

MyCat | 分库分表实践
引言
先给大家介绍2个概念:数据的切分(Sharding)根据其切分规则的类型,可以分为两种切分模式。
切分模式
一种是按照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这种切可以称之为数据的垂直(纵向)切分;另外一种则是根据表中的数据的逻辑关系,将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。
垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低,相互影响很小,业务逻辑非常清晰的系统。在这种系统中,可以很容易做到将不同业务模块所使用的表分拆到不同的数据库中。根据不同的表来进行拆分,对应用程序的影响也更小,拆分规则也会比较简单清晰。
水平切分于垂直切分相比,相对来说稍微复杂一些。因为要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身就较根据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。
为什么用MyCat
不管怎么来说,数据切分虽然分散了单台服务器负载,但是带来了是设计和开发的复杂度。MyCat是一个开源的分布式数据库中间件,实现了MySQL协议的服务器,前端用户可以把它看作是一个数据库代理,用MySQL客户端工具和命令行访问,而其后端可以用MySQL原生协议与多个MySQL服务器通信,在MyCat里,我们面向的是一个传统的数据库表,支持标准的SQL语句进行数据的操作,这样一来,对前端业务系统来说,可以大幅降低开发难度,提升开发速度。
分库分表实践
基本环境
操作系统:CentOS / 7.1 (64bit)
JDK:1.8
MySQL:5.7
MyCat:1.6
业务目标
比如说我们现在有个实际的业务上设计需求,要将student和grade表进行垂直划分,分别存储不同的database中;还需要将student水平拆分,也要3个不同database存分别储。如下图所示,MyCat可以帮助实现这4个database的管理,而对于终端用户来说,就像只操作student和grade两张表,保证了中间件分库分页对程序员的透明性。
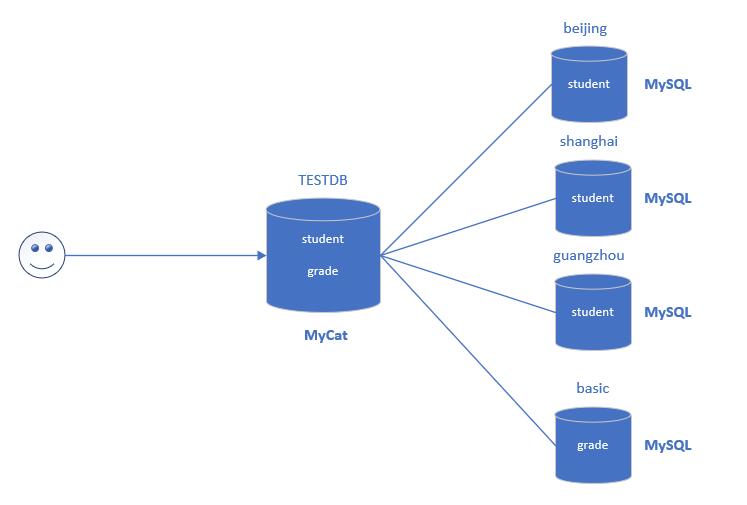
创建实际数据库
首先,我们肯定需要创建4个database:beijing、shanghai、guangzhou、basic,并生成对应的表。可以看出,student和grade表存在于不同的数据库,而且student表中的数据,分散存储在3个不同的数据库中:
create database beijing;
use beijing;
create table student(
id int primary key,
name varchar(8) not null,
grade int not null
);
create database shanghai;
use shanghai;
create table student(
id int primary key,
name varchar(8) not null,
grade int not null
);
create database guangzhou;
use guangzhou;
create table student(
id int primary key,
name varchar(8) not null,
grade int not null
);
create database basic;
use basic;
create table grade(
id int primary key,
name varchar(8) not null
);
安装配置MyCat
比较简单,下载Mycat-1.6-RELEASE,直接解压缩即可。
为了方便,将/mycat/bin目录添加到环境变量:
/etc/profile文件后增加设置export PATH=/data/mycat/bin:$PATH
让profile立即生效:
# source /etc/profile
配置server
编辑\mycat\conf\server.xml:
<user name="test">
<property name="password">test</property>
<property name="schemas">TESTDB</property>
</user>
这里MyCat会帮助我们生成一个虚拟的逻辑database,我们命名为TESTDB,并设置可以访问的用户名和密码,默认访问的端口号8066,其实MyCat还会提供一个管理端口:9066,方便我们对MyCat管理和监测,这个我们以后有机会再说。
配置schema
编辑\mycat\conf\schema.xml:
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<!-- 取模分片 -->
<table name="student" primaryKey="id" dataNode="dn1,dn2,dn3" rule="mod-long" />
<table name="grade" primaryKey="id" dataNode="dn4"/>
</schema>
<!-- 申明节点对应的database -->
<dataNode name="dn1" dataHost="localhost1" database="beijing" />
<dataNode name="dn2" dataHost="localhost1" database="shanghai" />
<dataNode name="dn3" dataHost="localhost1" database="guangzhou" />
<dataNode name="dn4" dataHost="localhost1" database="basic" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- 可读写的数据库实例 -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="******">
</writeHost>
</dataHost>
</mycat:schema>
schema是比较重要的一块配置,主要维护了虚拟库与实际库的映射关系:
可以看到,虚拟的逻辑库TESTDB中维护了2张表student和grade;
grade对应存储在实际的数据库节点dn4,也就是basic;
而student被拆分为存储在3个实际的数据库节点,分别是beijing、shanghai、guangzhou,分片的算法取模,根据取模映射到不同的节点;
最后,我们将实际的访问地址、访问权限配置完成,当然,这里还可以配置主从/读写分离配置,这块不是本文讨论的重点,我们以后单独说。
启动MyCat
这时候,我们敲入命令:# mycat start ,正常的话可以启动MyCat,输入# mycat status,可以查看是否运行正常,如果运行停止,证明启动有误,可以进入控制台启动,# mycat console,进行调试。(有可能报内存错误,一般是由于配置java虚拟机的默认大小的问题,我们可以根据命令行的提示,去wrapper.conf中修改)

MyCat插入和查询
MyCat启动后,我们就可以连接MyCat帮我们生成的逻辑库了:
# mysql -utest -ptest -h127.0.0.1 -P8066 -DTESTDB
接下来,我们在逻辑库中插入一下数据验证一下:
insert into grade (id,name) values (1,'一年级');
insert into grade (id,name) values (2,'二年级');
insert into grade (id,name) values (3,'三年级');
insert into student (id,name,grade) values (1,'张三',2);
insert into student (id,name,grade) values (2,'李四',1);
insert into student (id,name,grade) values (3,'王五',3);
insert into student (id,name,grade) values (4,'甲',3);
insert into student (id,name,grade) values (5,'乙',2);
insert into student (id,name,grade) values (6,'丙',1);
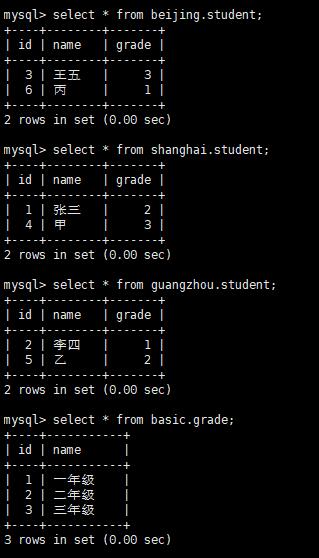
我们插入了6条student记录,这时应该根据不同的取模结果,存在不同的实际数据库的student表中,所以我们切换到实际数据库:# mysql -uroot -ppassword
分别查看实际数据库:
再看此时的逻辑数据库:
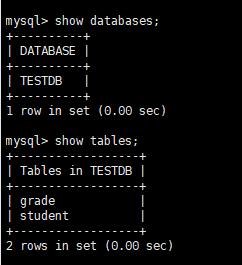
逻辑数据库,查询grade和student两张表,已经数据聚合,还可以进行排序;
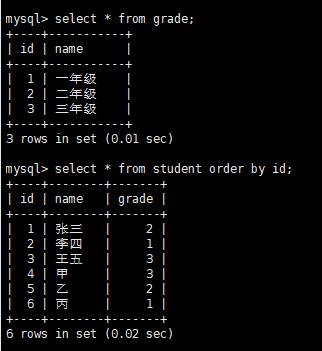
如果我们需要将2张表进行关联,也是可以的:
/*!mycat:catlet=io.mycat.catlets.ShareJoin */select * from student s,grade g on s.grade=g.id where g.name='一年级';

附录


文章作者:原子蛋
文章出处:https://www.cnblogs.com/lizzie-xhu/
个人网站:https://www.lancelot.tech/
微信公众号:原子蛋Live+
扫一扫左侧的二维码(或者长按识别二维码),关注本人微信公共号,获取更多资源。
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

