
中医证型关联规则挖掘
本文是基于《Python数据分析与挖掘实战》的实战部分的第八章的数据——《中医证型关联规则挖掘》做的分析。
旨在补充原文中的细节代码,并给出文中涉及到的内容的完整代码。
主要有:1)将原始数据按照聚类结果进行标记类别
1 背景与目标分析
此项目旨在根据相关数据建模,获取中医证素与乳腺癌TNM分期之间的关系。
2 数据预处理
2.1 数据变换
2.1.1 数据离散化
datafile = 'data.xls'
resultfile = 'data_processed.xlsx'
typelabel = {u'肝气郁结证型系数':'A',u'热毒蕴结证型系数':'B',u'冲任失调证型系数':'C',u'气血两虚证型系数':'D',u'脾胃虚弱证型系数':'E',u'肝肾阴虚证型系数':'F'}
k = 4 #需要进行的聚类类别数
#读取文件进行聚类分析
data = pd.read_excel(datafile)
keys = list(typelabel.keys())
result = DataFrame()
for i in range(len(keys)):
#调用k-means算法 进行聚类
print(u'正在进行%s的聚类' % keys[i])
kmodel = KMeans(n_clusters = k, n_jobs = 4) # n_job是线程数,根据自己电脑本身来调节
kmodel.fit(data[[keys[i]]].as_matrix())# 训练模型
# kmodel.fit(data[[keys[i]]]) # 不转成矩阵形式结果一样
#KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
# n_clusters=4, n_init=10, n_jobs=4, precompute_distances='auto',
# random_state=None, tol=0.0001, verbose=0)
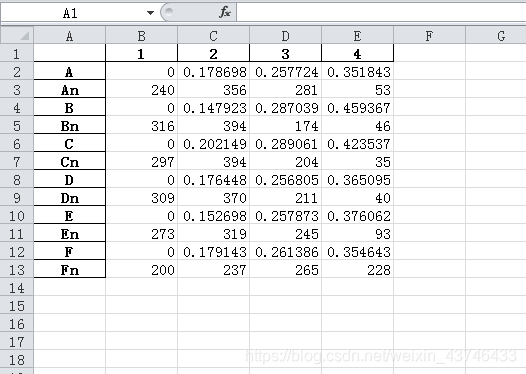
r1 = DataFrame(kmodel.cluster_centers_, columns = [typelabel[keys[i]]]) # 聚类中心
r2 = Series(kmodel.labels_).value_counts() #分类统计
r2 = DataFrame(r2,columns = [typelabel[keys[i]]+'n'])# 转成DataFrame格式,记录各个类别的数目
r = pd.concat([r1,r2], axis=1).sort_values(typelabel[keys[i]])
r.index = range(1,5)
r[typelabel[keys[i]]] = pd.rolling_mean(r[typelabel[keys[i]]],2) # rolling_mean用来计算相邻两列的均值,以此作为边界点
r[typelabel[keys[i]]][1] = 0.0 # 将原来的聚类中心改成边界点
result = result.append(r.T)
result = result.sort_index() # 以index排序,以ABCDEF排序
result.to_excel(resultfile)
print (result)
2.1.2 建模数据集
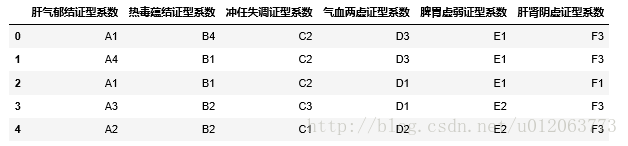
# 将分类后数据进行处理(*****)
data_cut = DataFrame(columns = data.columns[:6])
types = ['A','B','C','D','E','F']
num = ['1','2','3','4']
for i in range(len(data_cut.columns)):
value = list(data.iloc[:,i])
bins = list(result[(2*i):(2*i+1)].values[0])
bins.append(1)
names = [str(x)+str(y) for x in types for y in num]
group_names = names[4*i:4*(i+1)]
cats = pd.cut(value,bins,labels=group_names,right=False)
data_cut.iloc[:,i] = cats
data_cut.to_excel('apriori.xlsx')
data_cut.head()
3.模型建立
inputfile ='apriori.txt' #输入事务集文件
# '''apriori.txt中文件格式如下
# A1,B2,C1,D3,E2,F1,H2
# A2,B2,C1,D2,E2,F1,H3
# A3,B4,C2,D3,E4,F1,H4
# A3,B1,C2,D1,E1,F1,H1
# '''
data2 = pd.read_csv(inputfile, header=None, dtype=object)# 此文件是作者建模时的数据,运行后正常。
start = time.clock() # 计时开始
print(u'\n转换原始数据至0-1矩阵')
ct = lambda x: Series(1, index = x[pd.notnull(x)]) # 将标签数据转换成1,是转换0-1矩阵的过渡函数
b = map(ct, data2.as_matrix())# 用map方式执行
data3 = DataFrame(b).fillna(0)
end = time.time() #计时开始
print (u'转换完毕,用时%s秒' % (end-start))
del b #删除中间变量b 节省内存
support = 0.06 #最小支持度
confidence = 0.75 #最小置信度
ms = '---'# 用来区分不同元素,需要保证原始表格中无该字符
start = time.time() #计时开始
print(u'\n开始搜索关联规则...')
find_rule(data3, support, confidence, ms)
end = time.clock()
print (u'\n搜索完成,用时:%.2f秒' % (end-start))


