
高并发服务器逻辑处理瓶颈,如何解决?
https://mp.weixin.qq.com/s/GHHHvgURdZpNJ1Ec6RHgPg
高并发衡量指标
响应时间:系统对请求做出响应的时间,即一个http请求返回所用的时间;
吞吐量:单位时间内处理的请求数量;
QPS(TPS):每秒可以处理的请求数或事务数;
并发用户数:同时承载正常使用系统功能的用户数量,即多少人同时使用,系统还能正常运行的用户数量;
根据上面衡量指标可以看到,提高并发能力必须解决如下几个问题:
-
如何提高并发连接数?
-
那么多的连接数怎么进行业务处理?
-
应用服务器的处理水平又该怎么提高?
-
如何使用微服务架构提升高并发逻辑?
1)、如何提高并发连接数?
如下图所示,常规的单一网络连接模型只能1个连接对应1个线程,压力都集中在内存,导致内存开销非常大,肯定支撑的连接数有限!(直接挂掉)
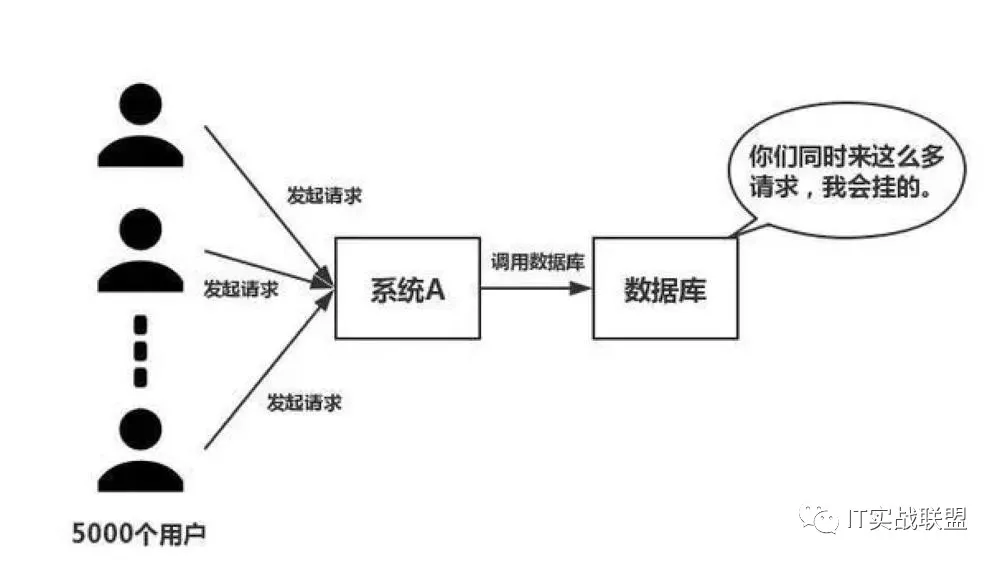
单一网络连接模型
选用合适的网络IO模型或者selector,通过使用一个线程轮询或者事件触发的方式,能支持几万甚至更多的连接数,再配合上nginx做负载就更完美了。
那么多的连接数怎么进行业务处理?
nginx只是具有反向代理和负载均衡的功能,并不能处理具体的业务逻辑,不能担当应用服务器来使用。例如webSphere 、tomcat和jetty等,但是可以利用nginx将接受到的大量连接通过均衡的方式(轮询,权重,hash)分配到不同的应用服务器中进行业务处理!

nginx负载
3)应用服务器的处理水平又该怎么提高?
要提高应用服务器的处理水平就要了解自己的应用服务器的瓶颈在哪里,一般有两个:
-
数据库压力:数据库是支撑产品业务的核心模块,系统的高并发的主要压力也是来源于数据库。处理方式有如下这些:
数据库本身:建立有效索引、读写分离、双主互备、分库分表(sharding-jdbc等实现)等策略,提高数据库处理能力,减少压力!
结合内存数据库:例如redid、memcached等,根据业务需要缓存一些数据字典、枚举变量和频繁使用数据等减少数据库访问次数,提升数据库处理能力。
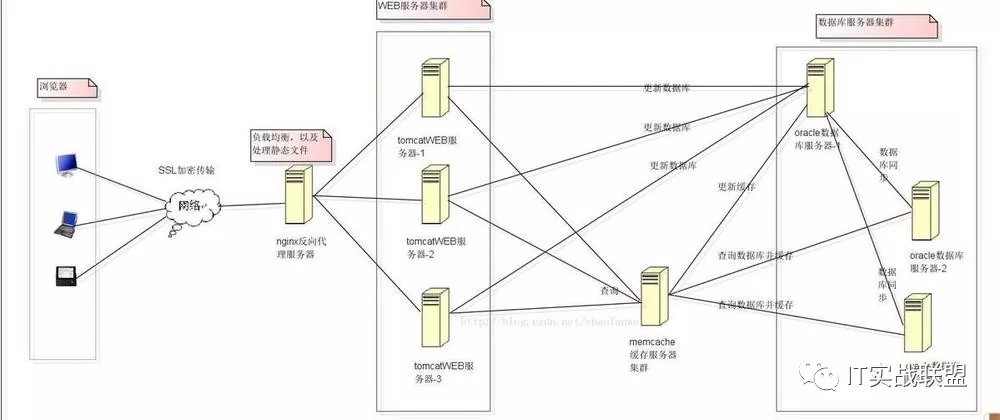
web集群架构图
如上图web集群架构图所示:
-
用nginx负载多台应用服务器;
-
使用redid/memcached做业务缓存;
-
再加上数据库集群;
组成了经典的web高并发集群架构。
-
代码中的业务逻辑:
大家可以 参考阿里巴巴java开发手册 中的开发规范来做就好了,总代来说少创建线程、少创建对象、少加锁、防止死锁、少创建线程、注意内存回收等策略,来提升代码性能。
开发中可以采用前后端分离的架构模式,动静分离、松耦合等提升前后端处理能力。
4)如何使用微服务架构提升高并发逻辑?
先看一下非常火的这张微服务架构图:
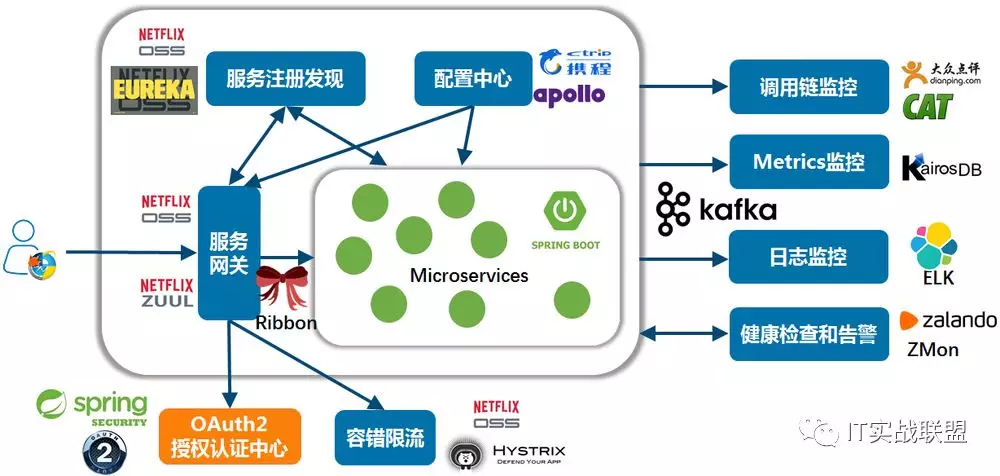
微服务架构图
主要包含11大核心组件,分别是:
核心支撑组件
-
服务网关Zuul
-
服务注册发现Eureka+Ribbon
-
服务配置中心Apollo
-
认证授权中心Spring Security OAuth
-
服务框架Spring MVC/Boot
-
监控反馈组件
数据总线Kafka
-
日志监控ELK
-
调用链监控CAT
-
Metrics监控KairosDB
-
健康检查和告警ZMon
-
限流熔断和流聚合Hystrix/Turbine
总结
出来上述几点解决高并发服务器逻辑处理瓶颈外,还要考虑网络因素,例如采用CDN加速,将不同地点的请求分发到不同的服务集群上,避免网络对速度的影响!
总之,根据自身实际业务在合理范围内尽可能的拆分,拆分以后同类服务可以通过水平扩展达到整体的高性能高并发,同时将越脆弱的资源放置在链路的越末端,访问的时候尽量将访问链接缩短,降低每次访问的资源消耗。服务之间直接restful模型使用http调用,或者redis,kafka类的消息中间件通信。单个服务直接使用nginx做负载集群,同时前后端分离,数据库分库分表等一整套分布式服务系统!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号