
计算与软件工程 作业四
| 作业四要求链接 | https://edu.cnblogs.com/campus/jssf/infor_computation17-31/homework/10534 |
|---|---|
| 课程目标 | 实现两人合作结对编程 |
| 此作业在哪个具体方面帮我实现目标 | 两人合作解决具体问题 |
| 其他参考文献 | https://www.cnblogs.com/xinz/archive/2011/08/07/2130332.html |
| 作业正文 | https://i-beta.cnblogs.com/posts/edit |
作业1
评论的链接:
1.https://www.cnblogs.com/zxy123456/p/12449427.html

2.https://www.cnblogs.com/zhou1231/p/12402349.html

3.https://www.cnblogs.com/cdinzz/p/12406077.html

4.https://www.cnblogs.com/limin123/p/12455500.html

5.https://www.cnblogs.com/shixiaomao12138/p/12451805.html

6.https://www.cnblogs.com/sunsijiao/p/12398371.html

7.https://www.cnblogs.com/xinxiyujisuan/p/12461586.html

8.https://www.cnblogs.com/chenyu666/p/12353096.html

评论代码规范结论:代码要具有简明、易读、无二义性的原则。要做到这些,我们需要注意很多细节,例如缩进、行宽、括号、命名、注释等问题。在这些方面做好的话,就会让代码看起来美观,简明,易于读者阅读与理解。代码设计规范不光是程序书写的格式问题,而且牵涉到程序设计、模块之间的关系、设计模式等方方面面。例如,函数、参数处理、如何处理C++中的类等问题。
作业2
要求:两人自由组队进行结对编程
1.实现一个简单而完整的软件工具(中文文本文件人物统计程序):针对小说《红楼梦》要求能分析得出各个人物在每一个章回中各自出现的次数,将这些统计结果能写入到一个csv格式的文件。
2.进行单元测试、回归测试、效能测试,在实现上述程序的过程中使用相关的工具。
3.进行个人软件过程(PSP)的实践,逐步记录自己在每个软件工程环节花费的时间。
4.使用源代码管理系统 (GitHub, Gitee, Coding.net, 等);
5.针对上述形成的软件程序,对于新的文本小说《水浒传》分析各个章节人物出现次数,来考察代码。
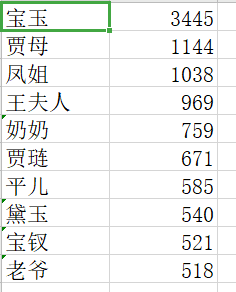
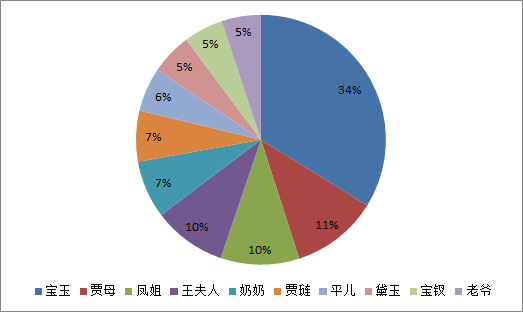
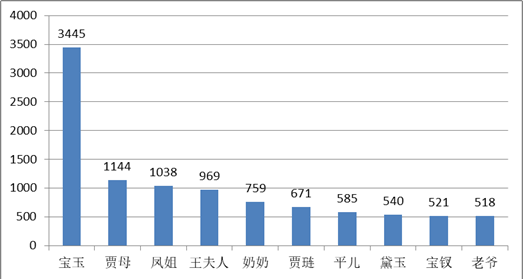
·将上述程序开发结对编程过程记录到新的博客中,尤其是需要通过各种形式展现结对编程过程,并将程序获得的《红楼梦》与《水浒传》各个章节人物出现次数与全本人物出现总次数,通过柱状图、饼图、表格等形式展现。
·《红楼梦》与《水浒传》的文本小说将会发到群里。
注意,要求能够分章节自动获得人物出现次数
程序代码
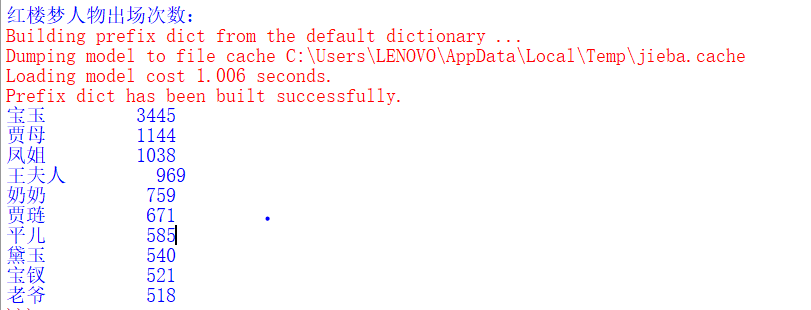
print("红楼梦人物出场次数:")
import jieba #jieba库的应用
excludes = {"什么","一个","我们","那里","你们","如今","说道","知道","起来","姑娘","这里","出来","他们","众人","自己",
"一面","只见","怎么","两个","没有","不是","不知","这个","听见","这样","进来","咱们","告诉","就是","东西",
"袭人","回来","大家","只是","只得","不敢","这些"
}
#列出需要删除的干扰词汇,在多次运行中不断添加来修正
txt = open("D:\红楼梦.txt","r",encoding='utf-8').read()
# 打开txt文件,格式是utf-8
words = jieba.lcut(txt)
#利用jieba库将红楼梦的所有语句分成词汇
counts = {}
#创建的一个空的字典
for word in words:
if len(word) == 1: #删去长度为1的词
continue
elif word == "老太太":
rword = "贾母"
elif word == "太太":
rword = "王夫人"
else:
rword = word
counts[word] = counts.get(word,0) + 1
#如果字典中没有这个名字则创建,如果有就计数加一
for word in excludes:
del counts[word]
#删除干扰词
items = list(counts.items())
#把保存[姓名:个数]的字典转换成列表
items.sort(key=lambda x:x[1],reverse = True)
#对上述列表进行排序,'True'是降序排列
for i in range(10):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))
#输出前十个结果
import jieba
from collections import Counter
import matplotlib.pyplot as plt
import numpy as np
class HlmNameCount():
# 此函数用于绘制条形图
def showNameBar(self,name_list_sort,name_list_count):
# x代表条形数量
x = np.arange(len(name_list_sort))
# 处理中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
# 绘制条形图,bars相当于句柄
bars = plt.bar(x,name_list_count)
# 给各条形打上标签
plt.xticks(x,name_list_sort)
# 显示各条形具体数量
i = 0
for bar in bars:
plt.text((bar.get_x() + bar.get_width() / 2), bar.get_height(), '%d' % name_list_count[i], ha='center', va='bottom')
i += 1
# 显示图形
plt.show()
# 此函数用于绘制饼状图
def showNamePie(self, name_list_sort, name_list_fracs):
# 处理中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei']
# 绘制饼状图
plt.pie(name_list_fracs, labels=name_list_sort, autopct='%1.2f%%', shadow=True)
# 显示图形
plt.show()
def getNameTimesSort(self,name_list,txt_path):
# 将所有人名临时添加到jieba所用字典,以使jieba能识别所有人名
for k in name_list:
jieba.add_word(k)
# 打开并读取txt文件
file_obj = open(txt_path, 'rb').read()
# jieba分词
jieba_cut = jieba.cut(file_obj)
# Counter重新组装以方便读取
book_counter = Counter(jieba_cut)
# 人名列表,因为要处理凤姐所以不直接用name_list
name_dict ={}
# 人名出现的总次数,用于后边计算百分比
name_total_count = 0
for k in name_list:
if k == '熙凤':
# 将熙凤出现的次数合并到凤姐
name_dict['凤姐'] += book_counter[k]
else:
name_dict[k] = book_counter[k]
name_total_count += book_counter[k]
# Counter重新组装以使用most_common排序
name_counter = Counter(name_dict)
# 按出现次数排序后的人名列表
name_list_sort = []
# 按出现次数排序后的人名百分比列表
name_list_fracs = []
# 按出现次数排序后的人名次数列表
name_list_count = []
for k,v in name_counter.most_common():
name_list_sort.append(k)
name_list_fracs.append(round(v/name_total_count,2)*100)
name_list_count.append(v)
# print(k+':'+str(v))
# 绘制条形图
self.showNameBar(name_list_sort, name_list_count)
# 绘制饼状图
self.showNamePie(name_list_sort,name_list_fracs)
if __name__ == '__main__':
# 参与统计的人名列表
name_list = ['宝玉, '贾母', '凤姐', '王夫人', '奶奶', '贾琏', '平儿', '黛玉', '宝钗', '老爷' ]
# 红楼梦txt文件所在路径
txt_path = 'D:\红楼梦.txt'
hnc = HlmNameCount()
hnc.getNameTimesSort(name_list,txt_path)
运行截图
CSV列表:
单元测试代码
红楼梦测试代码
import unittest
from red2 import *
class MyTestCase(unittest.TestCase):
def setUp(self):
print("测试开始")
def test_something(self):
name_list = ['宝玉, '贾母', '凤姐', '王夫人', '奶奶', '贾琏', '平儿', '黛玉', '宝钗', '老爷' ]
txt_path = 'redstone.txt'
name_list_count = [3445, 1144, 1038, 969, 759, 671, 585, 540, 521, 518]
items = list()
for i in range(12):
items.append([name_list[i], name_list_count[i]])
self.assertEqual(items, NameCount().getNameTimesSort(name_list,txt_path))
def tearDown(self):
print("测试结束")
if __name__ == '__main__':
unittest.main()
总结
1、目前对于软件的认识尚浅,很多编程语言运用并不熟练。相对来说,个人认为Java相对c语言简单。希望在今后的学习中,能够尽量补缺自己的短板。增加就业优势。学习了Python的应用,目前掌握的软件运用技巧尚浅,还需多加锻炼,达到一定的程度。由于掌握的知识有限,未能将每个章节的人物出现次数统计出来。
2、在代码运行过程遇到很多问题:
(1)未安装jieba库,通过查找资料,成功安装jieba库

(2)由于我们的代码运行结果以柱状图和饼图形式呈现,所以Python需要可视化库Matplotlib
码云链接:https://gitee.com/if_evening/hlm

