【数据结构&算法】03-复杂度分析之浅析最好、最坏、平均、均摊时间复杂度
前言
主要记录四个复杂度分析知识点:
- 最好情况时间复杂度 (best case time complexity)
- 最坏情况时间复杂度 (worst case time complexity)
- 平均情况时间复杂度 (average case time complexity)
- 均摊时间复杂度 (amortized time complexity)
李柱明博客:https://www.cnblogs.com/lizhuming/p/15487280.html
最好、最坏情况时间复杂度
最好情况时间复杂度就是,在最理想的情况下,执行这段代码的时间复杂度 。
最坏情况时间复杂度就是,在最糟糕的情况下,执行这段代码的时间复杂度 。
例子:在一个链表中找出合适的节点:
- 最好:遍历该链表时,第一个就合适了,那时间复杂度为 O(1)。
- 最坏:遍历该链表时,全遍历了,那时间复杂度就为 O(n)。
平均情况时间复杂度
最好和最坏的情况都是极端的,出现的概率不高。
通用的就算平均情况时间复杂度。
计算方法
把每一种情况的时间复杂度全部加起来再除以情况总数。
若考虑每种情况的概率,那就把每种情况的时间复杂度都乘以当前情况的概率然后再除以情况总数。
分析过程
分析遍历链表这个例子(看到最后)
假设链表长度为 n,情况有 n+1 种:n 种在链表不同位置和一种不在链表中。
按照平均时间复杂度的计算方法得出以下结果:
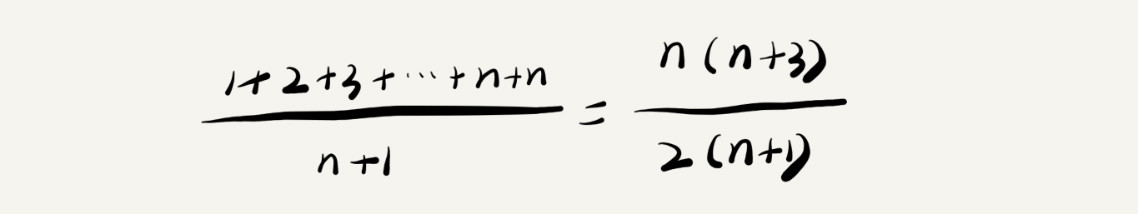
按照大 O 表示法,忽略掉系数、低阶和常量,得出的平均时间复杂度为 O(n)。
上述方法并不是很准确,因为每种情况出现的概率并不一样,若把各种情况发生的概率也考虑进去,分析过程为
假设在数组中与不在数组中的概率都为 1/2。
数据出现在 0~n-1 这 n 个位置的概率也是一样的,为 1/n。
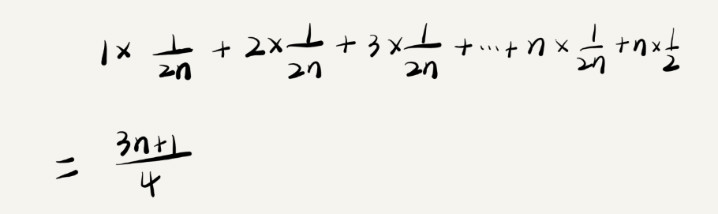
这个值就是概率论中的 加权平均值 ,也叫作 期望值 ,所以平均时间复杂度的全称应该叫加权平均时间复杂度或者 期望时间复杂度 。
使用大 O 表示法,其时间复杂度是 O(n)。
均摊时间复杂度
大部分情况下,我们并不需要区分最好、最坏、平均三种复杂度。
平均复杂度只在某些特殊情况下才会用到,而均摊时间复杂度应用的场景比它更加特殊、更加有限。
例子
// array 表示一个长度为 n 的数组
// 代码中的 array.length 就等于 n
int[] array = new int[n];
int count = 0;
void insert(int val)
{
if (count == array.length)
{
int sum = 0;
for (int i = 0; i < array.length; ++i)
{
sum = sum + array[i];
}
array[0] = sum;
count = 1;
}
array[count] = val;
++count;
}
通过代码分析得:
-
功能:把所有传入的数值求和保存到
array[0]- 把 val 值保存到 array 数组中。
- 当数组放满以后,把数组 array 中已使用空间的各值总和保存到
array[0],然后重新开始。
该函数的时间复杂度分析
-
最好:O(1):
- 在 array 数组还有可用空间时。
-
最坏:O(n):
- 在 array 数组没有可用空间时。
-
平均:O(1):
- 每种情况的概率出现都一样,即是不用考虑概率论。
- 未满时每种情况的时间复杂度为 O(1);共 n 种。
- 满时情况的时间复杂度为 O(n);共 1 种。
- (O(1)*n+O(n)) /(n+1)= O(1)
-
均摊:O(1):
- 由于这个例子的各种情况的出现是有规律的:n-1 次 O(1) 后会出现一次 O(n) 。按照这种情况,可以把这一次 O(n) 均摊到前面的 n-1 次中,即是每种情况都加上 O(n)/(n-1) = O(1) 。
均摊的应用场景
由于只有在特殊的情况下才使用到均摊,所以列出一些常用的场景即可。如下:
对一个数据结构进行一组连续操作中,大部分情况下时间复杂度都很低,只有个别情况下时间复杂度比较高,而且这些操作之间存在前后连贯的时序关系。
这个时候,我们就可以将这一组操作放在一块儿分析,看是否能将较高时间复杂度那次操作的耗时,平摊到其他那些时间复杂度比较低的操作上。
在能够应用均摊时间复杂度分析的场合,一般均摊时间复杂度就等于最好情况时间复杂度。


· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 使用C#创建一个MCP客户端
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 按钮权限的设计及实现