

Python自学整理
Python对大小写敏感。
在 Windows 下可以不写第一行注释:
#!/usr/bin/python3
第一行注释标的是指向 python 的路径,告诉操作系统执行这个脚本的时候,调用 /usr/bin 下的 python 解释器。
此外还有以下形式(推荐写法):
#!/usr/bin/env python3
这种用法先在 env(环境变量)设置里查找 python 的安装路径,再调用对应路径下的解释器程序完成操作
函数帮助:
# 如下两种方法实例,查看 max 内置函数的参数列表和规范的文档
>>> help(max)
……显示帮助信息……
>>> max?
Python介绍
Python是一种解释性语⾔。Python语⾔的⼀个重要特性就是它的对象模型的⼀致性。每个数字、字符串、数据结构、函数、类、模块等等,都是在Python解释器的自有“盒⼦”内,它被认为是Python对象。每个对象都有类型(例如,字符串或函数)和内部数据。在实际中,这可以让语言⾮常灵活,因为函数也可以被当做对象使⽤。
下载包package
若想安装不在Anaconda中的 Python包,通常可以⽤以下命令安装:
conda install package_name
如果这个命令不⾏,也可以⽤pip包管理⼯具:
pip install package_name
你可以⽤conda update命令升级包:
conda update package_name
pip可以⽤--upgrade升级:
pip install --upgrade package_name
查看版本
import matplotlib.pyplot as plt
import pandas as pd #导入pandas的常规做法
import sys #导入sys库只是为了确认一下Python的版本
import matplotlib #这样导入matplotlib只是为了显示一下其版本号
print('Python version ' + sys.version) #查看python版本
print('Pandas version ' + pd.__version__) #查看pandas版本
print('Matplotlib version ' + matplotlib.__version__)
import 用法
关于 import 的小结,以 time 模块为例:
1、将整个模块导入,例如:import time,在引用时格式为:time.sleep(1)。
2、将整个模块中全部函数导入,例如:from time import *,在引用时格式为:sleep(1)。
3、将模块中特定函数导入,例如:from time import sleep,在引用时格式为:sleep(1)。
4、将模块换个别名,例如:import time as abc,在引用时格式为:abc.sleep(1)。
5、从某个模块中导入多个函数,格式为: from somemodule import firstfunc, secondfunc, thirdfunc
import 模块和from 模块 import *;两种写法的区别是第二种调用函数时不需要模块前缀
Python在linux下的使用
进入与退出
进入Python交互模式,提示符是>>>
[ch@bdos02 ~]$ python
>>>
在Python交互模式下输入exit()并回车,就退出了Python交互模式。
>>> exit()
在Python交互式模式下,可以直接输入代码,然后执行,并立刻得到结果。
在命令行模式下,可以直接运行.py文件。
运行python脚本
#脚本文件命名.py,给最高权限777,执行方法:
[root@club pyy]# python t.py
[root@club pyy]# ./test.py (开头不加解释器说明会报语法错误 #!/usr/bin/env python )
#后台执行python脚本
[root@club pyy]# nohup python test.py> test.log &
数据类型和变量
Python 中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
在 Python 中,变量就是变量,它没有类型,我们所说的"类型"是变量所指的内存中对象的类型。
等号(=)用来给变量赋值,变量名区分大小写。
等号(=)运算符左边是一个变量名,等号(=)运算符右边是存储在变量中的值。
#!/usr/bin/python3
counter = 100 # 整型变量
miles = 1000.0 # 浮点型变量
name = "runoob" # 字符串
Python3 的六个标准数据类型中:
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
- 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
常用的数据类型有:整型(int)、浮点型(Float)、字符串(string)
数字(Number)
python中数字有四种类型:整数、布尔型、浮点数和复数。
|
int |
整数 |
如1,只有一种整数类型int,表示为长整型,没有python2中的Long。 |
|
bool |
布尔 |
如True。 |
|
Float |
浮点数 |
如1.23、2.0 |
|
complex |
复数 |
如1+2j、1.1+2.2j |
不同类型的数混合运算时会将整数转换为浮点数:>>> 3 * 3.75 / 1.5
字符串(string)
- python中单引号和双引号使用完全相同。
- 使用三引号('''或""")可以指定一个多行字符串。
- 转义符 '\'。比如\n表示换行,\t表示制表符,字符\本身也要转义,所以\\表示的字符就是\;
- 反斜杠可以用来转义,使用r可以让反斜杠不发生转义。如 r"this is a line with \n" 则\n会显示,并不是换行。
- 按字面意义级联字符串,如"this " "is " "string"会被自动转换为this is string。
- 字符串可以用 + 运算符连接在一起,用 * 运算符重复。
- Python 中的字符串有两种索引方式,从左往右以 0 开始,从右往左以 -1 开始。
- Python中的字符串不能改变。
- Python 没有单独的字符类型,一个字符就是长度为 1 的字符串。
- 字符串的截取的语法格式如下:变量[头下标:尾下标:步长]
实例(Python 3.0+)
#!/usr/bin/python3
str='Runoob'
print(str) # 输出字符串
print(str[0:-1]) # 输出第一个到倒数第二个的所有字符
print(str[0]) # 输出字符串第一个字符
print(str[2:5]) # 输出从第三个开始到第五个的字符
print(str[2:]) # 输出从第三个开始后的所有字符
print(str[1:5:2]) # 输出从第二个开始到第五个且每隔两个的字符
print(str * 2) # 输出字符串两次
print(str + '你好') # 连接字符串
print('------------------------------')
print('hello\nrunoob') # 使用反斜杠(\)+n转义特殊字符
print(r'hello\nrunoob') # 在字符串前面添加r,表示原始字符串,不会发生转义
Python 的字符串内建函数:https://www.runoob.com/python3/python3-string.html
List[列表]
列表中元素的类型可以不相同,它支持数字,字符串甚至可以包含列表(所谓嵌套)。
列表是写在方括号 [] 之间、用逗号分隔开的元素列表。
和字符串一样,列表同样可以被索引和截取,列表被截取后返回一个包含所需元素的新列表。
列表截取的语法格式如下:
变量[头下标:尾下标:步长(默认1,可省略)]
实例:
#!/usr/bin/python3
list = [ 'abcd', 786 , 2.23, 'runoob', 70.2 ]
tinylist = [123, 'runoob']
print (list) # 输出完整列表
print (list[0]) # 输出列表第一个元素
print (list[1:3]) # 从第二个开始输出到第三个元素
print (list[2:]) # 输出从第三个元素开始的所有元素
print (tinylist * 2) # 输出两次列表
print (list + tinylist) # 连接列表
与Python字符串不一样的是,列表中的元素是可以改变的:
a = [1, 2, 3, 4, 5, 6]
a[2:5] = [] # 将对应的元素值设置为 []
列表推导式书写形式:
[表达式 for 变量 in 列表]
或者
[表达式 for 变量 in 列表 if 条件]
[表达式]:最后执行的结果
[for变量 in 列表]:这个可以是一个多层循环
[if 条件]:两个for间是不能有判断语句的,判断语句只能在最后;顺序不定,默认是左到右。
li = [1,2,3,4,5,6,7,8,9]
print ([x**2 for x in li])
print ([x**2 for x in li if x>5])
清空列表中的多项空值:
test = ['a','','b','','c','','']
test = [i for i in test if i != '']
print(test)
输出结果为:
['a', 'b', 'c']
Python列表包含以下函数:
|
序号 |
函数 |
|
1 |
len(list) 列表元素个数 |
|
2 |
max(list) 返回列表元素最大值 |
|
3 |
min(list) 返回列表元素最小值 |
|
4 |
list(seq) 将元组转换为列表 |
|
5 |
cmp(list1, list2) 比较两个列表的元素 |
Python列表包含以下方法:
|
方法 |
描述 |
|
list.append(x) |
把一个元素添加到列表的结尾,相当于 a[len(a):] = [x]。 |
|
list.extend(L) |
用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表),相当于 a[len(a):] = L。 |
|
list.insert(i, x) |
在指定位置插入一个元素。第一个参数是准备插入到其前面的那个元素的索引,例如 a.insert(0, x) 会插入到整个列表之前,而 a.insert(len(a), x) 相当于 a.append(x) 。 |
|
list.remove(x) |
删除列表中值为 x 的第一个元素。如果没有这样的元素,就会返回一个错误。 |
|
list.pop([i]) |
从列表的指定位置移除元素,并将其返回。如果没有指定索引,a.pop()返回最后一个元素。元素随即从列表中被移除。(方法中 i 两边的方括号表示这个参数是可选的,而不是要求你输入一对方括号,你会经常在 Python 库参考手册中遇到这样的标记。) |
|
list.clear() |
移除列表中的所有项,等于del a[:]。 |
|
list.index(x) |
返回列表中第一个值为 x 的元素的索引。如果没有匹配的元素就会返回一个错误。 |
|
list.count(x) |
返回 x 在列表中出现的次数。 |
|
list.sort() |
对列表中的元素进行排序。 |
|
list.reverse() |
倒排列表中的元素。 |
|
list.copy() |
返回列表的浅复制,等于a[:]。 |
遍历嵌套的列表:
num_list = [[1,2,3],[4,5,6]]
for i in num_list:
for j in i:
print(j)
输出结果:
1
2
3
4
5
6
Tuple(元组)
元组写在小括号 () 里,元素之间用逗号隔开。
虽然tuple的元素不可改变,但它可以包含可变的对象,元组可以包含多种类型的数据,比如list列表。
string、list 和 tuple 都属于 sequence(序列)。
注意:
1、与字符串一样,元组的元素不能修改。
>>> tuple[0] = 11 # 修改元组元素的操作是非法的
2、元组与列表类似也可以被索引和切片,方法一样。
3、注意构造包含 0 或 1 个元素的元组的特殊语法规则。
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
4、元组也可以使用+操作符进行拼接。
元组内置函数
Python元组包含了以下内置函数
|
序号 |
方法及描述 |
|
1 |
cmp(tuple1, tuple2) 比较两个元组元素。 |
|
2 |
len(tuple) 计算元组元素个数。 |
|
3 |
max(tuple) 返回元组中元素最大值。 |
|
4 |
min(tuple) 返回元组中元素最小值。 |
|
5 |
tuple(seq) 将列表转换为元组。 |
Dictionary{字典}
字典是一种映射类型,字典用 { } 标识,它是一个无序的键(key) : 值(value)集合。
字典是无序的对象集合,列表是有序的对象集合。字典于列表的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
1、字典是一种映射类型,它的元素是键值对。
2、字典的键必须为不可变类型,且不能重复。
3、创建空字典使用 { }。
4、字典列表,即在列表中嵌套字典
字典推导式:{key:value for variable in iterable [if expression]}
如调换k,v值:
reverse = {v: k for k, v in dic.items()}
print(reverse)
字典内置函数&方法
Python字典包含了以下内置函数:
|
序号 |
函数及描述 |
|
1 |
cmp(dict1, dict2) 比较两个字典元素。 |
|
2 |
len(dict) 计算字典元素个数,即键的总数。 |
|
3 |
str(dict) 输出字典可打印的字符串表示。 |
|
4 |
type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 |
Python字典包含了以下内置方法:
|
序号 |
函数及描述 |
|
1 |
dict.clear() 删除字典内所有元素 |
|
2 |
dict.copy() 返回一个字典的浅复制 |
|
3 |
dict.fromkeys(seq[, val]) |
|
4 |
dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值 |
|
5 |
dict.has_key(key) 如果键在字典dict里返回true,否则返回false |
|
6 |
dict.items() 以列表返回可遍历的(键, 值) 元组数组 |
|
7 |
dict.keys() 以列表返回一个字典所有的键 |
|
8 |
dict.values() 以列表返回字典中的所有值 |
|
9 |
dict.setdefault(key, default=None) |
|
10 |
dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
|
11 |
pop(key[,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。 |
|
12 |
popitem() 返回并删除字典中的最后一对键和值。 |
#!/usr/bin/python3
dict = {}
dict['one'] = "1 - 菜鸟教程"
dict[2] = "2 - 菜鸟工具"
tinydict = {'name': 'runoob','code':1, 'site': 'www.runoob.com'}
print (dict['one']) # 输出键为 'one' 的值
print (dict[2]) # 输出键为 2 的值
print (tinydict) # 输出完整的字典
print (tinydict.keys()) # 输出所有键
print (tinydict.values()) # 输出所有值
print (tinydict.items()) # 输出所有键值对
构造函数 dict() 可以直接从键值对序列中构建字典如下:
>>> dict([('Runoob', 1), ('Google', 2), ('Taobao', 3)])
{'Runoob': 1, 'Google': 2, 'Taobao': 3}
>>> dict(Runoob=1, Google=2, Taobao=3)
{'Runoob': 1, 'Google': 2, 'Taobao': 3}
# dict(d),d不一定必须为一个序列元组:
>>> dict_1 = dict([('a',1),('b',2),('c',3)]) #元素为元组的列表
>>> dict_1
{'a': 1, 'b': 2, 'c': 3}
>>> dict_2 = dict({('a',1),('b',2),('c',3)})#元素为元组的集合
>>> dict_2
{'b': 2, 'c': 3, 'a': 1}
>>> dict_3 = dict([['a',1],['b',2],['c',3]])#元素为列表的列表
>>> dict_3
{'a': 1, 'b': 2, 'c': 3}
>>> dict_4 = dict((('a',1),('b',2),('c',3)))#元素为元组的元组
>>> dict_4
{'a': 1, 'b': 2, 'c': 3}
字典是支持无限极嵌套的,如下面代码:
cities={
'北京':{
'朝阳':['国贸','CBD','天阶','我爱我家','链接地产'],
'海淀':['圆明园','苏州街','中关村','北京大学'],
'昌平':['沙河','南口','小汤山',],
'怀柔':['桃花','梅花','大山'],
'密云':['密云A','密云B','密云C']
},
'河北':{
'石家庄':['石家庄A','石家庄B','石家庄C','石家庄D','石家庄E'],
'张家口':['张家口A','张家口B','张家口C'],
'承德':['承德A','承德B','承德C','承德D']
}
}
for i in cities['北京']:
print(i)
将列出如下结果:可是为什么呢?
朝阳
海淀
昌平
怀柔
密云
for i in cities['北京']['海淀']:
print(i)
输出如下结果:
圆明园
苏州街
中关村
北京大学
补充:
空值
空值是Python里一个特殊的值,用None表示。None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
常量
注意:
1、Python可以同时为多个变量赋值,如a, b = 1, 2。
2、一个变量可以通过赋值指向不同类型的对象。
3、数值的除法包含两个运算符:/ 返回一个浮点数,// 返回一个整数。
4、在混合计算时,Python会把整型转换成为浮点数。
Set{集合}
集合是⽆序的不可重复的元素的集合,可以把它当做字典,但是只有键没有值。
可以⽤两种⽅式创建集合:通过set函数或使⽤尖括号set语句:
set([2, 2, 2, 1, 3, 3])
{1, 2, 3}
集合基本功能是进行元素关系测试和删除重复元素。可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
实例:
#!/usr/bin/python3
sites = {'Google', 'Taobao', 'Runoob', 'Facebook', 'Zhihu', 'Baidu'}
print(sites) # 输出集合,重复的元素被自动去掉
# 成员测试
if 'Runoob' in sites :
print('Runoob 在集合中')
else :
print('Runoob 不在集合中')
# set可以进行集合运算
a = set('abracadabra')
b = set('alacazam')
print(a)
print(a - b) # a 和 b 的差集
print(a | b) # a 和 b 的并集
print(a & b) # a 和 b 的交集
print(a ^ b) # a 和 b 中不同时存在的元素
以上实例输出结果:
{'Zhihu', 'Baidu', 'Taobao', 'Runoob', 'Google', 'Facebook'}
Runoob 在集合中
{'b', 'c', 'a', 'r', 'd'}
{'r', 'b', 'd'}
{'b', 'c', 'a', 'z', 'm', 'r', 'l', 'd'}
{'c', 'a'}
{'z', 'b', 'm', 'r', 'l', 'd'}
集合内置方法完整列表:https://www.runoob.com/python3/python3-set.html
可变和不可变数据类型
可变数据类型:指其值可以直接修改、删除和添加;不可变数据类型则相反。
- 字符串是不可变数据类型,改变字符串的正确方式是使用切片和连接构造新的变量,直接修改会报错TypeError
- 列表[]是可变数据类型
- 元祖是列表数据类型的不可变形式,是不可改变数据类型,使用(),而不是[]
#列表举例
name=[1,2,3]
name[1]=10 #直接修改
print(name) #返回[1, 10, 3]
#元祖举例
egg=('a', 'b', 'c', 'd', 12, 13.0) #元组可以包含多种类型的数据
type(('hello',)) #只有一个值时最后加个逗号表明是元组
type(('hello'))
python数据类型转换
对数据内置的类型进行转换,你只需要将数据类型作为函数名即可。
以下几个内置的函数可以执行数据类型之间的转换。这些函数返回一个新的对象,表示转换的值。
|
函数 |
描述 |
|
int(x) |
将x转换为一个整数 |
|
将x转换到一个浮点数 |
|
|
创建一个复数 |
|
|
将对象 x 转换为字符串 |
|
|
将对象 x 转换为表达式字符串 |
|
|
用来计算在字符串中的有效Python表达式,并返回一个对象 |
|
|
将序列 s 转换为一个元组 |
|
|
将序列 s 转换为一个列表 |
|
|
转换为可变集合 |
|
|
创建一个字典。 |
|
|
转换为不可变集合 |
|
|
将一个整数转换为一个字符 |
|
|
将一个字符转换为它的整数值 |
Python3 运算符
算术运算符
以下假设变量a为10,变量b为21:
|
运算符 |
描述 |
实例 |
|
+ |
加 - 两个对象相加 Ps:加号还可以用于连接两个字符串:print('a'+'b') Ps:加号还可以用于两个数字相加:print(2.3+2.1) 但不能让数字+字符串:print(2.3+'a'),错误写法 连接数字+字符串正确写法:print(str(2.3)+'a') |
a + b 输出结果 31 |
|
- |
减 - 得到负数或是一个数减去另一个数 |
a - b 输出结果 -11 |
|
* |
乘 - 两个数相乘或是返回一个被重复若干次的字符串 *用于字符串和数字n之间表示复制字符串n次:print('a'*5) |
a * b 输出结果 210 |
|
/ |
除 - x 除以 y |
b / a 输出结果 2.1 |
|
% |
取模 - 返回除法的余数 |
b % a 输出结果 1 |
|
** |
幂 - 返回x的y次幂 |
a**b 为10的21次方 |
|
// |
取整除 - 向下取接近商的整数 |
>>> 9//2 4 >>> -9//2 -5 |
比较运算符
以下假设变量a为10,变量b为20:
|
运算符 |
描述 |
实例 |
|
== |
等于 - 比较对象是否相等 |
(a == b) 返回 False。 |
|
!= |
不等于 - 比较两个对象是否不相等 |
(a != b) 返回 True。 |
|
> |
大于 - 返回x是否大于y |
(a > b) 返回 False。 |
|
< |
小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。注意,变量大写。 |
(a < b) 返回 True。 |
|
>= |
大于等于 - 返回x是否大于等于y。 |
(a >= b) 返回 False。 |
|
<= |
小于等于 - 返回x是否小于等于y。 |
(a <= b) 返回 True。 |
赋值运算符
以下假设变量a为10,变量b为20:
|
运算符 |
描述 |
实例 |
|
= |
简单的赋值运算符 |
c = a + b 将 a + b 的运算结果赋值为 c |
|
+= |
加法赋值运算符 |
c += a 等效于 c = c + a |
|
-= |
减法赋值运算符 |
c -= a 等效于 c = c - a |
|
*= |
乘法赋值运算符 |
c *= a 等效于 c = c * a |
|
/= |
除法赋值运算符 |
c /= a 等效于 c = c / a |
|
%= |
取模赋值运算符 |
c %= a 等效于 c = c % a |
|
**= |
幂赋值运算符 |
c **= a 等效于 c = c ** a |
|
//= |
取整除赋值运算符 |
c //= a 等效于 c = c // a |
|
:= |
海象运算符,可在表达式内部为变量赋值。Python3.8 版本新增运算符。 |
在这个示例中,赋值表达式可以避免调用 len() 两次: if (n := len(a)) > 10: print(f"List is too long ({n} elements, expected <= 10)") |
逻辑运算符not/and/or
优先级:()>not>and>or
以下假设变量 a 为 10, b为 20:
|
运算符 |
逻辑表达式 |
描述 |
实例 |
|
and |
x and y |
布尔"与" - 如果 x 为 False,x and y 返回 x 的值,否则返回 y 的计算值。 |
(a and b) 返回 20。 |
|
or |
x or y |
布尔"或" - 如果 x 是 True,它返回 x 的值,否则它返回 y 的计算值。 |
(a or b) 返回 10。 |
|
not |
not x |
布尔"非" - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True。 |
not(a and b) 返回 False |
In/not in运算符
|
运算符 |
描述 |
实例 |
|
in |
如果在指定的序列中找到值返回 True,否则返回 False。 |
x 在 y 序列中 , 如果 x 在 y 序列中返回 True。 |
|
not in |
如果在指定的序列中没有找到值返回 True,否则返回 False。 |
x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True。 |
Is/is not运算符
身份运算符用于比较两个对象的存储单元
|
运算符 |
描述 |
实例 |
|
is |
is 是判断两个标识符是不是引用自一个对象 |
x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
|
is not |
is not 是判断两个标识符是不是引用自不同对象 |
x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
注: id() 函数用于获取对象内存地址。
is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个, == 用于判断引用变量的值是否相等。
Python运算符优先级:https://www.runoob.com/python3/python3-basic-operators.html#ysf1
时间与日期转换
|
符号 |
含义 |
|
%y |
两位数的年份表示(00-99) |
|
%Y |
四位数的年份表示(000-9999) |
|
%m |
月份(01-12) |
|
%d |
月内中的一天(0-31) |
|
%H |
24小时制小时数(0-23) |
|
%I |
12小时制小时数(01-12) |
|
%M |
分钟数(00-59) |
|
%S |
秒(00-59) |
|
%a |
本地简化星期名称 |
|
%A |
本地完整星期名称 |
|
%b |
本地简化的月份名称 |
|
%B |
本地完整的月份名称 |
|
%c |
本地相应的日期表示和时间表示 |
|
%j |
年内的一天(001-366) |
|
%p |
本地A.M.或P.M.的等价符 |
|
%U |
一年中的星期数(00-53)星期天为星期的开始 |
|
%w |
星期(0-6),星期天为星期的开始 |
|
%W |
一年中的星期数(00-53)星期一为星期的开始 |
|
%x |
本地相应的日期表示 |
|
%X |
本地相应的时间表示 |
|
%Z |
当前时区的名称 |
|
%% |
%号本身 |
Time 模块包含了以下内置函数,既有时间处理的,也有转换时间格式的:
|
1 |
time.localtime([secs]) |
|
2 |
time.time( ) 返回当前时间的时间戳(1970纪元后经过的浮点秒数)。 |
|
3 |
time.strftime(fmt[,tupletime]) |
我们可以使用 time 模块的 strftime 方法来格式化日期,:
time.strftime(format[, t])
#!/usr/bin/python
import time
# 格式化成2021-01-15 14:11:37形式
print time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
控制流
D:\personal_file\python\code\ python编程快速上手.py 控制流章节
函数
更多见:D:\personal_file\python\code\ python编程快速上手.py 第3章:函数章节
语法
#!/usr/bin/python
def functionname( parameters ):
函数体
[return [expression]] #用def创建函数时,可以用return指定返回什么值
#如果函数没有return语句(或者只有return本身),其返回值为None
参数
以下是调用函数时可使用的正式参数类型:
- 必备参数
- 关键字参数
- 默认参数
- 不定长参数
必备参数:
#!/usr/bin/python
#可写函数说明
def printme(name):
print('hello '+name)
return
#调用printme函数
pyy= 'pengyuanyuan'
printme(pyy) #实际调用时一般传入的是内容或者任意变量名,不一定命名为name
关键字参数:
关键字参数顺序不重要(传递多个参数):
#!/usr/bin/python
#可写函数说明
def printinfo(name,age):
print("Name:", name)
print("Age", age)
return
#调用printinfo函数
printinfo( age=50, name="miki" )
不定长参数
你可能需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述2种参数不同,声明时不会命名。基本语法如下:
#!/usr/bin/python
def functionname([formal_args,] *var_args_tuple ):
"函数_文档字符串"
function_suite
return [expression]
加了星号(*)的变量名会存放所有未命名的变量参数。不定长参数实例如下:
#!/usr/bin/python
# 可写函数说明
def printinfo( arg1, *vartuple ):
"打印任何传入的参数"
print "输出: "
print arg1
for var in vartuple:
print var
return
# 调用printinfo 函数
printinfo( 10 )
printinfo( 70, 60, 50 )
导入模块
#导入整个模块
import module1[, module2[,... moduleN]]
#导入模块的部分函数
from modname import name1[, name2[, ... nameN]]
#导入一个模块中的所有项目
from modname import *
文件I/O
读取键盘输入
Python提供了两个内置函数从标准输入读入一行文本,默认的标准输入是键盘。如下:
- raw_input
- input
raw_input函数
raw_input([prompt]) 函数从标准输入读取一个行,并返回一个字符串(去掉结尾的换行符):
str = raw_input("请输入:")
print "你输入的内容是: ", str
input函数
input([prompt]) 函数和 raw_input([prompt]) 函数基本类似,但是 input 可以接收一个Python表达式作为输入,并将运算结果返回。
这会产生如下的对应着输入的结果:
请输入:[x*5 for x in range(2,10,2)]
你输入的内容是: [10, 20, 30, 40]
open 函数
你必须先用Python内置的open()函数打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。完整的语法格式为:
file object =open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
mode:
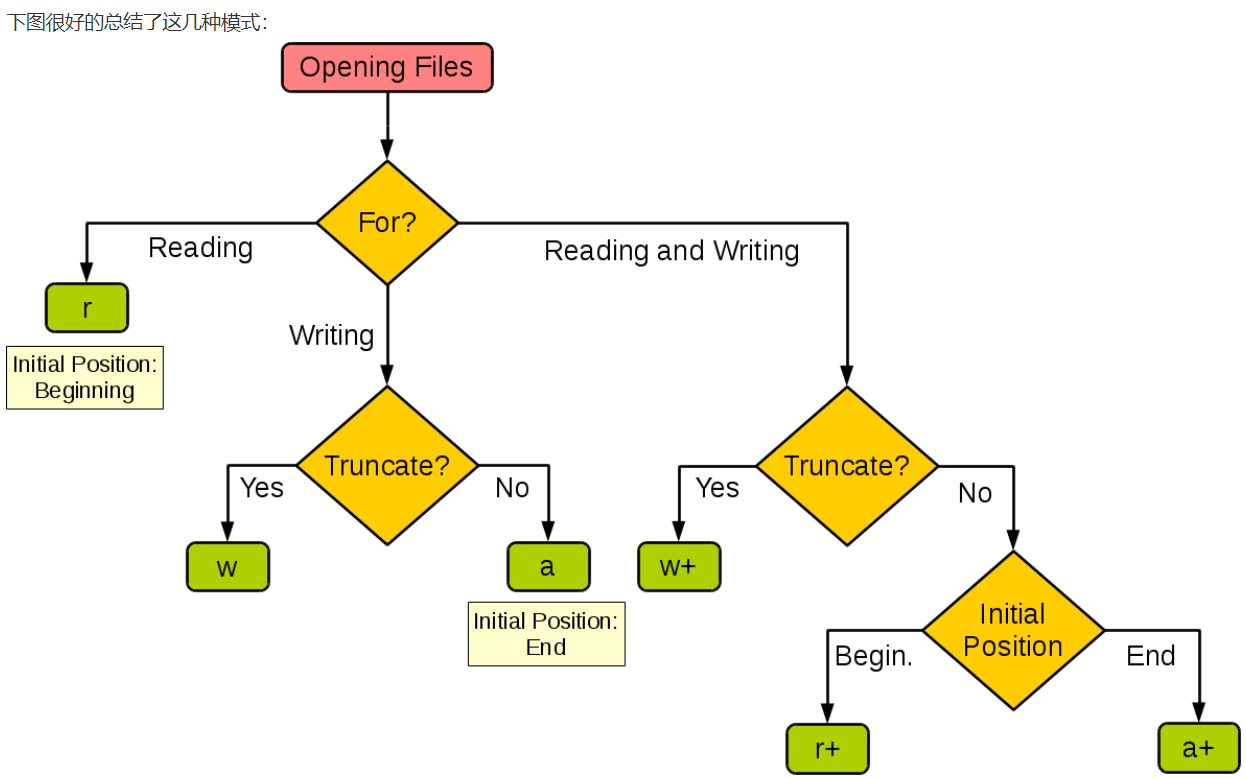
File对象的属性
一个文件被打开后,你有一个file对象,你可以得到有关该文件的各种信息。
以下是和file对象相关的所有属性的列表:
|
属性 |
描述 |
|
file.closed |
返回true如果文件已被关闭,否则返回false。 |
|
file.mode |
返回被打开文件的访问模式。 |
|
file.name |
返回文件的名称。 |
|
file.softspace |
如果用print输出后,必须跟一个空格符,则返回false。否则返回true。 |
# 打开一个文件
fo = open("foo.txt", "w")
# 关闭打开的文件
fo.close()
一些函数
apply
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)
1.该函数最有用的是第一个参数,这个参数是函数.
apply(func [, args [, kwargs ]]) 函数用于当函数参数已经存在于一个元组或字典中时,间接地调用函数。args是一个包含将要提供给函数的按位置传递的参数的元组。如果省略了args,任何参数都不会被传递,kwargs是一个包含关键字参数的字典。简单说apply()的返回值就是func()的返回值,apply()的元素参数是有序的,元素的顺序必须和func()形式参数的顺序一致,与map的区别是前者针对column,后者针对元素
lambda匿名函数
lambda是匿名函数,即不再使用def的形式,可以简化脚本,使结构不冗余何简洁。匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
通过对比可以看出,匿名函数lambda x: x * x实际上就是:
def f(x):
return x * x
用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数:
f = lambda x: x * x
f(5)
apply和lambda两者结合可以做很多事情,比如split在series里很多功能不可用,而index就可以做
transform()方法
transform() 里面不能跟自定义的特征交互函数,因为transform是针对每一元素(即每一列特征操作)进行计算,也就是说在使用 transform() 方法时,需要记得三点:
1、它只能对每一列进行计算,所以在groupby()之后,.transform()之前是要指定要操作的列,这点也与apply有很大的不同。
2、由于是只能对每一列计算,所以方法的通用性相比apply()就局限了很多,例如只能求列的最大/最小/均值/方差/分箱等操作
3、transform还有什么用呢?最简单的情况是试图将函数的结果分配回原始的dataframe。也就是说返回的shape是(len(df),1)。注:如果与groupby()方法联合使用,需要对值进行去重
https://www.cnblogs.com/wkang/p/9794678.html
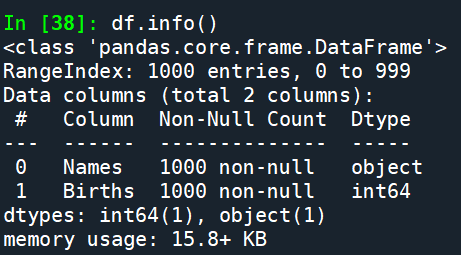
info()查看DataFrame数据信息
df.info()
isinstance()函数检查对象是某个类型
a=5
isinstance(a,int)
Out[2]: True
isinstance可以⽤类型元组,检查对象的类型是否在元组中:
a = 5; b = 4.5
isinstance(a, (int, float))
Out[24]: True
Python 异常处理
捕捉异常可以使用try/except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。如果你不想在异常发生时结束你的程序,只需在try里捕获它。
Pandas库学习
安装和导入
1.安装pandas库:安装Anaconda安装会自带安装;
若未安装Anaconda,使用Python自带的包管理工具pip来安装:pip install pandas。
2.导入pandas库:
import numpy as np # pandas和numpy常常结合在一起使用,导入numpy库
import pandas as pd # 导入pandas库
print(pd.__version__) # 打印pandas版本信息
pandas数据类型pd.series、pd.dataframe
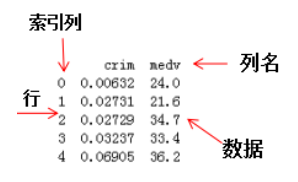
pandas包含两种数据类型:series和dataframe。
series是一种一维数据结构,每一个元素都带有一个索引,与一维数组的含义相似,其中索引可以为数字或字符串。series结构名称

dataframe是一种二维数据结构,数据以表格形式(与excel类似)存储,有对应的行和列。dataframe结构名称:
Pandas基础操作见:D:\personal_file\python\code\pandas_base.py
Pandas函数
import pandas as pd
pd. to_numeric():将参数转换为数字类型
pd.to_numeric(arg, errors='raise', downcast=None)
默认返回dtype为float64或int64, 具体取决于提供的数据。使用downcast参数获取其他dtype。
- arg : 数据
- errors : {'ignore','raise','coerce'},默认为'raise'。如果为‘raise’,则无效的解析将引发异常。如果为 ‘coerce’,则将无效解析设置为NaN。如果为 ‘ignore’,则无效的解析将返回输入
- downcast : {'integer','signed','unsigned','float'},默认为None
import pandas as pd
df = pd.DataFrame({'区域' : ['西安', '太原', '西安', '太原', '郑州', '太原'],
'10月份销售' : ['0.477468', '0.195046', '0.015964', '0.259654', '0.856412', '0.259644'],
'9月份销售' : ['0.347705', '0.151220', '0.895599', '0236547', '0.569841', '0.254784']})
print(df.dtypes)
#将object对象转换成将数字类型
df['10月份销售']=pd.to_numeric(df['10月份销售'],errors='coerce')
df['9月份销售']=pd.to_numeric(df['9月份销售'],errors='coerce')
pd.date_range()创建时间序列
help(pd.date_range)
date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
start:开始时间
end:结束时间
periods:间隔,整数或None。如果你只使用了起始或结束的时间戳,那么就需要使用period来告知一个范围。
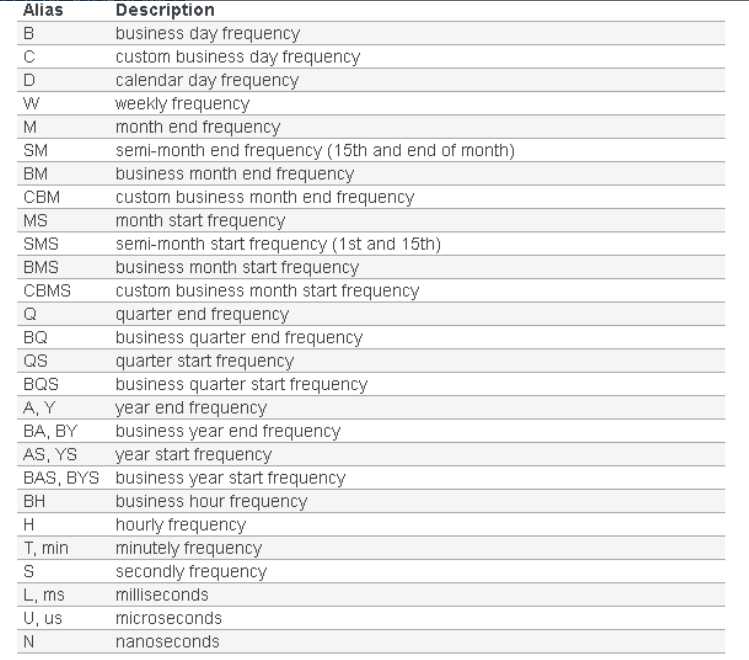
freq:日期偏移量,也就是频率,默认D表示1天。这个是一个非常重要的参数,可以通过设置这个参数得到自定义的时间频率,见图1
closed:closed=None包含开始和结束时间,若closed=‘left’表示取左开右闭的结果,若closed='right'左做闭右开的结果。
normalize:若参数为True表示将start、end参数值正则化到午夜时间戳。
图1:
示例:https://blog.csdn.net/kancy110/article/details/77131539
pd.date_range(start='2017-01-01', end='2017-01-04', closed='right')
pd.date_range(start='20170101',periods=10)
pd.date_range(start='20170101',end='20170110',freq='3D')
pd.date_range(start='2017-01-01 08:10:50',periods=10,freq='s',normalize=True
pd.Timestamp返回时间戳
pd.Timestamp('2013-01-02')

df.dropna()函数:去掉包含缺失值的行
df.fillna()函数:对缺失值进行填充
df.fillna(method="ffill",inplace=True)
inplace参数的取值:True、False
True:直接修改原对象
False:创建一个副本,修改副本,原对象不变(缺省默认)
method参数的取值 : {‘pad’, ‘ffill’,‘backfill’, ‘bfill’, None}, default None
pad/ffill:用前一个非缺失值去填充该缺失值
backfill/bfill:用下一个非缺失值填充该缺失值
None:指定一个值去替换缺失值(缺省默认这种方式)
df.value_counts():统计数据出现的频率
value_counts(ascending=True, normalize=True)
value_counts()返回的结果是一个Series数组,可以跟别的数组进行计算。
1. Series 情况下:
pandas 的 value_counts() 函数可以对Series里面的每个值进行计数并且排序。
import pandas as pd
df = pd.DataFrame({'区域' : ['西安', '太原', '西安', '太原', '郑州', '太原'],
'10月份销售' : ['0.477468', '0.195046', '0.015964', '0.259654', '0.856412', '0.259644'],
'9月份销售' : ['0.347705', '0.151220', '0.895599', '0236547', '0.569841', '0.254784']})
print(df)
统计:
print(df['区域'].value_counts()) #统计每个区域出现多少次,默认从高到低排序
print(df['区域'].value_counts(ascending=True)) #每个区域出现多少次,升序排序
#每个区域出现次数占比
print(df['区域'].value_counts(normalize=True))
resample() 重采样
重新采样是指将时间序列从一个频率转换为另一个频率的过程,将更高频率的数据聚合到低频率被称为向下采样,而从低频率转换为高频率被称为向上采样,但是还有一种是同频之间的切换,比如W-WED(weekly on Wednesday 每周三)转换到W-FRI(每周五)
参数:

freq.resample(rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention='start',
kind=None, loffset=None, limit=None, base=0, on=None, level=None)
https://zhuanlan.zhihu.com/p/70353374
zip() 函数
zip可以将多个列表、元组或其它序列成对组合,并返回这些元组组成的列表;
函数语法:zip([iterable, …]) ->返回元组列表
In [89]: seq1 = ['foo', 'bar', 'baz'] In [90]: seq2 = ['one', 'two', 'three'] In [91]: zipped = zip(seq1, seq2) In [92]: list(zipped)
set_index( )设置索引列
1、函数体及主要参数解释:
- DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
- 参数解释:
- keys:列标签或列标签/数组列表,需要设置为索引的列
- drop:默认为True,删除用作新索引的列
- append:是否将列附加到现有索引,默认为False。
- inplace:输入布尔值,表示当前操作是否对原数据生效,默认为False。
- verify_integrity:检查新索引的副本。否则,请将检查推迟到必要时进行。将其设置为false将提高该方法的性能,默认为false。
reset_index( ) 还原索引
1、函数体及主要参数解释:
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
参数解释:
- level:数值类型可以为:int、str、tuple或list,默认无,仅从索引中删除给定级别。默认情况下移除所有级别。控制了具体要还原的那个等级的索引 。
- drop:当指定drop=False时,则索引列会被还原为普通列;否则,经设置后的新索引值被会丢弃。默认为False。
- inplace:输入布尔值,表示当前操作是否对原数据生效,默认为False。
- col_level:数值类型为int或str,默认值为0,如果列有多个级别,则确定将标签插入到哪个级别。默认情况下,它将插入到第一级。
- col_fill:对象,默认'',如果列有多个级别,则确定其他级别的命名方式。如果没有,则重复索引名。
注意~~~reset_index()还原可分为两种类型,第一种是对原来的数据表进行reset;第二种是对使用过set_index()函数的数据表进行reset
https://zhuanlan.zhihu.com/p/110819220?from_voters_page=true
df.index.get_level_values() 复合索引指定搜索索引级数
pct_change()计算当前元素与先前元素之间的百分比变化
Pandas dataframe.pct_change()函数计算当前元素与先前元素之间的百分比变化。默认计算前一行的百分比变化,计算环比。
注意:此功能在时间序列数据中最有用。
用法: DataFrame.pct_change(periods=1, fill_method=’pad’, limit=None, freq=None, **kwargs)
参数:
periods:形成百分比变化所需的时间。periods=1,与前一行比较
fill_method:在计算百分比变化之前如何处理资产净值。
limit:停止前要填充的连续NA数
freq:时间序列API中使用的增量(例如“ M”或BDay())。
**kwargs:其他关键字参数将传递到DataFrame.shift或Series.shift中。
举例:
#增加一列,表示为每一年比上一年变化的百分比
year['yr_pct_change']=year['max'].pct_change(periods=1)
stack和unstack函数
stack()即“堆叠”,类似将列转行,把列(column)放置到索引位置,会形成多层索引(有点列转行的感觉)
stack()操作后返回的对象是Series类型
unstack()即stack()的反操作,类似将行转列
https://blog.csdn.net/qq_42874547/article/details/89056000
pandas中Series对象下的str方法汇总
pandas的str方法和原生python语法区别:多一个.str
对DataFrame的某一列进行操作,一般都会使用df[“xx”].str下的方法, xx这一列必须是字符串类型,在pandas里面是object
https://blog.csdn.net/weixin_43750377/article/details/107979607
1.one hot 独热编码,get_dummies
series=data['列名'].str.get_dummies(sep=',')
实现DataFrame中列有多值,且想把这列one hot下
2.切分字符串,split()
split(pat=None,n=-1,expand=False)
# 不指定分隔符pat,默认就是一个列表
# 指定n,表示分隔次数,默认是-1,全部分隔
# expand,默认是False,得到是一个列表,如果指定为True,会将列表打开,变成多列,变成DATAFrame
# 列名是按照0 1 2 3····的顺序,并且默认None值分隔后还是为None
举例:
series=data['列名'].str.split(',')
把DataFrame列中字符串以','分隔开,每个元素分开后存入一个列表里。
rsplit(和split用法一致,只不过默认是从右往左分隔)
3.替换,replace()
series=data['列名'].str.replace(',','-')
用‘-’代替‘,’
4.是否包含表达式,contains()
series=data['列名'].str.contains('we')
返回的是布尔值series
5.查找所有符合正则表达式的字符findall()
series=data['列名'].str.findall("[a-z]")
以数组的形式返回
6.计算字符串的长度,len()
series=data['列名'].str.len()
7.去除前后的空白字符,strip()
series=data['列名'].str.strip()
rstrip() 去除后面的空白字符
lstrip() 去除前面的空白字符
8.是否判断 is***
例如:df["attack"].str. isalnum();
isalnum() 是否全部是数字和字母组成
isalpha() 是否全部是字母
isdigit() 是否全部都是数字
isnumeric()是否全部都是数字
isspace() 是否空格
islower() 是否全部小写
isupper() 是否全部大写
istitle() 是否只有首字母为大写,其他字母为小写。
9. get(获取指定位置的字符,只能获取1个)
df["attack"].str.get(3)
# 获取指定索引的字符,只能传入int
10.slice_replace(从名字也能看出来,slice筛选出来之后替换)
df["attack"].str.slice_replace(1,3, "distance")
# 将slice为[1:3]的内容换成"distance",既然替换,所以这里不支持步长。
11.join(将每个字符之间使用指定字符相连,相当于sep.join(list(value)))
df["ultimate"].str.join("a")
12.contains(判断字符串是否含有指定子串,返回的是bool类型)
df["country"].str.contains("国")
# 指定na=False,那么就会变成False了,也可以指定为其他的值,但是类型会变
df["country"].str.contains("国", na=False)
13.startswith(是否某个子串开头)
df["attack"].str.startswith("近")
14. endswith(判断是否以某个子串结尾)
df["attack"].str.endswith("离")
15.match(从头开始匹配的。返回布尔型,表示是否匹配给定的模式)
df["attack"].str.match(".{2}距") # 开头两个字符任意,第三个字符为"距"
16. replace(替换指定的字符)
# 将2011-11-23替换成23/11/2011这种格式
df["date"].str.replace("(\d+)-(\d+)-(\d+)",r"\3/\2/\1")
# 这里面的replace是支持正则的。
# 并且一般我们会加上r表示原生的,这是在正则中
# 对于pandas来说,第一个参数是不需要加的,如match。但是第二个参数是要加上r的
# 尤其是分组替换,但如果只是简单字符串替换就不需要了。
17. repeat(重复字符串)几次
df["date"].str.repeat(3)
18. pad(将每一个元素都用指定的字符填充,只能是一个字符)
# 表示最后字符串要占5个长度,用">"填充,默认填充在左边
df["name"].str.pad(5, fillchar=">")
## 指定side从哪边开始填充,left,right,both
df["name"].str.pad(5, fillchar="<", side="right")
19.zfill(填充,只能是0填充,从左边填充)
df["name"].str.zfill(10)
20. encode decode(字符串编码、解码)
df["attack"].str.encode("utf-8")#编码
df["attack"].str.encode("utf-8").str.decode("utf-8")#解码
21.strip(按照指定内容,从两边去除,和python字符串内置的strip一样)
df["attack"].str.strip("中远近离")
22. translate(指定部分替换)
trans = str.maketrans({"距": "ju", "离": "li"})#距替换成ju,离替换成li
print(df["attack"].str.translate(trans))
23.extract(分组捕获)
# 必须匹配指定pattern,否则为NaN
# 而且必须要有分组,否则报错,结果是一个DataFrame,每一个分组对应一列
df["date"].str.extract("\d{4}-(\d{2})-(\d{2})")
24. find(查找指定字符第一次出现的位置)
df["date"].str.find("-")# 找不到的话,返回-1
python把几个DataFrame合并成一个DataFrame
- concat:可以沿一条轴将多个对象连接到一起
- join:inner是交集,outer是并集。
- merge:可以根据一个或多个键将不同的DataFrame中的行连接起来。
merge行数不变列数增加,相当于左右内连接
merge 函数通过一个或多个键将数据集的行连接起来。默认以相同的列名进行内连接。
场景:针对同一个主键存在的两张包含不同特征的表,通过主键的链接,将两张表进行合并。合并之后,两张表的行数不增加,列数是两张表的列数之和。
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False)
- left:对象DataFrame1
- right:对象DataFrame2
|
参数 |
描述 |
|---|---|
|
how |
数据融合的方法,方式(inner、outer、left、right),默认’inner’ |
|
on |
用来对齐的列名,一定要保证左表和右表存在相同的列名。类似于sql的join key |
|
left_on |
左表对齐的列,可以是列名。也可以是DataFrame同长度的arrays |
|
right_on |
右表对齐的列,可以是列名。 |
|
left_index |
将左表的index用作连接键 |
|
right_index |
将右表的index用作连接键 |
|
suffixes |
左右对象中存在重名列,结果区分的方式,后缀名。 |
|
sort |
通过联接键按字典顺序对结果进行排序,默认值为True,设置为False在许多情况下将极大地提高性能 |
|
copy |
默认:True。将数据复制到数据结构中,设置为False提高性能。 |
1.result = pd.merge(left, right) #默认以相同的键进行内连接
1.result = pd.merge(left, right, on='key')
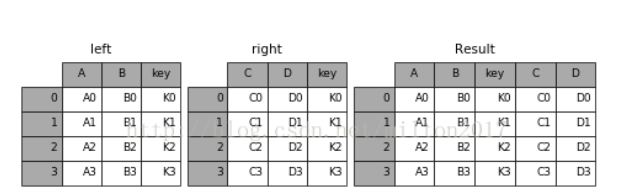
2.result = pd.merge(left, right, on=['key1', 'key2'])
3.result = pd.merge(left, right, how='left', on=['key1', 'key2'])
4.result = pd.merge(left, right, how='right', on=['key1', 'key2'])
示例:
df1 = pd.DataFrame({'key': ['one', 'two', 'three'],
'value': ['a', 'b', 'c'],
'data1': np.arange(3)})
df2 = pd.DataFrame({'key': ['one', 'two', 'three'],
'value': ['a', 'c', 'c'],
'data2': np.arange(3)})
df3 = pd.merge(df1, df2) # 默认以相同的键进行内连接
df4 = pd.merge(df1, df2, how='left') # 左连接,默认以相同名的键进行
df5 = pd.merge(df1, df2, on=['key', 'value'], how='outer')
print(df5)
append:将一行连接到一个DataFrame 上
append只有按行合并,相当于concat按行合并的简写形式
语法:dataframe.append(other, ignore_index)
示例1:
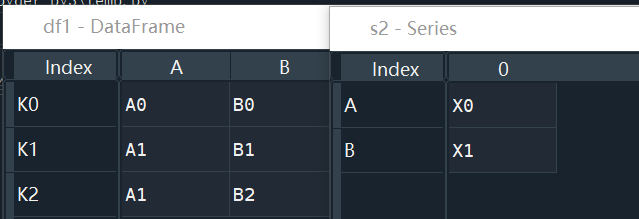
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A1'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
s2 = pd.Series(['X0','X1'], index=['A','B'])
result = df1.append(s2, ignore_index= True)
print(result)
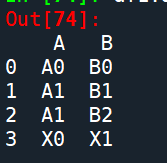
s2先行转列,再按列合并到df1
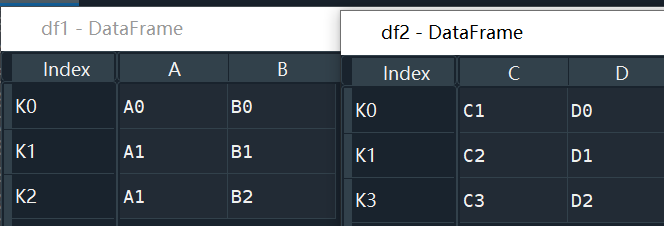
join
join方法将两个DataFrame中不同的列索引合并成为一个DataFrame
参数的意义与merge基本相同,只是join方法默认左外连接how=left
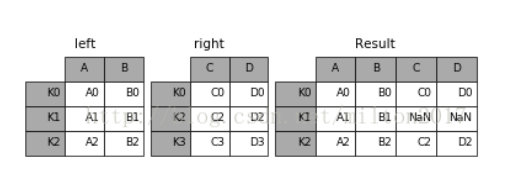
left.join(right, on=key_or_keys)
result = left.join(right, on='key') #左连接
result = left.join(right, on=['key1', 'key2'], how='inner')
示例:
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A1'],
'B': ['B0', 'B1', 'B2']},
index=['K0', 'K1', 'K2'])
df2 = pd.DataFrame({'C': ['C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2']},
index=['K0', 'K1', 'K3'])
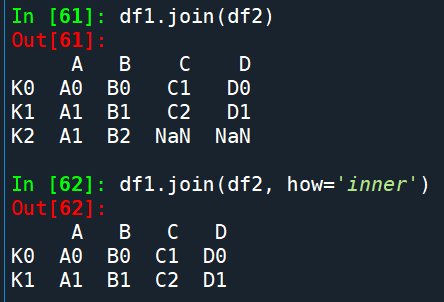
df3 = df1.join(df2) # 默认左连接
df5 = df1.join(df2, how='inner')
concat
指定按某个轴进行连接(axis=0/1),也可以指定join方法。
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False,
copy=True)
说明:
|
属性 |
描述 |
|
objs |
合并的对象集合。可以是Series、DataFrame |
|
axis |
合并方法。默认0纵向按行合并,1横向按列合并 |
|
join |
默认outer并集,inner交集。只有这两种 |
|
join_axes |
按哪些对象的索引保存. 有的版本不存在此参数 |
|
ignore_index |
默认Fasle忽略。是否忽略原index |
|
keys |
为原始DataFrame添加一个键,默认无 |
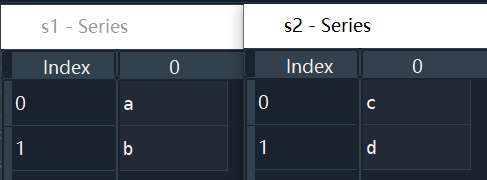
示例1:
s1 = pd.Series(['a', 'b'])
s2 = pd.Series(['c', 'd'])
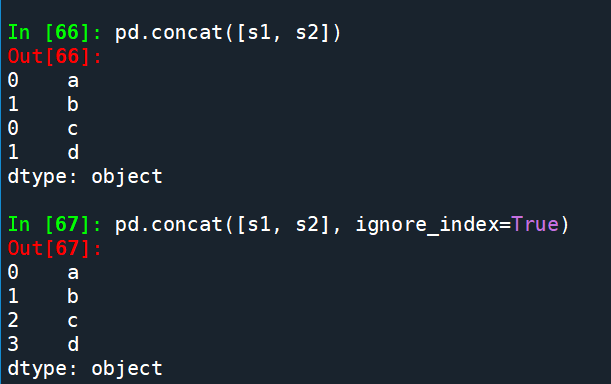
pd.concat([s1, s2])
pd.concat([s1, s2], ignore_index=True) # 忽略原index
Pandas透视表(pivot_table)
#此功能是为了实现自动化报表,解决重复固定格式工作
pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
- index:相当于sql里的group by后面的列,用于分组的列,相当于行索引
- values:相当于sql里的聚合函数操作的列,放在聚合函数里的列。默认聚合是求平均
- aggfunc:相当于sql里的聚合函数,如果不指明,默认求平均.可以接受列表,即对values作不同的聚合,也可以接受字典,即对不同的values作不同的操作,也可以将字典里的值改为列表形式的,即对某列作几种不同的操作.切记,对于aggfunc,操作的是values后面的值,而不是columns后面的值.
- columns:相当于列索引,就是更细化地展示一些内容.
- fill_value:用于填充NAN
- margins:不是简单地求和,而是与 aggfunc 的规则相同,为True时会添加行/列的总计

举例:
df = pd.DataFrame({'区域' : ['西安', '太原', '西安', '太原', '郑州', '太原'],
'10月份销售' : ['0.477468', '0.195046', '0.015964', '0.259654', '0.856412', '0.259644'],
'9月份销售' : ['0.347705', '0.151220', '0.895599', '0236547', '0.569841', '0.254784']})
print(df)
df['10月份销售']=pd.to_numeric(df['10月份销售'],errors='coerce') #将object对象转换成将数字类型
df['9月份销售']=pd.to_numeric(df['9月份销售'],errors='coerce')
pd.pivot_table(df,values=['10月份销售','9月份销售'],index=['区域'])
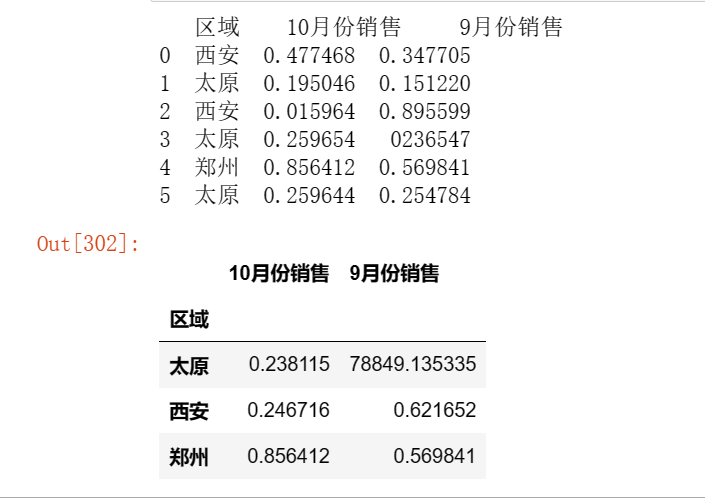
更多参考:https://zhuanlan.zhihu.com/p/127811410
groupby分组
根据表本身的某一列或多列内容进行分组聚合
one =df.groupby('letter').sum()
letterone =df.groupby(['letter','one']).sum()
你可能不想把用来分组的列名字作为索引,像下面的做法很容易实现。
letterone =df.groupby(['letter','one'],as_index=False).sum()
groupby首先要指定分组原则,这也是groupby函数的第一步,其常用参数包括:
- by,分组字段,可以是单(多)列/series/字典/函数,常用为列名
- axis,指定按哪个轴进行分组,默认为0,表示沿着行分组
- as_index,是否将分组列名作为索引,默认为True
- sort,指定是否对输出结果按索引排序
pandas的groupby遵从split、apply、combine模式
NumPy 参考手册
numPy是使用Python进行科学计算的基础软件包。除其他外,它包括:
- 功能强大的N维数组对象。
- 精密广播功能函数。
- 集成 C/C+和Fortran 代码的工具。
- 强大的线性代数、傅立叶变换和随机数功能。
https://www.numpy.org.cn/reference/
numpy里random总结
1) np.random.rand()
np.random.rand(d0, d1, …, dn)
np.random.rand(d0, d1, …, dn):生成一个指定形状的[0, 1)之间均匀分布的随机数数组。注意包含0不包含1。参数d0, d1, …, dn指定了生成的随机数数组的维度。
rand(1) #返回一个一维的一个数字数组,
rand(2) #返回一个一维的2个数字数组,以此类推。
rand(3,4) #返回3行4列的二维数组。
比如
np.random.rand(2)
np.random.rand(2,2)
2)np.random.randn()
np.random.randn(d0, d1, …, dn)
randn()生成一个指定形状的标准正态分布的随机数数组(均值为0,标准差为1)。参数d0, d1, …, dn指定了生成的随机数数组的维度。
用法同np.random.rand()一样
np.random.randn(2,2)
3)np.random.randint()
np.random.randint(low, high=None, size=None, dtype=int)
randint()生成一个指定形状的随机整数数组。返回随机整数,范围区间为[low,high),包含low,不包含high。high没有填写时,默认生成随机数的范围是[0,low)
参数:low为最小值,high为最大值,size为数组维度大小,dtype为数据类型,默认的数据类型是np.int。
np.random.randint(1,size=4) #返回array([0, 0, 0, 0])
np.random.randint(-2,3,size=(2,3))
举例:生成介于0和100之间的随机数
import numpy as np
y3= [np.random.randint(low=0,high=100) for i in range(100)]
print(y3)
4)np.random.random
np.random.random(size=None):与np.random.random_sample方法相同,生成一个指定形状的[0, 1)之间均匀分布的随机数数组。参数size指定了生成的随机数的形状。
通过size参数来指定维数,生成[0,1)之间的浮点数
z1 = np.random.random()
print(z1) #输出:0.5496674667621851
z2 = np.random.random(1)
print(z2) #输出:[0.03831152]
z3 = np.random.random(2) 等价于 np.random.random(size=(1,2))
print(z3) #输出:[0.67638162 0.72296213]
z4 = np.random.random((2,3)) 或者z4 = np.random.random(size=(2,3))
print(z4)
5) numpy.random.RandomState()
可以通过numpy工具包生成模拟数据集,使用RandomState获得随机数生成器
from numpy.random import RandomState
rdm = RandomState(1)
注意:这里1为随机数种子,只要随机数种子seed相同,产生的随机数系列就相同
a = rdm.uniform(1,2,(3,4))
print(a)
np.cumsum()
cumsum()函数是在Python中支持的numpy库的一部分。它可以被用于计算指定轴的数组元素累积和
dates=pd.date_range('20130101',periods=6)
df=pd.DataFrame(np.random.randn(6,4),index=dates,columns=list('ABCD'))
df.cumsum()#按列逐行累加,返回arrary
ndim、shape、dtype、astype的用法
1. ndim返回的是数组的维度,返回的只有一个数,该数即表示数组的维度。
arr=np.array[1,2,3]
arr.ndim
2. shape:表示各位维度大小的元组,返回的是一个元组。
arr.shape
3. dtype:一个用于说明数组数据类型的对象。返回的是该数组的数据类型。
arr.dtype
4. astype:转换的数据类型
arr.astype(int)
绘图包matplotlib.plot()
|
参数 |
说明 |
|---|---|
|
label |
用于图例的标签 |
|
ax |
要在其上进行绘制的matplotlib subplot对象。如果没有设置,则使用当前matplotlib subplot |
|
style |
将要传给matplotlib的风格字符串(for example: ‘ko–’) |
|
alpha |
图表的填充不透明(0-1) |
|
kind |
可以是’line’, ‘bar’, ‘barh’, ‘kde’,point,scatter |
|
logy |
在Y轴上使用对数标尺 |
|
use_index |
将对象的索引用作刻度标签 |
|
rot |
旋转刻度标签(0-360) |
|
xticks |
用作X轴刻度的值 |
|
yticks |
用作Y轴刻度的值 |
|
xlim |
X轴的界限 |
|
ylim |
Y轴的界限 |
|
grid |
显示轴网格线 |
kind参数说明——'line', 'bar', 'barh', 'kde':
- 直方图:是一种可以对值频率离散化显示的柱状图。通过调用Series.hist()方法即可创建。
- 密度图:与直方图相关的一种类型图,是通过计算“可能会产生观测数据的连续概率分布的估计”而产生的,通过给plot传入参数kind = 'kde' 即可。
- 散布图:是观测两个一维数据序列之间关系的有效手段,使用pd.scatter_matrix()即可建立。
遇到报错
1、SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position

解决:
方法1:双斜杠代替单斜杠
pd.read_csv('C:\\Users\\18308\\Desktop\\test.csv')
方法2:前边加个字母r
pd.read_csv(r'C:\\Users\\18308\\Desktop\\test.csv')
方法3:使用Linux的路径/
pd.read_csv('C:/Users/18308/Desktop/test.csv')
2、“xxx”object is not callable的异常
关于“xxx”object is not callable的异常:把一个变量用了函数名来命名,结果再调这个函数的时候就会报这个异常
处理方法,删除或重命名变量


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具