Python爬虫案例
新的代码 :https://github.com/Whitehua/datamine.git
特性:
全自动爬取,每个城市建一张表
Mysql数据库
带有拟合曲线分析
2020.1.04
最近在做一个课程设计,关于爬取安居客房价信息的,本次用到的框架有
- BeautifulSoup
- xlwt,xlrd
- requests
- matplotlib
- pandas
- numpy
最终实现下图效果:
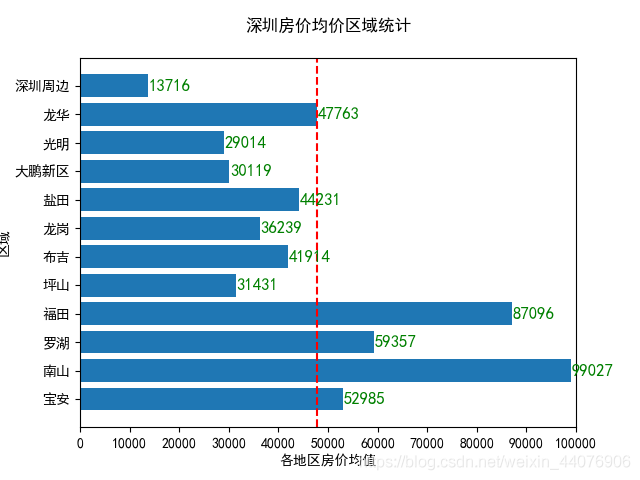
**
使用说明:
请先注册安居客账户
之后先运行spider.py
随后运行draw.py
**
_爬虫代码 _
spider.py
from bs4 import BeautifulSoup
import requests
import xlwt
import time,random
def getHouseList(url):
house = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER'}
# get从网页获取信息
res = requests.get(url, headers=headers)
# 解析内容
soup = BeautifulSoup(res.content, 'html.parser')
# 房源title
housename_divs = soup.find_all('div', class_='house-title')
for housename_div in housename_divs:
housename_as = housename_div.find_all('a')
for housename_a in housename_as:
housename = []
# 标题
housename.append(SplitString(housename_a.get_text()))
# 超链接
housename.append(housename_a.get('href'))
house.append(housename)
################################### 标签 ########################################
tagcache=soup.find_all('div', class_='house-details')
q=0
for housetag_divs in tagcache:
housetag_div = housetag_divs.find_all('div', class_='tags-bottom')
for tagarrange in housetag_div:
tag_div = tagarrange.find_all('span', class_='item-tags tag-others')
cache=[]
for i in range(len(tag_div)):
cache.append(tag_div[i].get_text())
house[q].append("~~".join(cache))
q=q+1
################################## 房屋信息 ######################################
housecache_divs=soup.find_all('div', class_='house-details')
i=0
for huseinfo_divs in housecache_divs:
# 房屋信息
huseinfo_div = huseinfo_divs.find('div', class_='details-item')
#info = [span.get_text() for span in huseinfo_div]
info = huseinfo_div.get_text()
infos = info.split('|')
# 户型
house[i].append(SplitString(infos[0]))
# 平米
house[i].append(infos[1])
# 层数
house[i].append(infos[2])
# 年限
house[i].append(SplitString(infos[3]))
i=i+1
############################## 查询总价 ##########################################
house_prices = soup.find_all('span', class_='price-det')
for i in range(len(house_prices)):
# 价格
price = house_prices[i].get_text()
house[i].append(price)
unit_prices = soup.find_all('span', class_='unit-price')
for i in range(len(unit_prices)):
# 单价
unitPrice = unit_prices[i].get_text()
house[i].append(unitPrice)
address = soup.find_all('span', class_='comm-address')
############################## 地址 ##############################################
for i in range(len(address)):
# 楼盘
houseAddress = address[i].get_text()
str=SplitString(houseAddress).split('-')
house[i].append(str[0])
# 区域
house[i].append(str[1])
# 所属商圈
house[i].append(str[2])
# 地址
house[i].append(str[3])
broker = soup.find_all('span', class_='broker-name broker-text')
for i in range(len(broker)):
# 联系人
brokerName = broker[i].get_text()
house[i].append(SplitString(brokerName))
return house
def SplitString(str):
str = "-".join(str.split())
str.replace('\r', '').replace('\t', '').replace('\n','')
return str
# 将房源信息写入excel文件
def writeExcel(excelPath, houses , pages):
workbook = xlwt.Workbook()
# 获取第一个sheet页
sheet = workbook.add_sheet('共'+format(pages)+'页')
row0 = ['标题', '链接地址','特点','户型', '面积', '层数', '建造时间', '售价', '每平米单价','楼盘','区域','商圈','地址','出售人']
for i in range(0, len(row0)):
sheet.write(0, i, row0[i])
for i in range(0, len(houses)):
house = houses[i]
# print(house)
for j in range(0, len(house)):
sheet.write(i + 1, j, house[j])
workbook.save(excelPath)
# profile_directory=r'--user-data-dir=C:\Users\User\AppData\Local\Google\Chrome\User Data'
# 主函数
def RunSpider():
data = []
for i in range(1, 30):
print('-----分隔符', i, '-------')
if i == 1:
url = 'https://shenzhen.anjuke.com/sale/?from=navigation'
else:
url = 'https://shenzhen.anjuke.com/sale/p' + str(i) + '/#filtersort'
time.sleep(random.random() * 10)
houses = getHouseList(url)
data.extend(houses)
writeExcel('d:/house.xls', data , i)
time.sleep(random.random() * 10)
_数据读取写入分析代码 _
FliesWR.py
import xlrd
import xlwt
import pandas as pd
import numpy as np
import datamining
########################### 读取指定行,指定列##################################
def read_excel(path, row, column):
workbook = xlrd.open_workbook(r'' + path)
sheet = workbook.sheets()[0]
nrows = sheet.nrows
ncols = sheet.ncols
cache = {}
if row == 0:
for i in range(nrows):
if i == 0:
cache[0] = ''
continue
str = sheet.row_values(i)[column]
cache[i] = str
return cache
if column == 0:
for i in range(ncols):
str = sheet.row_values(row)[i]
cache[i] = str
return cache
########################## 字典查找 ############################################
def select_cols(dict, columnName):
match_data = {}
for (key, value) in dict.items():
if value.startswith(u'' + columnName):
match_data[key] = value
return list(match_data.keys())
def get_rows_value(path, list, columnValue):
key=''
if columnValue==2:
key = '~~'
if columnValue==8:
key = '元'
workbook = xlrd.open_workbook(r'' + path)
sheet = workbook.sheets()[0]
rows_value = []
for i in range(len(list)):
row=list[i]
str = sheet.row_values(row)[columnValue]
s=str.split(key)
rows_value.insert(i,s[0])
return rows_value
_绘图 _
datamining.py
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import FilesWR as fwr
area=['宝安','南山','罗湖','福田','坪山','布吉','龙岗','盐田','大鹏新区','光明','龙华','深圳周边']
def pre_data(columnName):
path = 'D:\house.xls'
dict = fwr.read_excel(path, 0, columnName)
area_data = []
for i in range(len(area)):
result = fwr.get_rows_value(path, fwr.select_cols(dict, area[i]), 8)
cc = list(map(int, result))
area_data.append([area[i]])
mean = np.mean(cc)
#all_mean.insert(i,int(mean/1))
#cache = float(mean / 10000)
#mean_price = '%.2f' % cache
min = np.min(list(map(int, result)))
max = np.max(list(map(int, result)))
area_data[i].append(int(mean))
area_data[i].append(min)
area_data[i].append(max)
return area_data
def data_draw(list):
all_mean = {}
for i in range(len(area)):
all_mean.setdefault(area[i],list[i][1])
print(all_mean)
return all_mean
def draw(y):
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
group_data = list(y.values())
group_names = list(y.keys())
group_mean = np.mean(group_data)
fig, ax = plt.subplots()
ax.barh(group_names, group_data)
ax.axvline(group_mean, ls='--', color='r')
ax.title.set(y=1.05)
for group in range(len(area)):
ax.text(y.get(area[group])+100, group, y.get(area[group]) , fontsize=12,
verticalalignment="center",color='green')
ax.set(xlim=[0, 10000], xlabel='各地区房价均值', ylabel='区域',
title='深圳房价均价区域统计')
ax.set_xticks([0, 10e3 , 20e3 , 30e3 , 40e3, 50e3 , 60e3 , 70e3 ,80e3, 90e3 ,100e3])
plt.show()
if __name__ == '__main__':
#formatter = FuncFormatter(currency)
draw(data_draw(pre_data(10)))


 浙公网安备 33010602011771号
浙公网安备 33010602011771号