
sql2008 计划自动创建数据库分区【转】
本文转自:http://jingyan.baidu.com/article/6b97984d9a26ec1ca3b0bf77.html
sql2008 计划自动创建数据库分区
固定增量的数据,自动创建分区作业.
步骤一:创建分区的计划任务
-
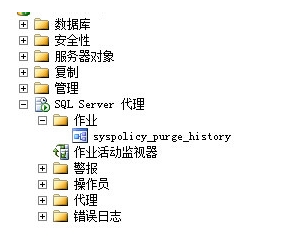
打开MsSQL2008,找到作业该项,如果打不开或者SQL Server代理是未启动状态,请先在windows服务中启动SQL Server代理(参考图片),

-
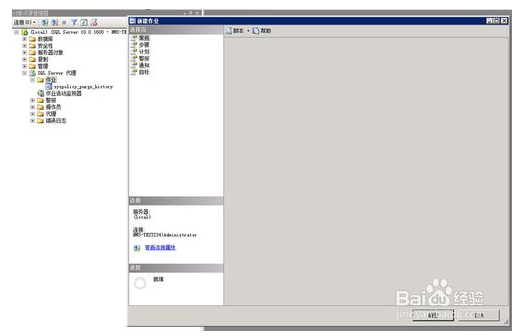
右击MsSQL2008对象资源管理器中的作业,选择新建作业,输入该作业你想用的名称,类别不用管,说明里面是输入一些该作业完成的功能,可不写,请务必勾选已启用复选框.
-
点击新建作业窗体左侧的步骤项,点击右侧区域下方的新建按钮,输入步骤名称,类型请选择Transact-SQL脚本(T-SQL),运行身份默认,数据库请选择要进行分区的数据库,请不要选择master默认的,命令文本框中输入如下代码:
/*--------------------创建数据库的文件组和物理文件------------------------*/
declare @tableName varchar(50), @fileGroupName varchar(50), @ndfName varchar(50), @newNameStr varchar(50), @fullPath
varchar(250), @newDay varchar(50), @oldDay datetime, @partFunName varchar(50), @schemeName varchar(50)
set @tableName='WaterNet_DaFeng' --当前数据库名
set @newDay=substring(CONVERT(varchar(100), GETDATE(), 23),0,8)+'-01' --按月 --CONVERT(varchar(100), GETDATE(), 23):按天 CONVERT(varchar(100), GETDATE(), 114):按时间 substring(CONVERT(varchar(100), GETDATE(), 23),0,8)+'-01' :按月
set @oldDay=cast(CONVERT(varchar(10),dateadd(day,-1,getdate()), 120 ) as datetime)
set @newNameStr=Replace(Replace(@newDay,':','_'),'-','_')
set @fileGroupName=N'G'+@newNameStr
set @ndfName=N'F'+@newNameStr+''
set @fullPath=N'D:\\Program Files\\Microsoft SQL Server\\MSSQL10.MSSQLSERVER\\MSSQL\\DATA\\'+@ndfName+'.ndf'--此处该为自己的数据文件路径,lui注释2015-5-4(右击服务器-属性-数据库设置可看到)
set @partFunName=N'pf_Time'
set @schemeName=N'ps_Time'
--创建文件组
if exists(select * from sys.filegroups where name=@fileGroupName)
begin
print '文件组存在,不需添加'
end
else
begin
exec('ALTER DATABASE '+@tableName+' ADD FILEGROUP ['+@fileGroupName+']')
print '新增文件组'
if exists(select * from sys.partition_schemes where name =@schemeName)
begin
exec('alter partition scheme '+@schemeName+' next used ['+@fileGroupName+']')
print '修改分区方案'
end
if exists(select * from sys.partition_range_values where function_id=(select function_id from
sys.partition_functions where name =@partFunName) )--and value=@oldDay 如果上次没做成功,则会导致以后都不会建立边界,所以屏蔽 2016-10-18 by lui
begin
exec('alter partition function '+@partFunName+'() split range('''+@newDay+''')')
print '修改分区函数'
end
end
--创建NDF文件
if exists(select * from sys.database_files where [state]=0 and (name=@ndfName or physical_name=@fullPath))
begin
print 'ndf文件存在,不需添加'
end
else
begin
exec('ALTER DATABASE '+@tableName+' ADD FILE (NAME ='+@ndfName+',FILENAME = '''+@fullPath+''')TO FILEGROUP ['+@fileGroupName+']')
print '新创建ndf文件'
end
/*--------------------以上创建数据库的文件组和物理文件------------------------*/
--分区函数
if exists(select * from sys.partition_functions where name =@partFunName)
begin
print '此处修改需要在修改分区函数之前执行'
end
else
begin
exec('CREATE PARTITION FUNCTION '+@partFunName+'(DateTime)AS RANGE RIGHT FOR VALUES ('''+@newDay+''')')
print '新创建分区函数'
end
--分区方案
if exists(select * from sys.partition_schemes where name =@schemeName)
begin
print '此处修改需要在修改分区方案之前执行'
end
else
begin
exec('CREATE PARTITION SCHEME '+@schemeName+' AS PARTITION '+@partFunName+' TO
(''PRIMARY'','''+@fileGroupName+''')')
print '新创建分区方案'
end
print '---------------以下是变量定义值显示---------------------'
print '当前数据库:'+@tableName
print '当前日期:'+@newDay+'(用作随机生成的各种名称和分区界限)'
print '合法命名方式:'+@newNameStr
print '文件组名称:'+@fileGroupName
print 'ndf物理文件名称:'+@ndfName
print '物理文件完整路径:'+@fullPath
print '分区函数:'+@partFunName
print '分区方案:'+@schemeName
/*
--查看创建的分区函数
select * from sys.partition_functions
--查看分区函数的临界值
select * from sys.partition_range_values
--查询分区方案
select * from sys.partition_schemes
--查询表数据在哪个分区中存储,where条件查询第一个分区中存在的数据
select *,$partition.pf_SaveTime(分区字段) as Patition from 表名 where $partition.pf_SaveTime(分区字段)=1
*/GO
点击确定按钮
上述代码中的变量名称,路径等均可自行修改,上述是按天为单位,以G开头的日期作为文件组名称,以F开头的日期作为物理分区文件名即ndf文件名称

-
选择新建分区左侧的计划项,然后点击右侧区域下方的新建按钮,设定新建分区的时间间隔,图中设置的是每天创建一个新的分区,用户也可以自行修改,按月,按周,按自定义时间等
其他的条目,通知,警报,目标可自行设置,也可不设置,至此自动创建分区的计划任务已成功设置.
 END
END
步骤二:对表应用分区方案和分区函数
-
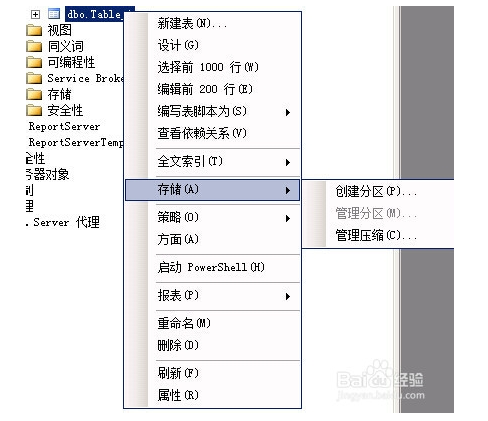
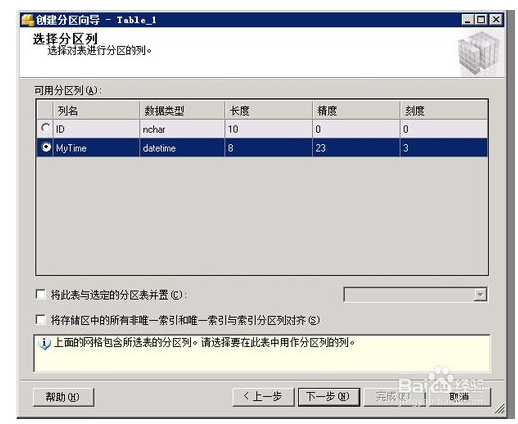
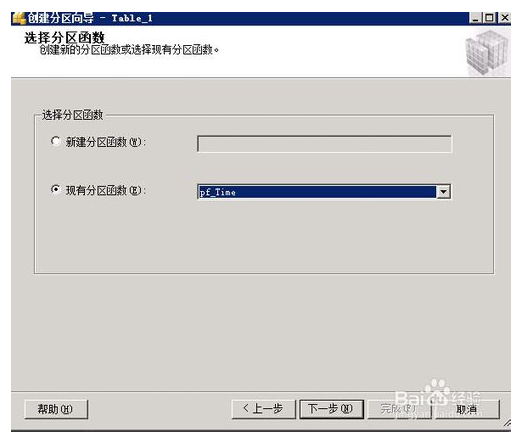
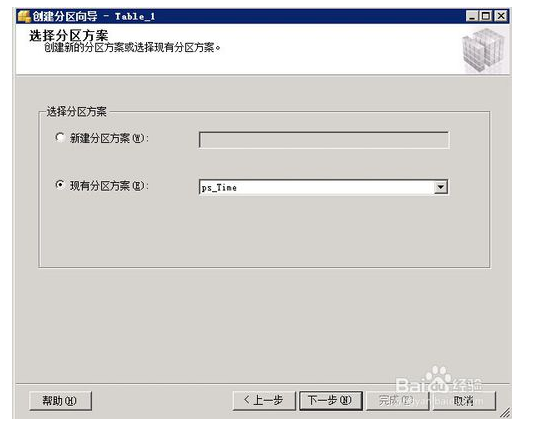
右击要分区的表,选择存储菜单下的创建分区,上述步骤一中创建的分区函数是按datetime类型进行的分区,所以创建分区的时候需要选择相应类型的字段作为分区依据,用户也可以根据int型或其他类型的字段进行分区,选择下一步,使用现有分区函数下一步使用现有分区方案,下一步会自动按照分区方案执行的日期进行分区,继续点击下一步选择立即执行,完成后即可完成的整体的表分区自动执行.
需注意:刚设置完第一步的计划任务,可能不会执行第一步的分区方案的代码,也就意味着没有创建分区函数和分区方案,第二步设置的时候使用现有分区函数和使用现有分区方案也就不可用,可先把第一步的代码执行一遍即可.
 附录:数据文件备份方案1(目前发现:此方法只适合将文件恢复到数据库源服务器上,因为数据库全备份恢复到别的机子上时,数据物理文件名称会自动改变成数据库名加编号,直接拷贝的文件覆盖上去后,数据库会报错启用不了):【备份】1:停掉数据库服务;2:将数据文件拷贝出来;3:启动数据库服务;4:将对应分区文件的数据删掉(delete from HistoryData where $partition.pf_Time(startTime) in(29,30);--删除第29,30分区的数据,pf_Time为分区函数名)5:收缩数据库; 这样空间就释放了;【恢复】1:停掉数据库服务;2:将备份文件覆盖进去;3:启动数据库服务;数据文件备份方案2:(目前采用此方法)
附录:数据文件备份方案1(目前发现:此方法只适合将文件恢复到数据库源服务器上,因为数据库全备份恢复到别的机子上时,数据物理文件名称会自动改变成数据库名加编号,直接拷贝的文件覆盖上去后,数据库会报错启用不了):【备份】1:停掉数据库服务;2:将数据文件拷贝出来;3:启动数据库服务;4:将对应分区文件的数据删掉(delete from HistoryData where $partition.pf_Time(startTime) in(29,30);--删除第29,30分区的数据,pf_Time为分区函数名)5:收缩数据库; 这样空间就释放了;【恢复】1:停掉数据库服务;2:将备份文件覆盖进去;3:启动数据库服务;数据文件备份方案2:(目前采用此方法)
1:先收缩数据库,(确保数据库文件目录有足够空间);2:全备份数据库成bak文件;压缩保存记录好数据时间;3:删除在线库中过期数据;delete删;4:收缩数据库;(如果收缩后文件空间未释放(未报错);可删除索引,重建聚集索引后,再收缩)---如:create CLUSTERED INDEX HistoryData_idx_u_03 on HistoryData(devId,cid,startTime,enname)ON ps_Time(startTime) ;--分区聚集索引 ps_Time为分区方案名 ,执行语句前一定先确认数据库里分区方案名称!
---如:create INDEX HistoryData_idx_u_02 on HistoryData(id)ON ps_Time(startTime) ; --给id创建分区索引
--【或者试试这个,2个合并】 create CLUSTERED INDEX HistoryData_idx_u_03 on HistoryData(id,devId,cid,startTime,enname)ON ps_Time(startTime) ;--分区聚集索引 ps_Time为分区方案名 ,执行语句前一定先确认数据库里分区方案名称!如果收缩报错,如锁错误 1222,则不要用管理器界面收缩,直接在收缩界面,生成脚本,在查询分析器里执行脚本收缩,即可成功,如下图所示: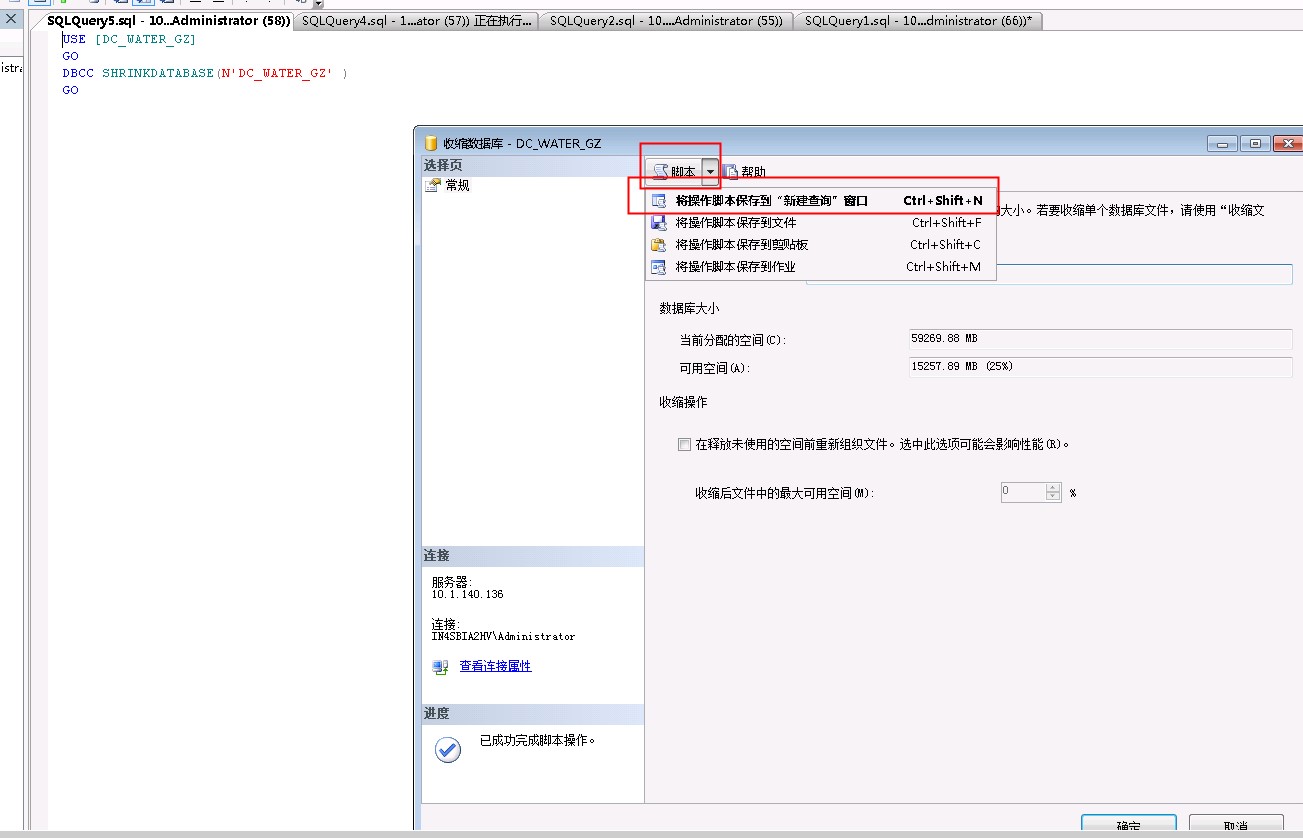 附录,查询:
附录,查询:--partition_scheme;partition_number;filegroup;range_boundary;rows
--分区方案;分区号;文件组;数据边界;数据条数;select convert(varchar(50), ps.name
) as partition_scheme,
p.partition_number,
convert(varchar(10), ds2.name) as filegroup,
convert(varchar(19), isnull(v.value, ''), 120) as range_boundary,
str(p.rows, 9) as rows
from sys.indexes i
join sys.partition_schemes ps on i.data_space_id = ps.data_space_id
join sys.destination_data_spaces dds
on ps.data_space_id = dds.partition_scheme_id
join sys.data_spaces ds2 on dds.data_space_id = ds2.data_space_id
join sys.partitions p on dds.destination_id = p.partition_number
and p.object_id = i.object_id and p.index_id = i.index_id
join sys.partition_functions pf on ps.function_id = pf.function_id
LEFT JOIN sys.Partition_Range_values v on pf.function_id = v.function_id
and v.boundary_id = p.partition_number - pf.boundary_value_on_right
WHERE i.object_id = object_id('HistoryData')--分区表名
and i.index_id in (0, 1)
order by p.partition_number目前手工操作;后续改为自动化实现;
