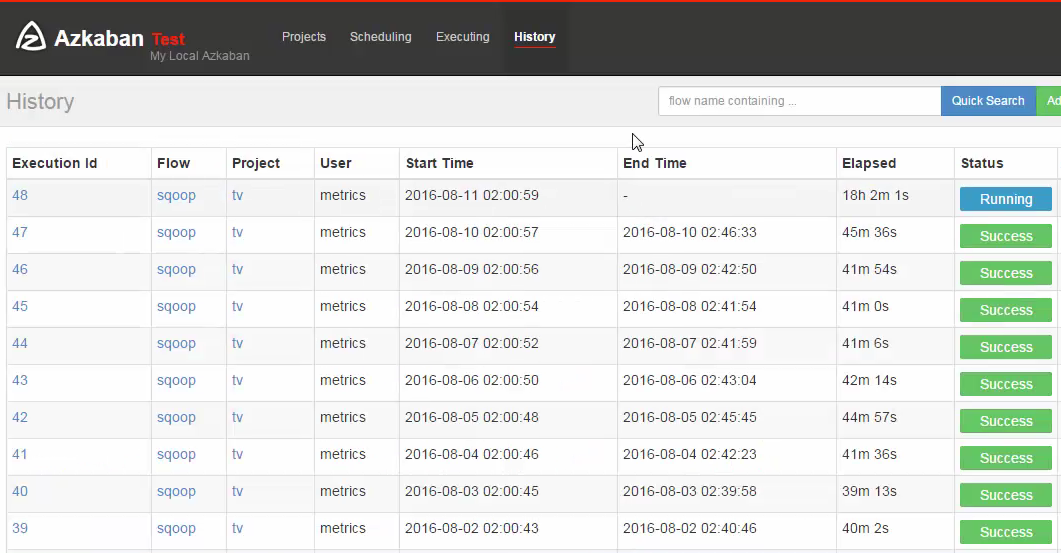
至于Azkaban 作业调度以及Ambari集群部署监控,在课程的高级阶段我们告诉大家该如何使用。 目前这个阶段重点掌握MapReduce的编程套路即可。
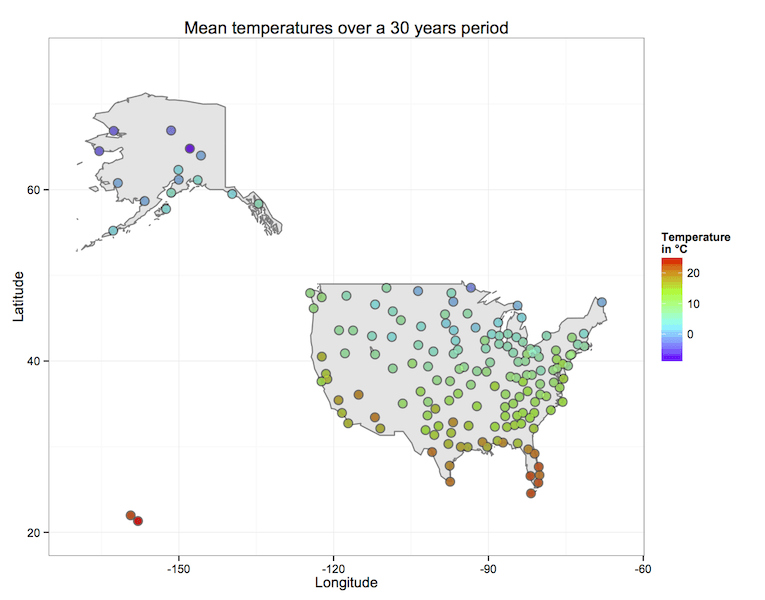
数据可视化
当 MapReduce Job执行完毕,我们可以将结果集入库然后使用可视化技术对数据进行可视化。
可视化结果展示了美国所有气象站30年来的平均气温。
希望大家通过这个项目,能够了解MapReduce的编程套路以及执行流程。大家不用担心也不用着急,跟着系统课程的节奏,我们会在后续课程中逐步深入学习MapReduce。
/**
*
*/
package com.dajiangtai.hadoop;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.dajiangtai.hadoop.WordCountTest.Map;
import com.dajiangtai.hadoop.WordCountTest.Reduce;
import com.sun.tools.jdi.EventSetImpl.Itr;
/**
* @author yizhijing
*
*/
public class Temperature {
public static class Map extends Mapper<LongWritable, Text,Text ,IntWritable>{
public void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{
String line = value.toString();
//string.trim()此字符串移除了前导和尾部空白的副本;如果没有前导和尾部空白,则返回此字符串
////substring(int beginIndex, int endIndex)---eg:"hamburger".substring(4, 8) returns "urge"
//Integer.parseInt(string a)将字符串参数作为有符号的十进制整数进行解析
int temperature = Integer.parseInt(line.substring(14,19).trim());
//过滤无效数据
if(temperature != -9999){
//获取当前split的文件名
FileSplit fileSplit = (FileSplit) context.getInputSplit();
String weatherStationId = fileSplit.getPath().getName().substring(5, 10);//通过文件名称提取气象站id
context.write(new Text(weatherStationId), new IntWritable(temperature));
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable>{
/**Iterable<IntWritable> values;------------
*声明了values是一个聚集元素集:set of elements of type T,可以不太准确的将其理解为一数组。
*使用迭代器之后对IntWritable类型的数组或集合values进行遍历,用jdk1.5的for each,写法如下:
*for(IntWritable val : values) {System.out.println(val);}
*Iterable达到了解耦效果的意思是:使用传统的for循环时,访问代码和集合本身是紧耦合,无法将访问逻辑
*从集合类和客户端代码中分离出来,每一种集合对应一种遍历方法,客户端代码无法复用。
*/
private IntWritable result = new IntWritable();
public void reduce(Text key,Iterable<IntWritable> value,Context context) throws IOException, InterruptedException{
int sum = 0;
int count = 0;
for(IntWritable val : value){
sum += val.get();
count++;
}
result.set(sum/count);
context.write(key, result);
}
}
public static void main(String[] args) throws IllegalArgumentException, IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
// conf.addResource("")
Path myPath = new Path("hdfs://slave1:9000/weather/weather-out");//输出路径
FileSystem hdfs = myPath.getFileSystem(conf);//获取文件系统
if(hdfs.isDirectory(myPath)){
hdfs.delete(myPath, true);
}
Job job = Job.getInstance();
job.setJarByClass(WordCountTest.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//注意导入正确的包
//导入有多个 文件的路径时
FileInputFormat.addInputPath(job , new Path("hdfs://slave1:9000/weather/"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://slave1:9000/weather/weather-out"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号