据分析pandas完成数据分析项目
【Python有趣打卡】数据分析pandas完成数据分析项目

今天依然是跟着罗罗攀学习数据分析,原创:罗罗攀(公众号:luoluopan1) [ 学习Python有趣|数据分析三板斧
](https://mp.weixin.qq.com/s?__biz=MzIyMjY2MzgyMw&mid=2247484203&idx=1&sn=a345fa5442e7b5675e50e6ac6a85cdb4&chksm=e82b46cbdf5ccfddfc9ef0d04363c2328f9f7e1c8b7ec688d5ad87849da9226cbeb681a00ebe&mpshare=1&scene=1&srcid=&key=5c24ae9a021be1d133d1864e71feaf07342a5c4916f45fffb8fbfd7767267d18313e507b1e26958e026506926e9eb0fdf77117ce8d41e168798f0da54672600e194f24606da3ac1cbf2783581c09f051&ascene=1&uin=MjUyOTY5NTk2Mw&devicetype=Windows%207&version=62060728&lang=zh_CN&pass_ticket=f4bL7YM3QNKfTAcmpcu74eLdh8Q8R9q9pGB2UwDsyMN5JqchYCku1pgybnwojvBF)
。今天是在DD大数据团队实习的第一天,正式开始数据分析之旅,很开心,感觉离自己的梦想又进了一步~
数据源
-
数据来源
[ https://www.kaggle.com/starbucks/store-locations](https://www.kaggle.com/starbucks/store-locations) (数据下载需要注册)
-
定义问题
哪些国家星巴克店铺较多;哪些城市星巴克店铺较多;中国星巴克店铺分布情况 -
读取数据
import numpy as np
import pandas as pd
data = pd.read_csv(r'C:\Users\xuxiaojielucky_i\Desktop\directory.csv')
data.head()
还是使用 jupyter notebook
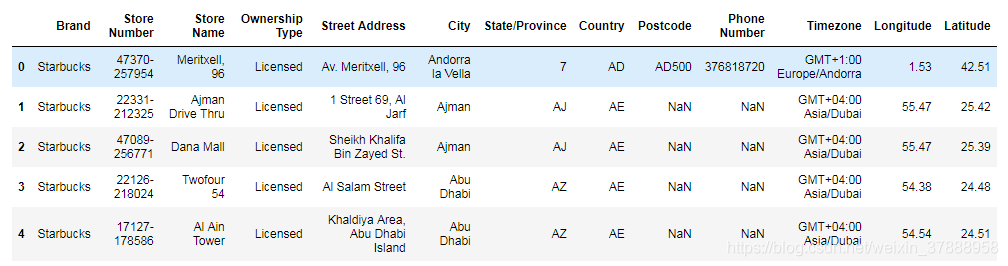
查看数据
- 检查数据
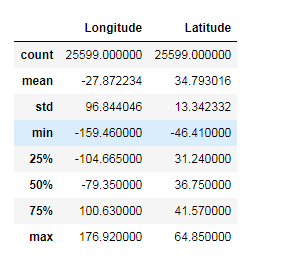
data.describe()
describe函数主要是用来了解数值型数据的分布和概况
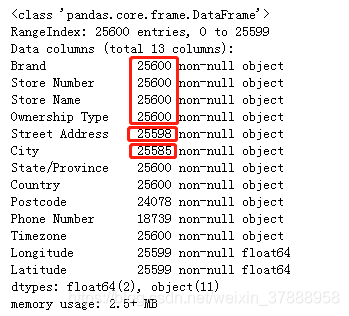
data.info()
info函数主要是用来查看数据的缺失值情况,如针对我们的问题,我们关注的数据主要是地点(国家和城市),这里城市city部分数据缺失。
数据处理
对原始数据进行预处理,包括对数据缺失值处理、异常值处理、重复值处理、多表处理、数据转换处理等,要怎么处理数据要具体问题具体分析。
- 选择数据
首先看下星巴克旗下有哪些品牌吧
data['Brand'].unique()

不研究这么多品牌,我们只看品牌—— ‘Starbucks’
data = data[data['Brand'] == 'Starbucks']
data.head()
- 找出缺失值
data.isnull().sum()
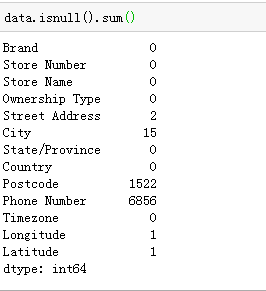
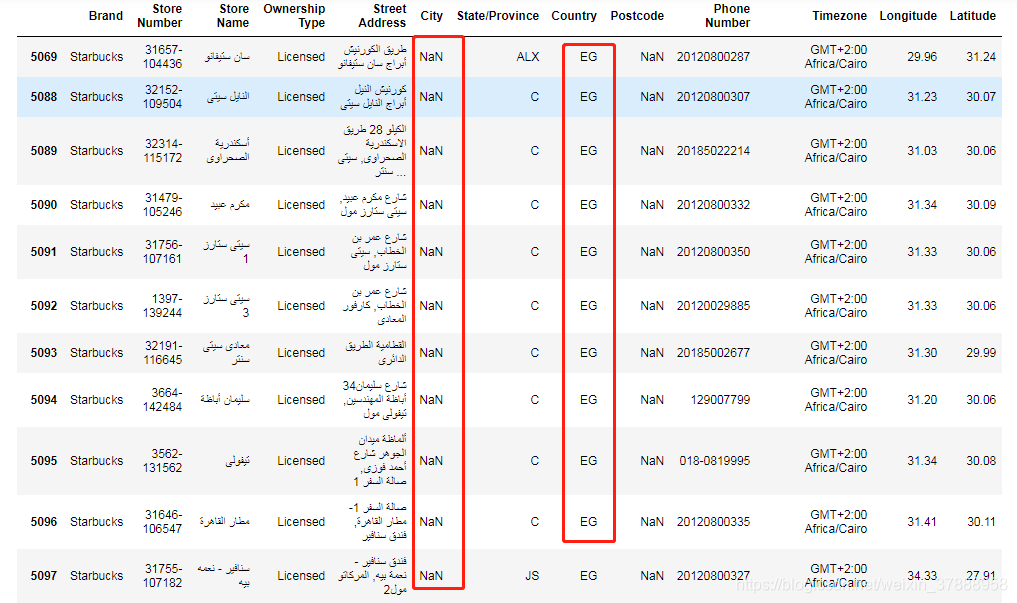
针对我们定义的问题,主要是对City字段进行分析,观察City字段缺失值,都是国家EG的城市有缺失,百度了一下EG,是埃及,好奇的可以深入分析下为啥埃及的城市都缺失了,哈哈哈哈哈
data[data['City'].isnull()]
- 处理缺失值
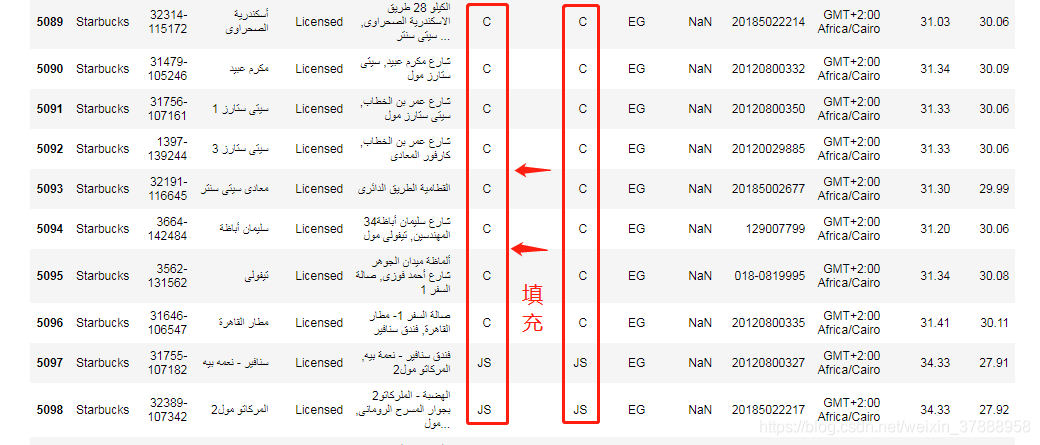
缺失值处理主要有两种方法:1.删除 2.填充
我们这里采用填充的方式,将 State/Province 字段填充在 City 处
data['City'] = data['City'].fillna(data['State/Province'])
data[data['Country']=='EG']
罗老师发现星巴克数据居然把台湾当做了国家,老师表示不能忍,怒改数据,直接重新赋值,换成了中国(中国一点都不能少)。(哈哈哈哈哈罗老师很可爱了)
data['Country'][data['Country']=='TW']= 'CN'
数据分析
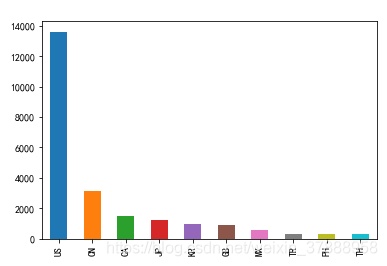
- 查看各个国家星巴克店的数量
(1)统计每个国家星巴克店的数量,并返回数量前十的国家
data['Country'].value_counts()[0:10]

为了让数据更加直观,我们绘制一些图形
由于matplotlib没有中文库,为了放置一些错误出现,可以先进行一些配置
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
%matplotlib inline
country_count.plot(kind = 'bar')
再从城市的维度分析下,哪个城市的星巴克最多
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
%matplotlib inline
city_count.plot(kind = 'barh')
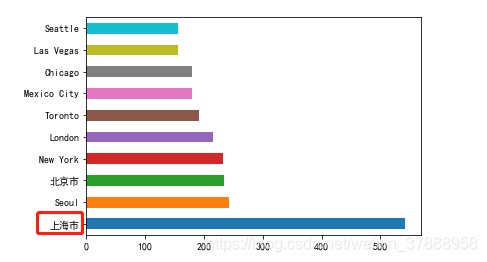
排名最多的居然是上海,不是美国的城市,不分析不知道,一分析吓一跳,中国的市场还是很大的。其实可以继续深挖,这些星巴克店较多的城市有什么共同点,是不是都是经济比较发达的。
下面只分析中国星巴克的分布。
China_data=data[data['Country'] == 'CN']
China_citycount = China_data['City'].value_counts()[0:10]
China_citycount.plot(kind = 'bar')
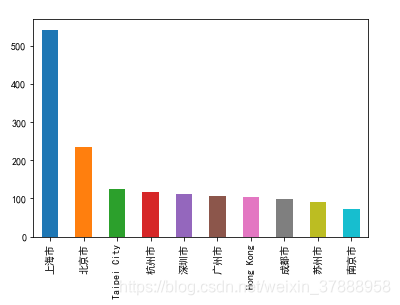
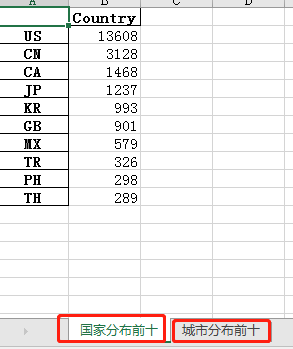
- 导出数据
导出上一篇文章数据处理的数据
country_count.to_excel(r'C:\Users\xuxiaojielucky_i\Desktop\display.xlsx',
sheet_name='国家分布前十')
把多个DataFrame(或者Series)数据导出到同一个excel表格
writer = pd.ExcelWriter(r'C:\Users\xuxiaojielucky_i\Desktop\display.xlsx')
country_count.to_excel(writer,sheet_name='国家分布前十')
city_count.to_excel(writer,sheet_name='城市分布前十')
writer.save()### 这个才可以存储到本地