软工作业3:词频统计
一、程序分析
1.读文件到缓冲区
def process_file(dst): # 读文件到缓冲区 try: # 打开文件 f = open(dst, 'r') # dst为文本的目录路径 except IOError as s: print(s) return None try: # 读文件到缓冲区 bvffer = f.read() except: print('Read File Error!') return None f.close() return bvffer
2.统计每个单词的频率,存放在字典word_freq
def process_buffer(bvffer): if bvffer: word_freq = {} for item in bvffer.strip().split(): word = item.strip(punctuation+' ') if word in word_freq.keys(): word_freq[word] += 1 else: word_freq[word] = 1 return word_freq
3.输出前10 的单词
def output_result(word_freq): if word_freq: # 根据v[1]即词频数量排序 sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 print("词:%-5s 频:%-4d " % (item[0], item[1]))
4.主函数
def main(): dst = '1/Gone_with_the_wind.txt' # 《飘》文件的路径 bvffer = process_file(dst) word_freq = process_buffer(bvffer) output_result(word_freq)
二、 代码风格说明
1.Python 代码强调变量命名要字母,数字,下划线组成的或者引用某值的名字。2.缩进是四个空格。
三、程序运行命令、运行结果截图
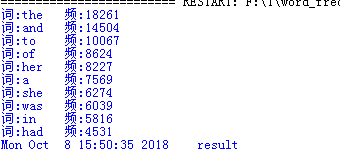
四、性能分析结果及改进
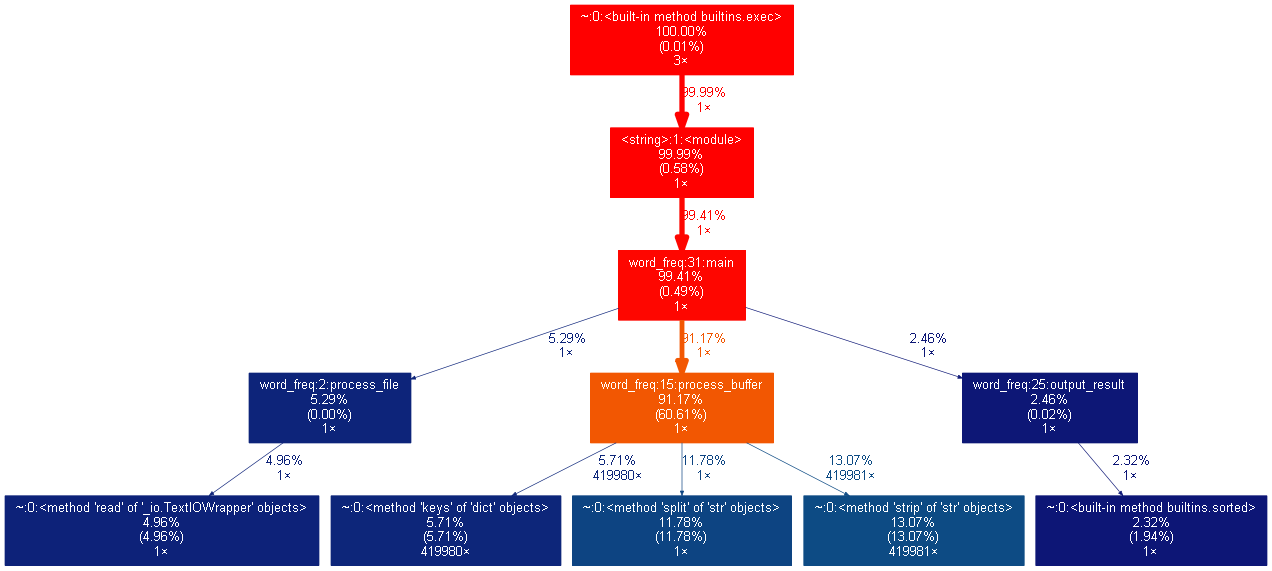
使用可视化工具分析
安装:graphviz , "pip install graphviz"; 下载转换 dot 的 python 代码
转化后的截图如下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号