
使用python基本库代码实现神经网络常见层
1、卷积层(Convolutional Layer)是卷积神经网络(CNN)的核心组件,用于提取输入数据中的局部特征。下面是用Python基础库实现一个简单的二维卷积层的示例代码:


import numpy as np # 定义输入数据和卷积核 input_data = np.array([[1, 2, 3, 0], [4, 5, 6, 0], [7, 8, 9, 0]]) kernel = np.array([[1, 0, -1], [1, 0, -1], [1, 0, -1]]) # 获取输入数据和卷积核的大小 input_height, input_width = input_data.shape kernel_height, kernel_width = kernel.shape # 计算输出大小 output_height = input_height - kernel_height + 1 output_width = input_width - kernel_width + 1 # 初始化输出矩阵 output = np.zeros((output_height, output_width)) # 进行卷积运算 for i in range(output_height): for j in range(output_width): output[i, j] = np.sum(input_data[i:i+kernel_height, j:j+kernel_width] * kernel) # 打印输出矩阵 print("卷积运算结果:") print(output)
pytorch代码如下
import torch import torch.nn.functional as F # 定义输入数据和卷积核 input_data = torch.tensor([[1, 2, 3, 0], [4, 5, 6, 0], [7, 8, 9, 0]], dtype=torch.float32).unsqueeze(0).unsqueeze(0) kernel = torch.tensor([[1, 0, -1], [1, 0, -1], [1, 0, -1]], dtype=torch.float32).unsqueeze(0).unsqueeze(0) # 进行卷积运算 output = F.conv2d(input_data, kernel) # 打印输出矩阵 print("卷积运算结果:") print(output.squeeze().numpy())

逐元素乘积并求和运算过程

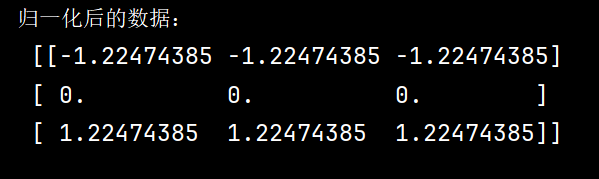
2、批量归一化(Batch Normalization)是一种用于神经网络的正则化技术,可以加速训练过程并提高模型性能。以下是用Python基本库实现批量归一化的代码
import numpy as np # 批量归一化函数 def batch_norm(X, gamma, beta, epsilon=1e-5): """ 实现批量归一化 参数: X : 输入数据,形状为(N, D),其中N是批量大小,D是特征维度 gamma : 缩放参数,形状为(1, D) beta : 平移参数,形状为(1, D) epsilon : 一个小常数,防止除零错误 返回: normalized_X : 归一化后的数据,形状与X相同 """ # 计算批量均值 mean = np.mean(X, axis=0) # 计算批量方差 variance = np.var(X, axis=0) # 对输入数据进行归一化处理 X_normalized = (X - mean) / np.sqrt(variance + epsilon) # 进行缩放和平移变换 normalized_X = gamma * X_normalized + beta return normalized_X # 示例数据 X = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 缩放参数(通常初始化为1) gamma = np.ones((1, X.shape[1])) # 平移参数(通常初始化为0) beta = np.zeros((1, X.shape[1])) # 调用批量归一化函数 normalized_X = batch_norm(X, gamma, beta) print("归一化后的数据:\n", normalized_X)


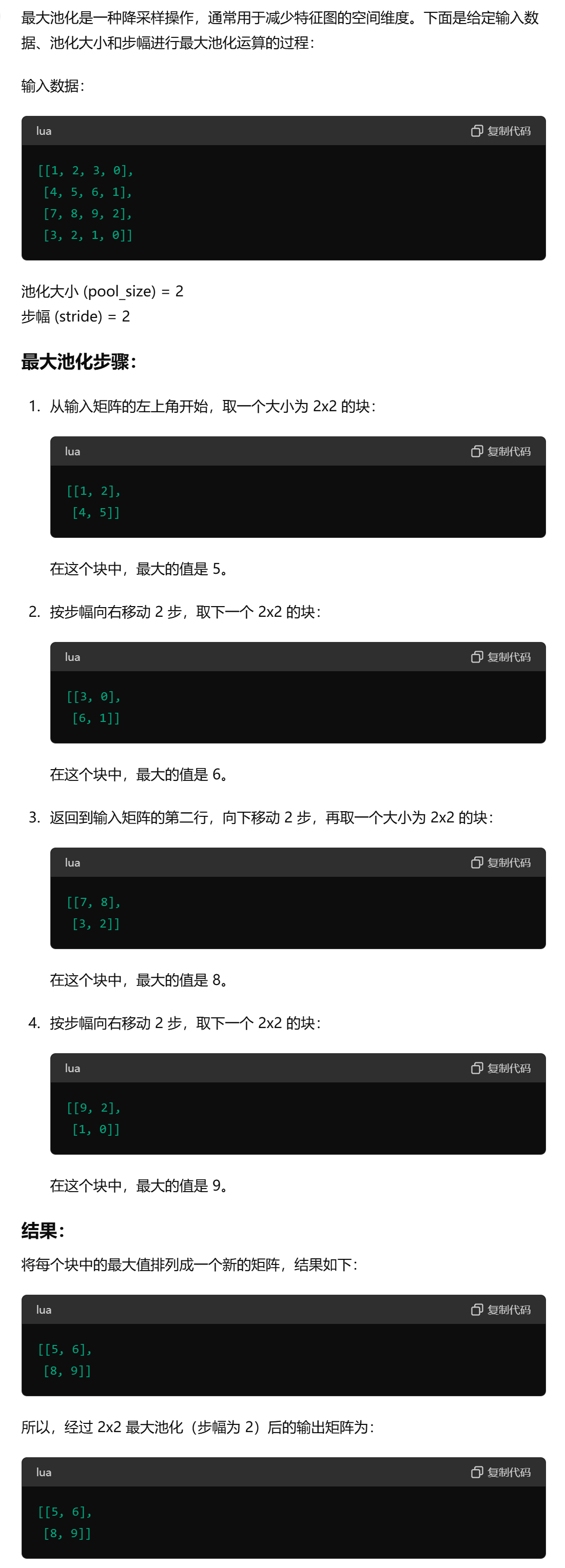
3、最大池化(Max Pooling)是一种下采样操作,用于减少输入的空间维度,从而减少计算量和防止过拟合。下面是一个用Python基础库实现最大池化层的示例代码:
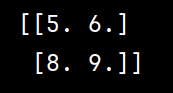
import numpy as np def max_pooling(input_matrix, pool_size, stride): """ 实现最大池化操作。 参数: - input_matrix: 2D numpy array,输入矩阵。 - pool_size: int,池化窗口的大小。 - stride: int,池化步长。 返回: - output_matrix: 2D numpy array,池化后的矩阵。 """ # 获取输入矩阵的维度 input_height, input_width = input_matrix.shape # 计算输出矩阵的维度 output_height = (input_height - pool_size) // stride + 1 output_width = (input_width - pool_size) // stride + 1 # 初始化输出矩阵 output_matrix = np.zeros((output_height, output_width)) # 执行最大池化操作 for i in range(0, output_height): for j in range(0, output_width): # 计算池化窗口的起始位置 start_i = i * stride start_j = j * stride # 获取池化窗口内的子矩阵 pool_region = input_matrix[start_i:start_i + pool_size, start_j:start_j + pool_size] # 计算池化窗口内的最大值 output_matrix[i, j] = np.max(pool_region) return output_matrix # 示例 input_matrix = np.array([[1, 2, 3, 0], [4, 5, 6, 1], [7, 8, 9, 2], [3, 2, 1, 0]]) pool_size = 2 stride = 2 output_matrix = max_pooling(input_matrix, pool_size, stride) print(output_matrix)
4、全连接层(Fully Connected Layer,也称为密集层)是神经网络中最常见的一种层,它将每个输入节点与每个输出节点相连接。下面是用Python基础库实现一个全连接层的示例代码:
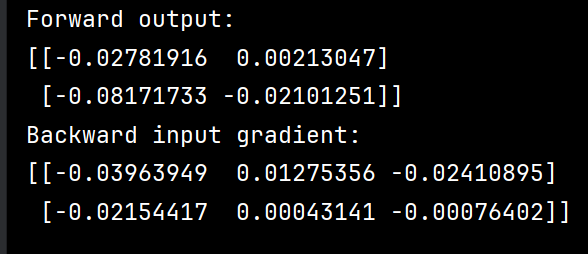
import numpy as np class FullyConnectedLayer: def __init__(self, input_size, output_size): """ 初始化全连接层。 参数: - input_size: int,输入特征的数量。 - output_size: int,输出节点的数量。 """ # 初始化权重矩阵和偏置向量 self.weights = np.random.randn(input_size, output_size) * 0.01 self.biases = np.zeros((1, output_size)) def forward(self, input_data): """ 前向传播。 参数: - input_data: 2D numpy array,输入数据,形状为 (batch_size, input_size)。 返回: - output_data: 2D numpy array,输出数据,形状为 (batch_size, output_size)。 """ self.input_data = input_data self.output_data = np.dot(input_data, self.weights) + self.biases return self.output_data def backward(self, output_gradient, learning_rate): """ 反向传播。 参数: - output_gradient: 2D numpy array,输出梯度,形状为 (batch_size, output_size)。 - learning_rate: float,学习率。 """ # 计算输入梯度、权重梯度和偏置梯度 input_gradient = np.dot(output_gradient, self.weights.T) weights_gradient = np.dot(self.input_data.T, output_gradient) biases_gradient = np.sum(output_gradient, axis=0, keepdims=True) # 更新权重和偏置 self.weights -= learning_rate * weights_gradient self.biases -= learning_rate * biases_gradient return input_gradient # 示例 input_data = np.array([[1, 2, 3], [4, 5, 6]]) # 形状为 (2, 3),即 batch_size = 2, input_size = 3 fc_layer = FullyConnectedLayer(input_size=3, output_size=2) # 输出节点数量为 2 # 前向传播 output_data = fc_layer.forward(input_data) print("Forward output:") print(output_data) # 假设输出梯度为随机值 output_gradient = np.random.randn(2, 2) # 反向传播 input_gradient = fc_layer.backward(output_gradient, learning_rate=0.01) print("Backward input gradient:") print(input_gradient)

5、Dropout 是一种正则化技术,用于防止神经网络过拟合。在训练期间,Dropout 层随机将一部分输入单元设为零,模拟网络的子集进行训练。在测试期间,Dropout 层会将所有单元的输出按比例缩放。以下是用 Python 基础库实现 Dropout 层的示例代码:
import numpy as np class DropoutLayer: def __init__(self, dropout_rate): """ 初始化 Dropout 层。 参数: - dropout_rate: float,丢弃的概率。 """ self.dropout_rate = dropout_rate self.mask = None def forward(self, input_data, training=True): """ 前向传播。 参数: - input_data: 2D numpy array,输入数据。 - training: bool,指示当前是否为训练模式。 返回: - output_data: 2D numpy array,输出数据。 """ if training: # 创建掩码,随机选择部分单元丢弃 self.mask = (np.random.rand(*input_data.shape) >= self.dropout_rate).astype(np.float32) output_data = input_data * self.mask / (1 - self.dropout_rate) else: output_data = input_data return output_data def backward(self, output_gradient): """ 反向传播。 参数: - output_gradient: 2D numpy array,输出梯度。 返回: - input_gradient: 2D numpy array,输入梯度。 """ input_gradient = output_gradient * self.mask / (1 - self.dropout_rate) return input_gradient # 示例 input_data = np.array([[1, 2, 3], [4, 5, 6]], dtype=np.float32) # 输入数据 dropout_layer = DropoutLayer(dropout_rate=0.5) # Dropout 概率为 50% # 训练模式下的前向传播 output_data_train = dropout_layer.forward(input_data, training=True) print("Training forward output:") print(output_data_train) # 反向传播 output_gradient = np.random.randn(2, 3).astype(np.float32) # 随机输出梯度 input_gradient = dropout_layer.backward(output_gradient) print("Backward input gradient:") print(input_gradient) # 测试模式下的前向传播 output_data_test = dropout_layer.forward(input_data, training=False) print("Test forward output:") print(output_data_test)

